 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniViTAR: Unified Vision Transformer with Native Resolution
Apr 02, 2025Conventional Vision Transformer simplifies visual modeling by standardizing input resolutions, often disregarding the variability of natural visual data and compromising spatial-contextual fidelity. While preliminary explorations have superficially investigated native resolution modeling, existing approaches still lack systematic analysis from a visual representation perspective. To bridge this gap, we introduce UniViTAR, a family of homogeneous vision foundation models tailored for unified visual modality and native resolution scenario in the era of multimodal. Our framework first conducts architectural upgrades to the vanilla paradigm by integrating multiple advanced components. Building upon these improvements, a progressive training paradigm is introduced, which strategically combines two core mechanisms: (1) resolution curriculum learning, transitioning from fixed-resolution pretraining to native resolution tuning, thereby leveraging ViT's inherent adaptability to variable-length sequences, and (2) visual modality adaptation via inter-batch image-video switching, which balances computational efficiency with enhanced temporal reasoning. In parallel, a hybrid training framework further synergizes sigmoid-based contrastive loss with feature distillation from a frozen teacher model, thereby accelerating early-stage convergence. Finally, trained exclusively on public datasets, externsive experiments across multiple model scales from 0.3B to 1B demonstrate its effectiveness.
E2E-LOAD: End-to-End Long-form Online Action Detection
Jun 13, 2023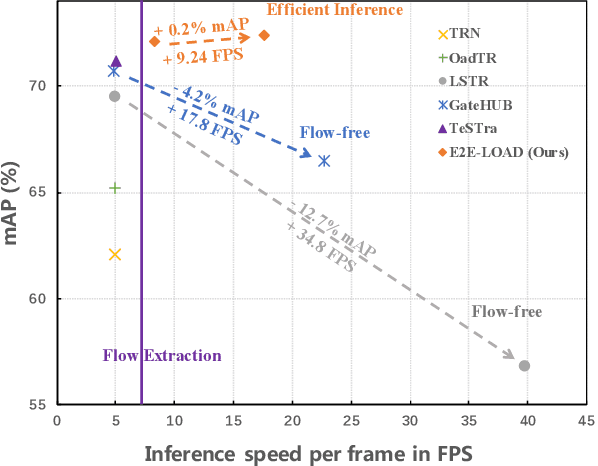
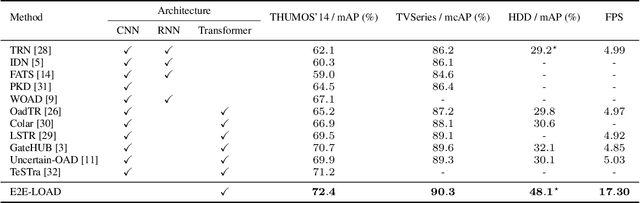
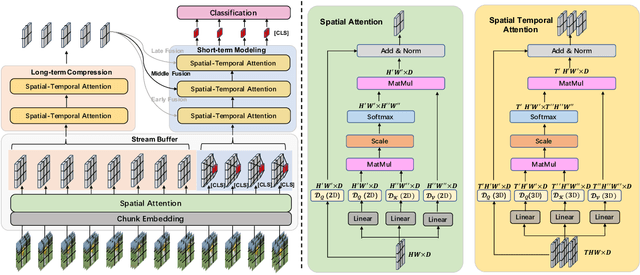

Recently, there has been a growing trend toward feature-based approaches for Online Action Detection (OAD). However, these approaches have limitations due to their fixed backbone design, which ignores the potential capability of a trainable backbone. In this paper, we propose the first end-to-end OAD model, termed E2E-LOAD, designed to address the major challenge of OAD, namely, long-term understanding and efficient online reasoning. Specifically, our proposed approach adopts an initial spatial model that is shared by all frames and maintains a long sequence cache for inference at a low computational cost. We also advocate an asymmetric spatial-temporal model for long-form and short-form modeling effectively. Furthermore, we propose a novel and efficient inference mechanism that accelerates heavy spatial-temporal exploration. Extensive ablation studies and experiments demonstrate the effectiveness and efficiency of our proposed method. Notably, we achieve 17.3 (+12.6) FPS for end-to-end OAD with 72.4%~(+1.2%), 90.3%~(+0.7%), and 48.1%~(+26.0%) mAP on THMOUS14, TVSeries, and HDD, respectively, which is 3x faster than previous approaches. The source code will be made publicly available.
