 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2E-LOAD: End-to-End Long-form Online Action Detection
Jun 13, 2023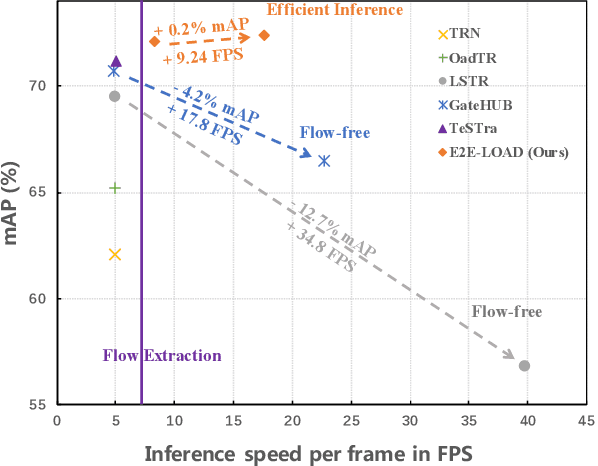
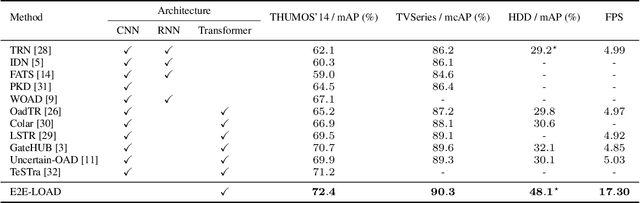
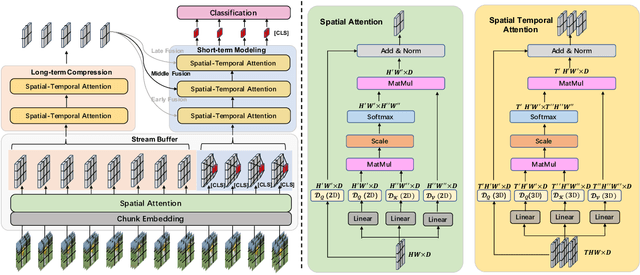

Recently, there has been a growing trend toward feature-based approaches for Online Action Detection (OAD). However, these approaches have limitations due to their fixed backbone design, which ignores the potential capability of a trainable backbone. In this paper, we propose the first end-to-end OAD model, termed E2E-LOAD, designed to address the major challenge of OAD, namely, long-term understanding and efficient online reasoning. Specifically, our proposed approach adopts an initial spatial model that is shared by all frames and maintains a long sequence cache for inference at a low computational cost. We also advocate an asymmetric spatial-temporal model for long-form and short-form modeling effectively. Furthermore, we propose a novel and efficient inference mechanism that accelerates heavy spatial-temporal exploration. Extensive ablation studies and experiments demonstrate the effectiveness and efficiency of our proposed method. Notably, we achieve 17.3 (+12.6) FPS for end-to-end OAD with 72.4%~(+1.2%), 90.3%~(+0.7%), and 48.1%~(+26.0%) mAP on THMOUS14, TVSeries, and HDD, respectively, which is 3x faster than previous approaches. The source code will be made publicly available.
A Circular Window-based Cascade Transformer for Online Action Detection
Aug 30, 2022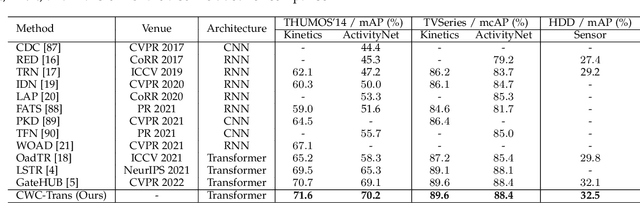
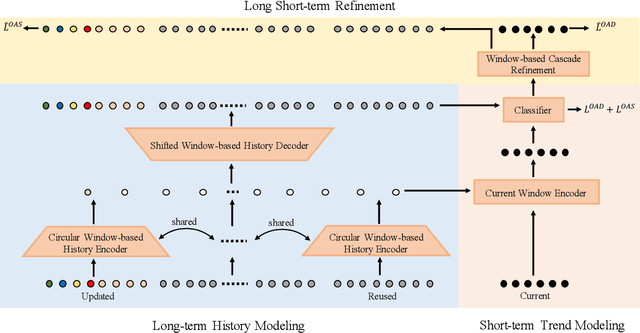
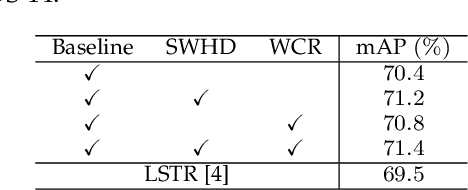
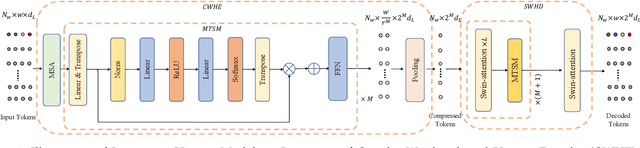
Online action detection aims at the accurate action prediction of the current frame based on long historical observations. Meanwhile, it demands real-time inference on online streaming videos. In this paper, we advocate a novel and efficient principle for online action detection. It merely updates the latest and oldest historical representations in one window but reuses the intermediate ones, which have been already computed. Based on this principle, we introduce a window-based cascade Transformer with a circular historical queue, where it conducts multi-stage attentions and cascade refinement on each window. We also explore the association between online action detection and its counterpart offline action segmentation as an auxiliary task. We find that such an extra supervision helps discriminative history clustering and acts as feature augmentation for better training the classifier and cascade refinement. Our proposed method achieves the state-of-the-art performances on three challenging datasets THUMOS'14, TVSeries, and HDD. Codes will be available after acceptance.