 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Image Quality Assessment via Transformer Predicted Error Map and Perceptual Quality Token
Paper and Code
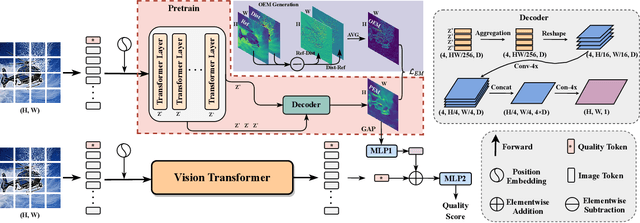
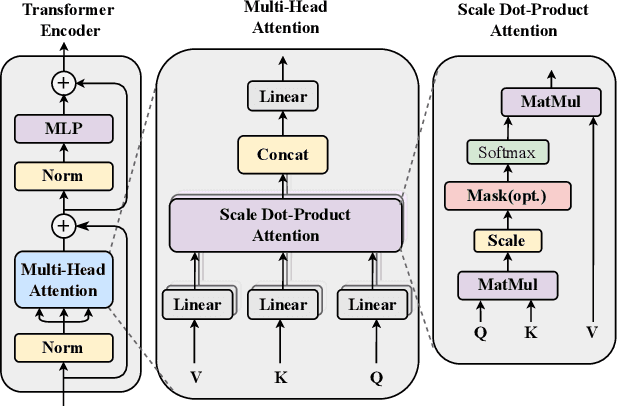
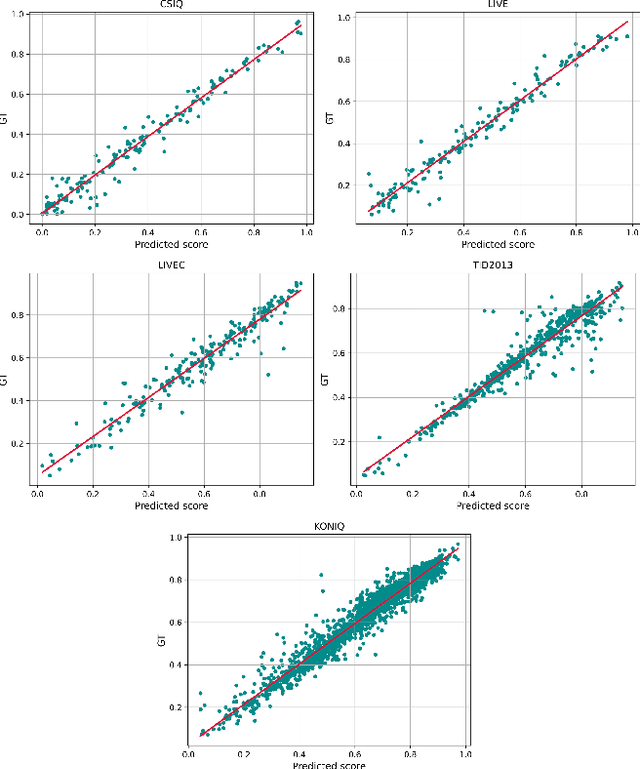

Image quality assessment is a fundamental problem in the field of image processing, and due to the lack of reference images in most practical scenarios, no-reference image quality assessment (NR-IQA), has gained increasing attention recently. With the development of deep learning technology, many deep neural network-based NR-IQA methods have been developed, which try to learn the image quality based on the understanding of database information. Currently, Transformer has achieved remarkable progress in various vision tasks. Since the characteristics of the attention mechanism in Transformer fit the global perceptual impact of artifacts perceived by a human, Transformer is thus well suited for image quality assessment tasks. In this paper, we propose a Transformer based NR-IQA model using a predicted objective error map and perceptual quality token. Specifically, we firstly generate the predicted error map by pre-training one model consisting of a Transformer encoder and decoder, in which the objective difference between the distorted and the reference images is used as supervision. Then, we freeze the parameters of the pre-trained model and design another branch using the vision Transformer to extract the perceptual quality token for feature fusion with the predicted error map. Finally, the fused features are regressed to the final image quality score. Extensive experiments have shown that our proposed method outperforms the current state-of-the-art in both authentic and synthetic image databases. Moreover, the attentional map extracted by the perceptual quality token also does conform to the characteristics of the human visual system.