 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistory-Enhanced Two-Stage Transformer for Aerial Vision-and-Language Navigation
Dec 17, 2025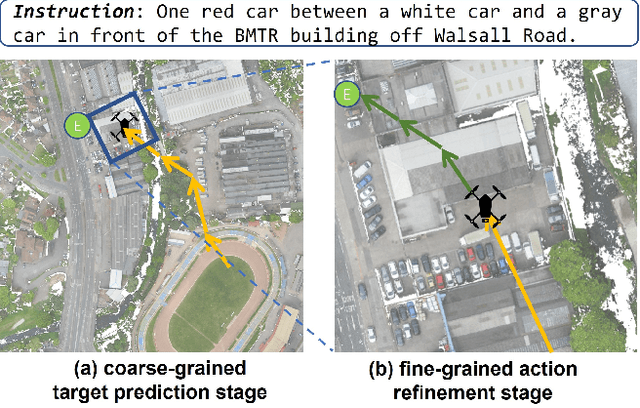

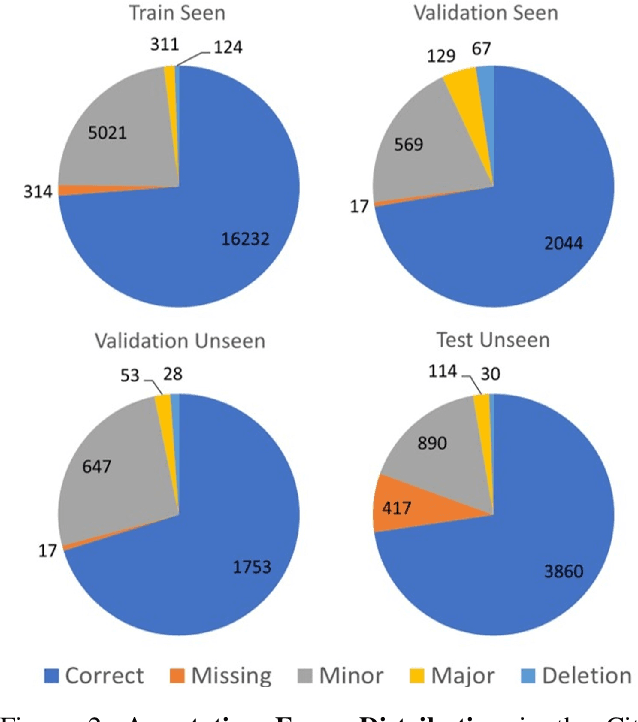

Aerial Vision-and-Language Navigation (AVLN) requires Unmanned Aerial Vehicle (UAV) agents to localize targets in large-scale urban environments based on linguistic instructions. While successful navigation demands both global environmental reasoning and local scene comprehension, existing UAV agents typically adopt mono-granularity frameworks that struggle to balance these two aspects. To address this limitation, this work proposes a History-Enhanced Two-Stage Transformer (HETT) framework, which integrates the two aspects through a coarse-to-fine navigation pipeline. Specifically, HETT first predicts coarse-grained target positions by fusing spatial landmarks and historical context, then refines actions via fine-grained visual analysis. In addition, a historical grid map is designed to dynamically aggregate visual features into a structured spatial memory, enhancing comprehensive scene awareness. Additionally, the CityNav dataset annotations are manually refined to enhance data quality. Experiments on the refined CityNav dataset show that HETT delivers significant performance gains, while extensive ablation studies further verify the effectiveness of each component.
