 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Shrinkage Pyramid for Camouflaged Object Detection with Transformers
Mar 26, 2023



Vision transformers have recently shown strong global context modeling capabilities in camouflaged object detection. However, they suffer from two major limitations: less effective locality modeling and insufficient feature aggregation in decoders, which are not conducive to camouflaged object detection that explores subtle cues from indistinguishable backgrounds. To address these issues, in this paper, we propose a novel transformer-based Feature Shrinkage Pyramid Network (FSPNet), which aims to hierarchically decode locality-enhanced neighboring transformer features through progressive shrinking for camouflaged object detection. Specifically, we propose a nonlocal token enhancement module (NL-TEM) that employs the non-local mechanism to interact neighboring tokens and explore graph-based high-order relations within tokens to enhance local representations of transformers. Moreover, we design a feature shrinkage decoder (FSD) with adjacent interaction modules (AIM), which progressively aggregates adjacent transformer features through a layer-bylayer shrinkage pyramid to accumulate imperceptible but effective cues as much as possible for object information decoding. Extensive quantitative and qualitative experiments demonstrate that the proposed model significantly outperforms the existing 24 competitors on three challenging COD benchmark datasets under six widely-used evaluation metrics. Our code is publicly available at https://github.com/ZhouHuang23/FSPNet.
Scribble-based Boundary-aware Network for Weakly Supervised Salient Object Detection in Remote Sensing Images
Feb 07, 2022
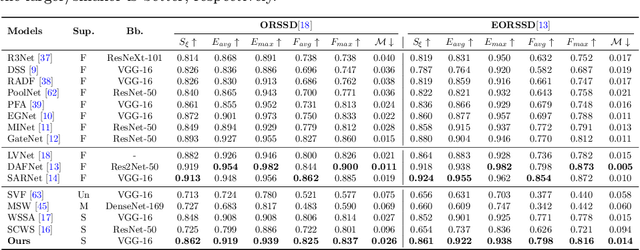
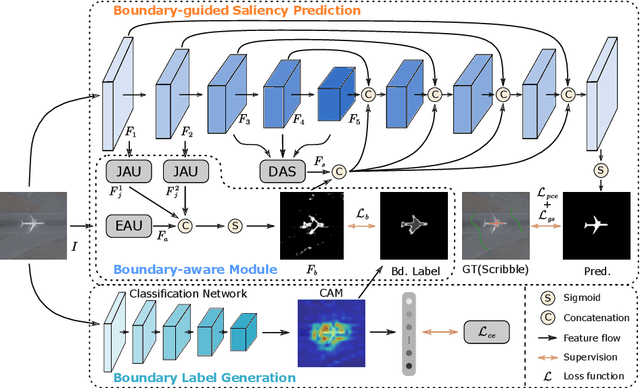
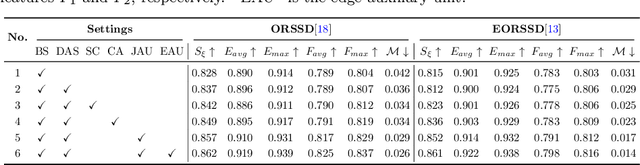
Existing CNNs-based salient object detection (SOD) heavily depends on the large-scale pixel-level annotations, which is labor-intensive, time-consuming, and expensive. By contrast, the sparse annotations become appealing to the salient object detection community. However, few efforts are devoted to learning salient object detection from sparse annotations, especially in the remote sensing field. In addition, the sparse annotation usually contains scanty information, which makes it challenging to train a well-performing model, resulting in its performance largely lagging behind the fully-supervised models. Although some SOD methods adopt some prior cues to improve the detection performance, they usually lack targeted discrimination of object boundaries and thus provide saliency maps with poor boundary localization. To this end, in this paper, we propose a novel weakly-supervised salient object detection framework to predict the saliency of remote sensing images from sparse scribble annotations. To implement it, we first construct the scribble-based remote sensing saliency dataset by relabelling an existing large-scale SOD dataset with scribbles, namely S-EOR dataset. After that, we present a novel scribble-based boundary-aware network (SBA-Net) for remote sensing salient object detection. Specifically, we design a boundary-aware module (BAM) to explore the object boundary semantics, which is explicitly supervised by the high-confidence object boundary (pseudo) labels generated by the boundary label generation (BLG) module, forcing the model to learn features that highlight the object structure and thus boosting the boundary localization of objects. Then, the boundary semantics are integrated with high-level features to guide the salient object detection under the supervision of scribble labels.
Detecting the Saliency of Remote Sensing Images Based on Sparse Representation of Contrast-weighted Atoms
Apr 06, 2020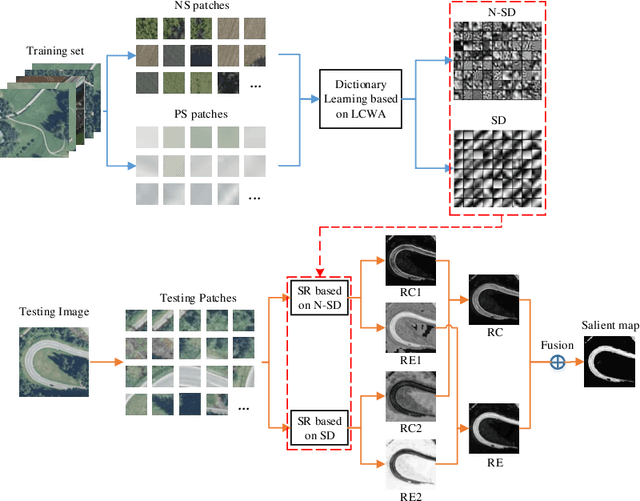


Object detection is an important task in remote sensing (RS) image analysis. To reduce the computational complexity of redundant information and improve the efficiency of image processing, visual saliency models are gradually being applied in this field. In this paper, a novel saliency detection method is proposed by exploring the sparse representation (SR) of, based on learning, contrast-weighted atoms (LCWA). Specifically, this paper uses the proposed LCWA atom learning formula on positive and negative samples to construct a saliency dictionary, and on nonsaliency atoms to construct a discriminant dictionary. An online discriminant dictionary learning algorithm is proposed to solve the atom learning formula. Then, we measure saliency by combining the coefficients of SR and reconstruction errors. Furthermore, under the proposed joint saliency measure, a variety of salient maps are generated by the discriminant dictionary. Finally, a fusion method based on global gradient optimisation is proposed to integrate multiple salient maps. Experimental results show that the proposed method significantly outperforms current state-of-the-art methods under six evaluation measures.