 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSMix: Distortion-Induced Sensitivity Map Based Pre-training for No-Reference Image Quality Assessment
Jul 04, 2024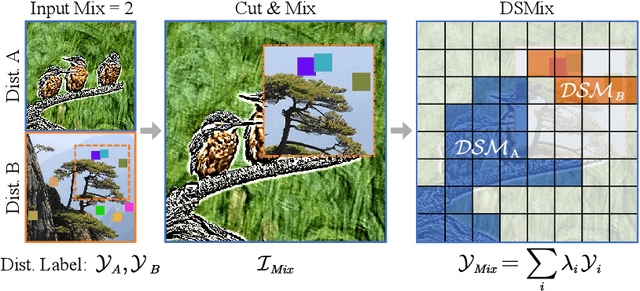
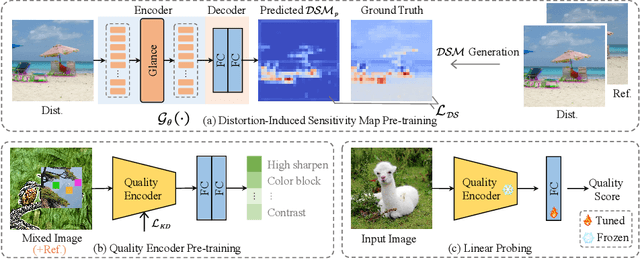

Image quality assessment (IQA) has long been a fundamental challenge in image understanding. In recent years, deep learning-based IQA methods have shown promising performance. However, the lack of large amounts of labeled data in the IQA field has hindered further advancements in these methods. This paper introduces DSMix, a novel data augmentation technique specifically designed for IQA tasks, aiming to overcome this limitation. DSMix leverages the distortion-induced sensitivity map (DSM) of an image as prior knowledge. It applies cut and mix operations to diverse categories of synthetic distorted images, assigning confidence scores to class labels based on the aforementioned prior knowledge. In the pre-training phase using DSMix-augmented data, knowledge distillation is employed to enhance the model's ability to extract semantic features. Experimental results on both synthetic and authentic IQA datasets demonstrate the significant predictive and generalization performance achieved by DSMix, without requiring fine-tuning of the full model. Code is available at \url{https://github.com/I2-Multimedia-Lab/DSMix}.
Transformer-based No-Reference Image Quality Assessment via Supervised Contrastive Learning
Dec 12, 2023Image Quality Assessment (IQA) has long been a research hotspot in the field of image processing, especially No-Reference Image Quality Assessment (NR-IQA). Due to the powerful feature extraction ability, existing Convolution Neural Network (CNN) and Transformers based NR-IQA methods have achieved considerable progress. However, they still exhibit limited capability when facing unknown authentic distortion datasets. To further improve NR-IQA performance, in this paper, a novel supervised contrastive learning (SCL) and Transformer-based NR-IQA model SaTQA is proposed. We first train a model on a large-scale synthetic dataset by SCL (no image subjective score is required) to extract degradation features of images with various distortion types and levels. To further extract distortion information from images, we propose a backbone network incorporating the Multi-Stream Block (MSB) by combining the CNN inductive bias and