STAR: STacked AutoRegressive Scheme for Unified Multimodal Learning
Dec 15, 2025
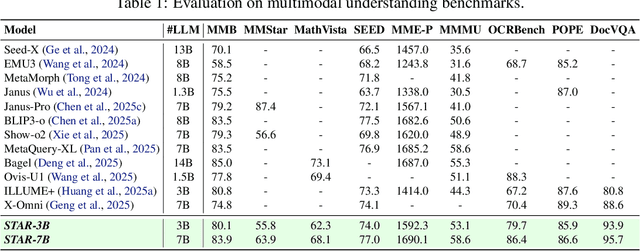
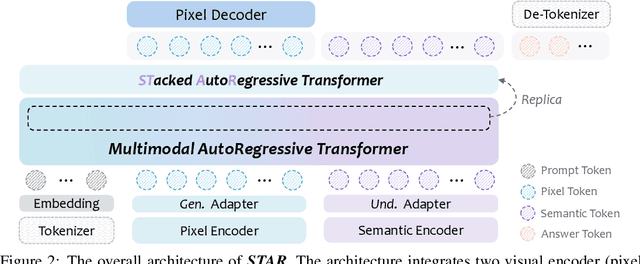
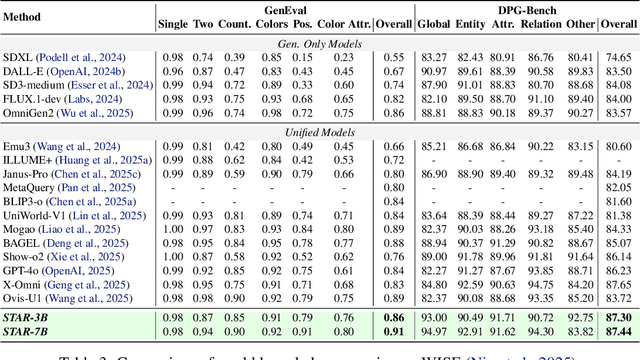
Multimodal large language models (MLLMs) play a pivotal role in advancing the quest for general artificial intelligence. However, achieving unified target for multimodal understanding and generation remains challenging due to optimization conflicts and performance trade-offs. To effectively enhance generative performance while preserving existing comprehension capabilities, we introduce STAR: a STacked AutoRegressive scheme for task-progressive unified multimodal learning. This approach decomposes multimodal learning into multiple stages: understanding, generation, and editing. By freezing the parameters of the fundamental autoregressive (AR) model and progressively stacking isomorphic AR modules, it avoids cross-task interference while expanding the model's capabilities. Concurrently, we introduce a high-capacity VQ to enhance the granularity of image representations and employ an implicit reasoning mechanism to improve generation quality under complex conditions. Experiments demonstrate that STAR achieves state-of-the-art performance on GenEval (0.91), DPG-Bench (87.44), and ImgEdit (4.34), validating its efficacy for unified multimodal learning.
LoFA: Learning to Predict Personalized Priors for Fast Adaptation of Visual Generative Models
Dec 09, 2025Personalizing visual generative models to meet specific user needs has gained increasing attention, yet current methods like Low-Rank Adaptation (LoRA) remain impractical due to their demand for task-specific data and lengthy optimization. While a few hypernetwork-based approaches attempt to predict adaptation weights directly, they struggle to map fine-grained user prompts to complex LoRA distributions, limiting their practical applicability. To bridge this gap, we propose LoFA, a general framework that efficiently predicts personalized priors for fast model adaptation. We first identify a key property of LoRA: structured distribution patterns emerge in the relative changes between LoRA and base model parameters. Building on this, we design a two-stage hypernetwork: first predicting relative distribution patterns that capture key adaptation regions, then using these to guide final LoRA weight prediction. Extensive experiments demonstrate that our method consistently predicts high-quality personalized priors within seconds, across multiple tasks and user prompts, even outperforming conventional LoRA that requires hours of processing. Project page: https://jaeger416.github.io/lofa/.
MoniTor: Exploiting Large Language Models with Instruction for Online Video Anomaly Detection
Oct 24, 2025Video Anomaly Detection (VAD) aims to locate unusual activities or behaviors within videos. Recently, offline VAD has garnered substantial research attention, which has been invigorated by the progress in large language models (LLMs) and vision-language models (VLMs), offering the potential for a more nuanced understanding of anomalies. However, online VAD has seldom received attention due to real-time constraints and computational intensity. In this paper, we introduce a novel Memory-based online scoring queue scheme for Training-free VAD (MoniTor), to address the inherent complexities in online VAD. Specifically, MoniTor applies a streaming input to VLMs, leveraging the capabilities of pre-trained large-scale models. To capture temporal dependencies more effectively, we incorporate a novel prediction mechanism inspired by Long Short-Term Memory (LSTM) networks. This ensures the model can effectively model past states and leverage previous predictions to identify anomalous behaviors. Thereby, it better understands the current frame. Moreover, we design a scoring queue and an anomaly prior to dynamically store recent scores and cover all anomalies in the monitoring scenario, providing guidance for LLMs to distinguish between normal and abnormal behaviors over time. We evaluate MoniTor on two large datasets (i.e., UCF-Crime and XD-Violence) containing various surveillance and real-world scenarios. The results demonstrate that MoniTor outperforms state-of-the-art methods and is competitive with weakly supervised methods without training. Code is available at https://github.com/YsTvT/MoniTor.