A Circular Window-based Cascade Transformer for Online Action Detection
Aug 30, 2022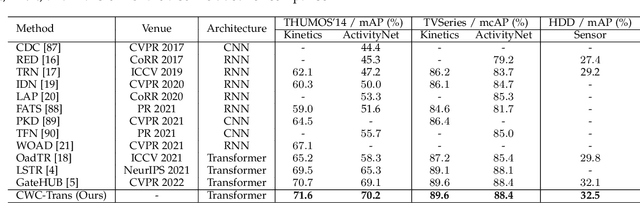
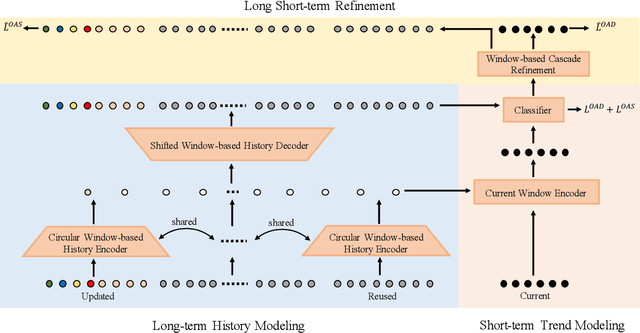
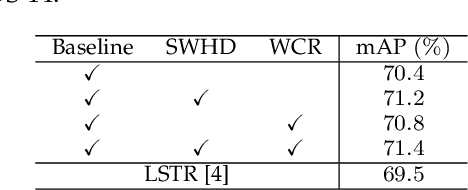
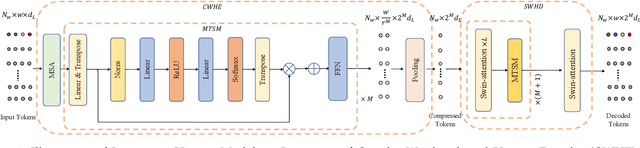
Online action detection aims at the accurate action prediction of the current frame based on long historical observations. Meanwhile, it demands real-time inference on online streaming videos. In this paper, we advocate a novel and efficient principle for online action detection. It merely updates the latest and oldest historical representations in one window but reuses the intermediate ones, which have been already computed. Based on this principle, we introduce a window-based cascade Transformer with a circular historical queue, where it conducts multi-stage attentions and cascade refinement on each window. We also explore the association between online action detection and its counterpart offline action segmentation as an auxiliary task. We find that such an extra supervision helps discriminative history clustering and acts as feature augmentation for better training the classifier and cascade refinement. Our proposed method achieves the state-of-the-art performances on three challenging datasets THUMOS'14, TVSeries, and HDD. Codes will be available after acceptance.
Controllable Video Captioning with POS Sequence Guidance Based on Gated Fusion Network
Aug 27, 2019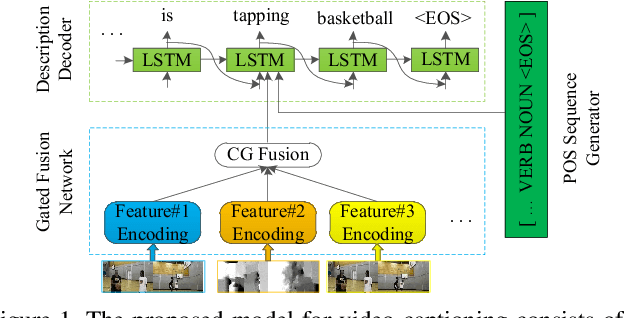
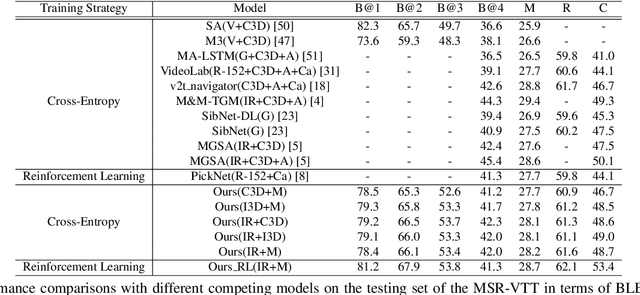
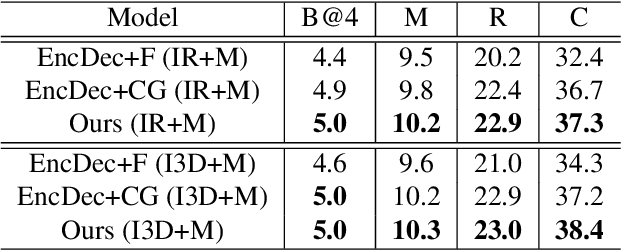
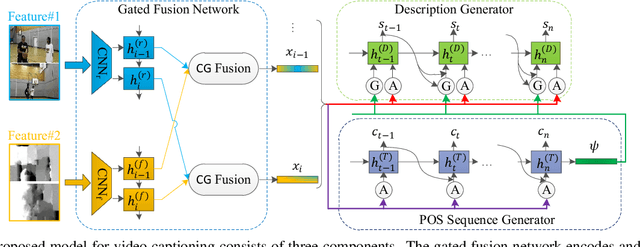
In this paper, we propose to guide the video caption generation with Part-of-Speech (POS) information, based on a gated fusion of multiple representations of input videos. We construct a novel gated fusion network, with one particularly designed cross-gating (CG) block, to effectively encode and fuse different types of representations, e.g., the motion and content features of an input video. One POS sequence generator relies on this fused representation to predict the global syntactic