Transformer long-term dependence modeling capability. Finally, we propose the Patch Attention Block (PAB) to obtain the final distorted image quality score by fusing the degradation features learned from contrastive learning with the perceptual distortion information extracted by the backbone network. Experimental results on seven standard IQA datasets show that SaTQA outperforms the state-of-the-art methods for both synthetic and authentic datasets. Code is available at https://github.com/I2-Multimedia-Lab/SaTQA
Blind Image Quality Assessment via Transformer Predicted Error Map and Perceptual Quality Token
May 16, 2023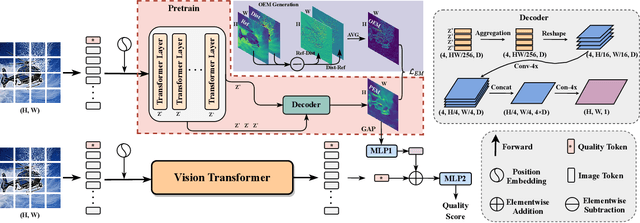
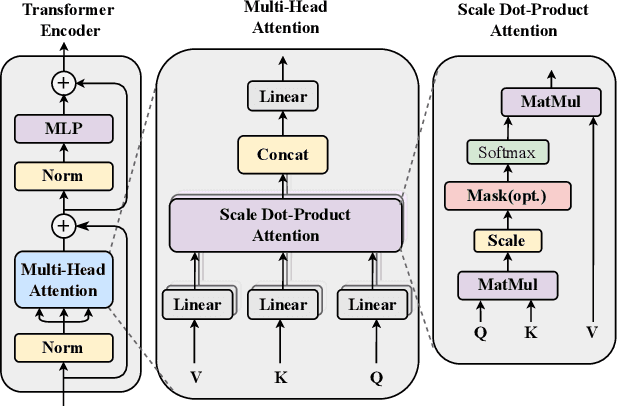
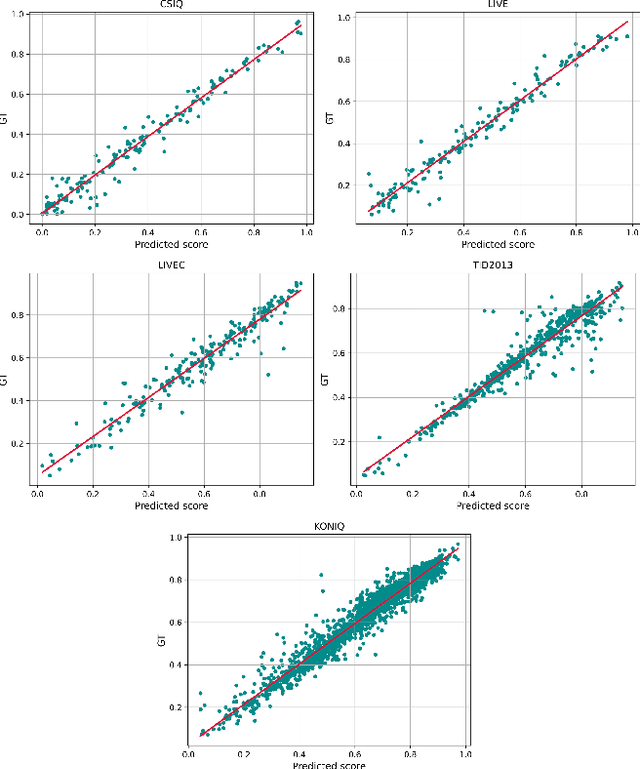

Image quality assessment is a fundamental problem in the field of image processing, and due to the lack of reference images in most practical scenarios, no-reference image quality assessment (NR-IQA), has gained increasing attention recently. With the development of deep learning technology, many deep neural network-based NR-IQA methods have been developed, which try to learn the image quality based on the understanding of database information. Currently, Transformer has achieved remarkable progress in various vision tasks. Since the characteristics of the attention mechanism in Transformer fit the global perceptual impact of artifacts perceived by a human, Transformer is thus well suited for image quality assessment tasks. In this paper, we propose a Transformer based NR-IQA model using a predicted objective error map and perceptual quality token. Specifically, we firstly generate the predicted error map by pre-training one model consisting of a Transformer encoder and decoder, in which the objective difference between the distorted and the reference images is used as supervision. Then, we freeze the parameters of the pre-trained model and design another branch using the vision Transformer to extract the perceptual quality token for feature fusion with the predicted error map. Finally, the fused features are regressed to the final image quality score. Extensive experiments have shown that our proposed method outperforms the current state-of-the-art in both authentic and synthetic image databases. Moreover, the attentional map extracted by the perceptual quality token also does conform to the characteristics of the human visual system.