Perceiving and Acting in First-Person: A Dataset and Benchmark for Egocentric Human-Object-Human Interactions
Aug 06, 2025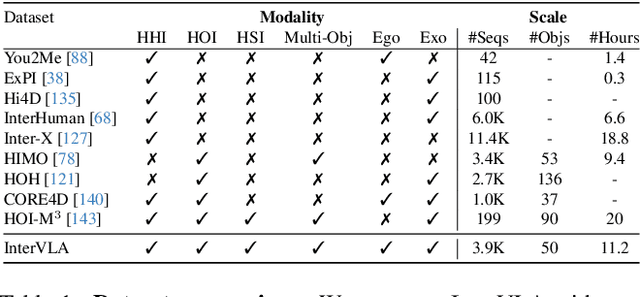

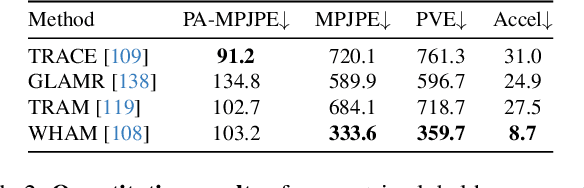

Learning action models from real-world human-centric interaction datasets is important towards building general-purpose intelligent assistants with efficiency. However, most existing datasets only offer specialist interaction category and ignore that AI assistants perceive and act based on first-person acquisition. We urge that both the generalist interaction knowledge and egocentric modality are indispensable. In this paper, we embed the manual-assisted task into a vision-language-action framework, where the assistant provides services to the instructor following egocentric vision and commands. With our hybrid RGB-MoCap system, pairs of assistants and instructors engage with multiple objects and the scene following GPT-generated scripts. Under this setting, we accomplish InterVLA, the first large-scale human-object-human interaction dataset with 11.4 hours and 1.2M frames of multimodal data, spanning 2 egocentric and 5 exocentric videos, accurate human/object motions and verbal commands. Furthermore, we establish novel benchmarks on egocentric human motion estimation, interaction synthesis, and interaction prediction with comprehensive analysis. We believe that our InterVLA testbed and the benchmarks will foster future works on building AI agents in the physical world.
HiM2SAM: Enhancing SAM2 with Hierarchical Motion Estimation and Memory Optimization towards Long-term Tracking
Jul 10, 2025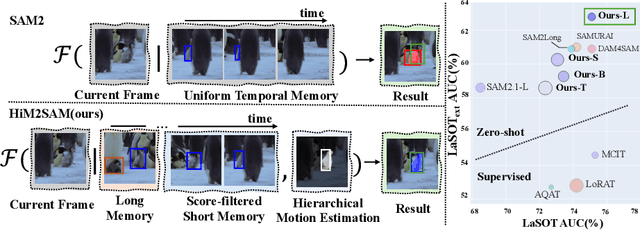
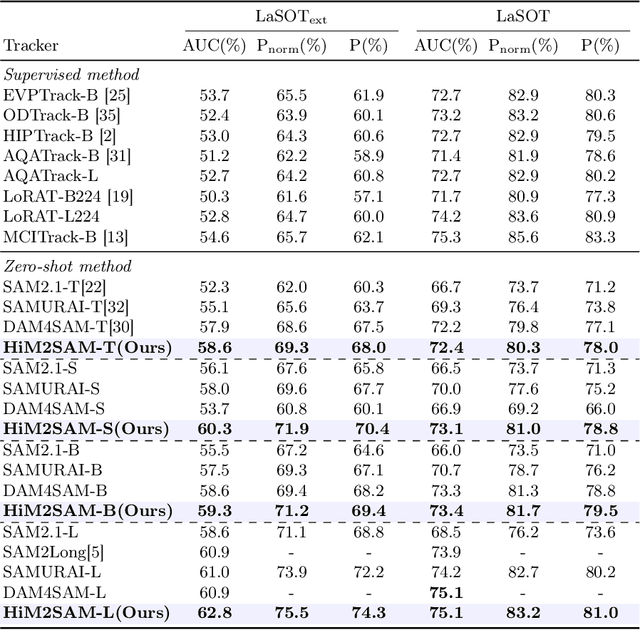
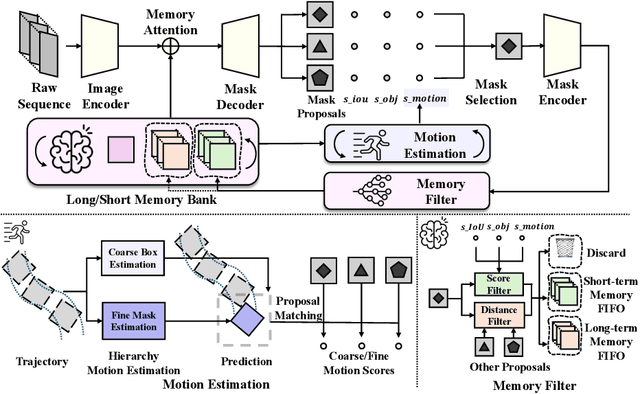
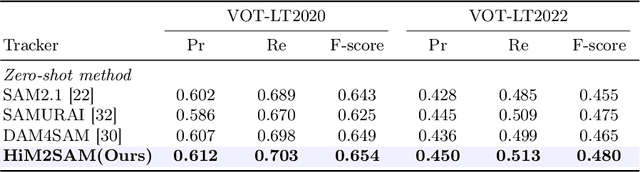
This paper presents enhancements to the SAM2 framework for video object tracking task, addressing challenges such as occlusions, background clutter, and target reappearance. We introduce a hierarchical motion estimation strategy, combining lightweight linear prediction with selective non-linear refinement to improve tracking accuracy without requiring additional training. In addition, we optimize the memory bank by distinguishing long-term and short-term memory frames, enabling more reliable tracking under long-term occlusions