structure, which is thereafter leveraged to guide the video captioning generation and control the syntax of the generated sentence. Specifically, a gating strategy is proposed to dynamically and adaptively incorporate the global syntactic POS information into the decoder for generating each word. Experimental results on two benchmark datasets, namely MSR-VTT and MSVD, demonstrate that the proposed model can well exploit complementary information from multiple representations, resulting in improved performances. Moreover, the generated global POS information can well capture the global syntactic structure of the sentence, and thus be exploited to control the syntactic structure of the description. Such POS information not only boosts the video captioning performance but also improves the diversity of the generated captions. Our code is at: https://github.com/vsislab/Controllable_XGating.
Reconstruct and Represent Video Contents for Captioning via Reinforcement Learning
Jun 03, 2019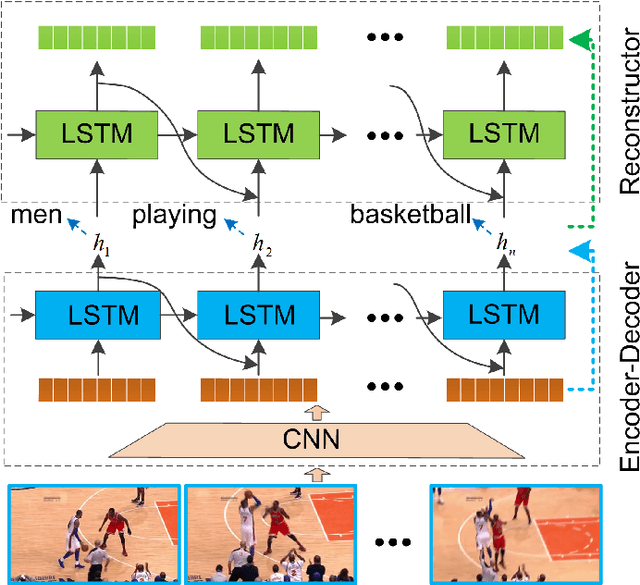
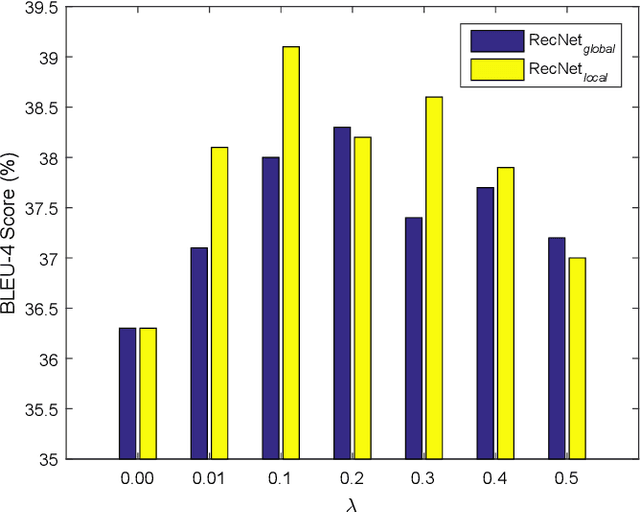
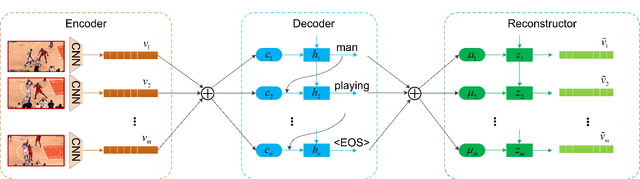
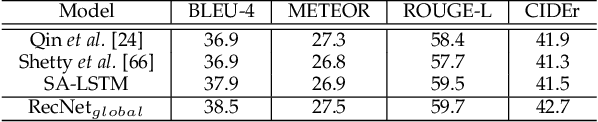
In this paper, the problem of describing visual contents of a video sequence with natural language is addressed. Unlike previous video captioning work mainly exploiting the cues of video contents to make a language description, we propose a reconstruction network (RecNet) in a novel encoder-decoder-reconstructor architecture, which leverages both forward (video to sentence) and backward (sentence to video) flows for video captioning. Specifically, the encoder-decoder component makes use of the forward flow to produce a sentence description based on the encoded video semantic features. Two types of reconstructors are subsequently proposed to employ the backward flow and reproduce the video features from local and global perspectives, respectively, capitalizing on the hidden state sequence generated by the decoder. Moreover, in order to make a comprehensive reconstruction of the video features, we propose to fuse the two types of reconstructors together. The generation loss yielded by the encoder-decoder component and the reconstruction loss introduced by the reconstructor are jointly cast into training the proposed RecNet in an end-to-end fashion. Furthermore, the RecNet is fine-tuned by CIDEr optimization via reinforcement learning, which significantly boosts the captioning performance. Experimental results on benchmark datasets demonstrate that the proposed reconstructor can boost the performance of video captioning consistently.
Hierarchical Photo-Scene Encoder for Album Storytelling
Feb 02, 2019
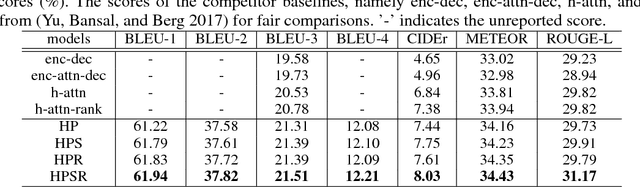
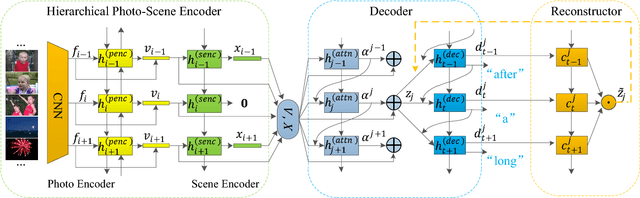
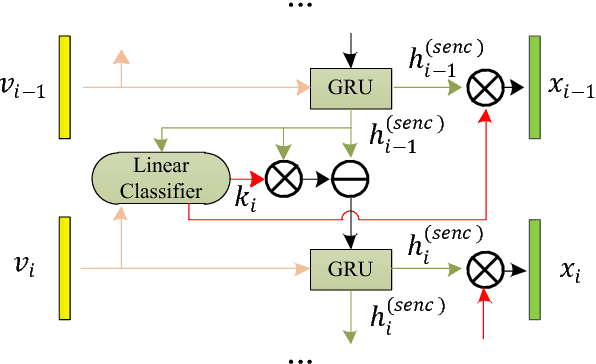
In this paper, we propose a novel model with a hierarchical photo-scene encoder and a reconstructor for the task of album storytelling. The photo-scene encoder contains two sub-encoders, namely the photo and scene encoders, which are stacked together and behave hierarchically to fully exploit the structure information of the photos within an album. Specifically, the photo encoder generates semantic representation for each photo while exploiting temporal relationships among them. The scene encoder, relying on the obtained photo representations, is responsible for detecting the scene changes and generating scene representations. Subsequently, the decoder dynamically and attentively summarizes the encoded photo and scene representations to generate a sequence of album representations, based on which a story consisting of multiple coherent sentences is generated. In order to fully extract the useful semantic information from an album, a reconstructor is employed to reproduce the summarized album representations based on the hidden states of the decoder. The proposed model can be trained in an end-to-end manner, which results in an improved performance over the state-of-the-arts on the public visual storytelling (VIST) dataset. Ablation studies further demonstrate the effectiveness of the proposed hierarchical photo-scene encoder and reconstructor.