and appearance changes. Experimental results show consistent improvements across different model scales. Our method achieves state-of-the-art performance on LaSOT and LaSOText with the large model, achieving 9.6% and 7.2% relative improvements in AUC over the original SAM2, and demonstrates even larger relative gains on smaller models, highlighting the effectiveness of our trainless, low-overhead improvements for boosting long-term tracking performance. The code is available at https://github.com/LouisFinner/HiM2SAM.
Uncertainty Guided Refinement for Fine-Grained Salient Object Detection
Apr 13, 2025



Recently, salient object detection (SOD) methods have achieved impressive performance. However, salient regions predicted by existing methods usually contain unsaturated regions and shadows, which limits the model for reliable fine-grained predictions. To address this, we introduce the uncertainty guidance learning approach to SOD, intended to enhance the model's perception of uncertain regions. Specifically, we design a novel Uncertainty Guided Refinement Attention Network (UGRAN), which incorporates three important components, i.e., the Multilevel Interaction Attention (MIA) module, the Scale Spatial-Consistent Attention (SSCA) module, and the Uncertainty Refinement Attention (URA) module. Unlike conventional methods dedicated to enhancing features, the proposed MIA facilitates the interaction and perception of multilevel features, leveraging the complementary characteristics among multilevel features. Then, through the proposed SSCA, the salient information across diverse scales within the aggregated features can be integrated more comprehensively and integrally. In the subsequent steps, we utilize the uncertainty map generated from the saliency prediction map to enhance the model's perception capability of uncertain regions, generating a highly-saturated fine-grained saliency prediction map. Additionally, we devise an adaptive dynamic partition (ADP) mechanism to minimize the computational overhead of the URA module and improve the utilization of uncertainty guidance. Experiments on seven benchmark datasets demonstrate the superiority of the proposed UGRAN over the state-of-the-art methodologies. Codes will be released at https://github.com/I2-Multimedia-Lab/UGRAN.
Uni4D: A Unified Self-Supervised Learning Framework for Point Cloud Videos
Apr 07, 2025
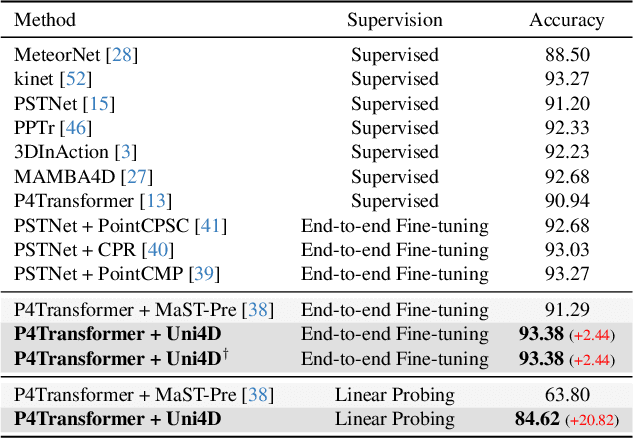
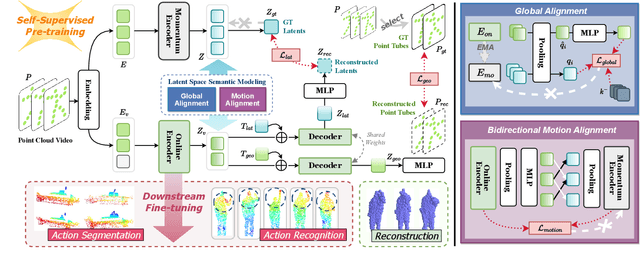

Point cloud video representation learning is primarily built upon the masking strategy in a self-supervised manner. However, the progress is slow due to several significant challenges: (1) existing methods learn the motion particularly with hand-crafted designs, leading to unsatisfactory motion patterns during pre-training which are non-transferable on fine-tuning scenarios. (2) previous Masked AutoEncoder (MAE) frameworks are limited in resolving the huge representation gap inherent in 4D data. In this study, we introduce the first self-disentangled MAE for learning discriminative 4D representations in the pre-training stage. To address the first challenge, we propose to model the motion representation in a latent space. The second issue is resolved by introducing the latent tokens along with the typical geometry tokens to disentangle high-level and low-level features during decoding. Extensive experiments on MSR-Action3D, NTU-RGBD, HOI4D, NvGesture, and SHREC'17 verify this self-disentangled learning framework. We demonstrate that it can boost the fine-tuning performance on all 4D tasks, which we term Uni4D. Our pre-trained model presents discriminative and meaningful 4D representations, particularly benefits processing long videos, as Uni4D gets $+3.8\%$ segmentation accuracy on HOI4D, significantly outperforming either self-supervised or fully-supervised methods after end-to-end fine-tuning.
UniViTAR: Unified Vision Transformer with Native Resolution
Apr 02, 2025Conventional Vision Transformer simplifies visual modeling by standardizing input resolutions, often disregarding the variability of natural visual data and compromising spatial-contextual fidelity. While preliminary explorations have superficially investigated native resolution modeling, existing approaches still lack systematic analysis from a visual representation perspective. To bridge this gap, we introduce UniViTAR, a family of homogeneous vision foundation models tailored for unified visual modality and native resolution scenario in the era of multimodal. Our framework first conducts architectural upgrades to the vanilla paradigm by integrating multiple advanced components. Building upon these improvements, a progressive training paradigm is introduced, which strategically combines two core mechanisms: (1) resolution curriculum learning, transitioning from fixed-resolution pretraining to native resolution tuning, thereby leveraging ViT's inherent adaptability to variable-length sequences, and (2) visual modality adaptation via inter-batch image-video switching, which balances computational efficiency with enhanced temporal reasoning. In parallel, a hybrid training framework further synergizes sigmoid-based contrastive loss with feature distillation from a frozen teacher model, thereby accelerating early-stage convergence. Finally, trained exclusively on public datasets, externsive experiments across multiple model scales from 0.3B to 1B demonstrate its effectiveness.
WPS-SAM: Towards Weakly-Supervised Part Segmentation with Foundation Models
Jul 14, 2024



Segmenting and recognizing diverse object parts is crucial in computer vision and robotics. Despite significant progress in object segmentation, part-level segmentation remains underexplored due to complex boundaries and scarce annotated data. To address this, we propose a novel Weakly-supervised Part Segmentation (WPS) setting and an approach called WPS-SAM, built on the large-scale pre-trained vision foundation model, Segment Anything Model (SAM). WPS-SAM is an end-to-end framework designed to extract prompt tokens directly from images and perform pixel-level segmentation of part regions. During its training phase, it only uses weakly supervised labels in the form of bounding boxes or points. Extensive experiments demonstrate that, through exploiting the rich knowledge embedded in pre-trained foundation models, WPS-SAM outperforms other segmentation models trained with pixel-level strong annotations. Specifically, WPS-SAM achieves 68.93% mIOU and 79.53% mACC on the PartImageNet dataset, surpassing state-of-the-art fully supervised methods by approximately 4% in terms of mIOU.