Reconstruction Network for Video Captioning
Mar 30, 2018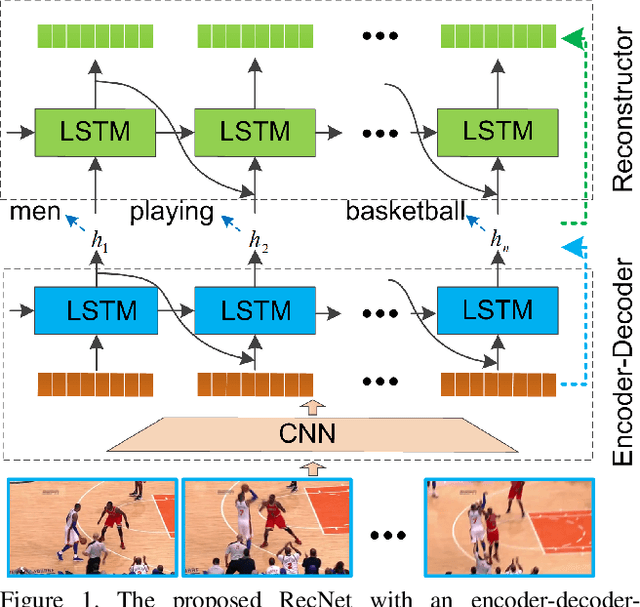
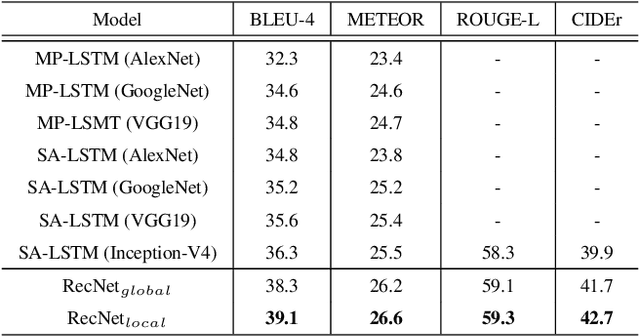
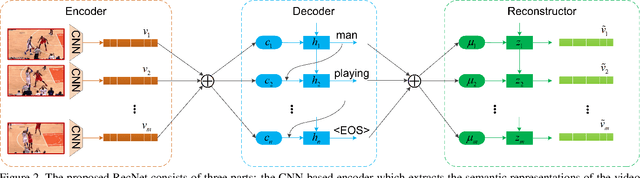
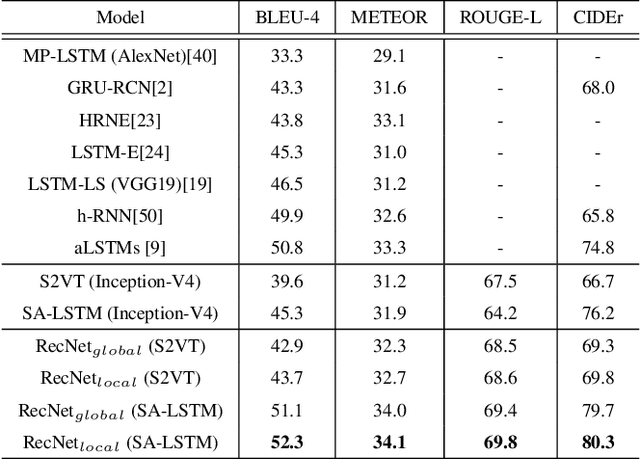
In this paper, the problem of describing visual contents of a video sequence with natural language is addressed. Unlike previous video captioning work mainly exploiting the cues of video contents to make a language description, we propose a reconstruction network (RecNet) with a novel encoder-decoder-reconstructor architecture, which leverages both the forward (video to sentence) and backward (sentence to video) flows for video captioning. Specifically, the encoder-decoder makes use of the forward flow to produce the sentence description based on the encoded video semantic features. Two types of reconstructors are customized to employ the backward flow and reproduce the video features based on the hidden state sequence generated by the decoder. The generation loss yielded by the encoder-decoder and the reconstruction loss introduced by the reconstructor are jointly drawn into training the proposed RecNet in an end-to-end fashion. Experimental results on benchmark datasets demonstrate that the proposed reconstructor can boost the encoder-decoder models and leads to significant gains in video caption accuracy.