 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Value Alignment for Generative Recommendation in Industrial Advertising
May 07, 2026Generative Recommendation (GR) reformulates recommendation as a next-token generation problem and has shown promise in industrial applications. However, extending GR to industrial advertising is non-trivial because the system must optimize not only user interest but also commercial value. Existing GR pipelines remain largely semantics-centric, making it difficult to align value signals across tokenization, decoding, and online serving. To address this issue, we propose UniVA, a Unified Value Alignment framework for advertising recommendation. We first introduce a Commercial SID tokenizer that injects value-related attributes into SID construction, yielding value-discriminative item representations. We then develop a Generation-as-Ranking SID Decoder jointly optimized by supervised learning and eCPM-aware reinforcement learning, which fuses value scores into next-item SID generation to perform generation and ranking in one decoding process. Finally, we design a value-guided personalized beam search that reuses generation-as-ranking logits as online value guidance and applies a personalized trie tree to constrain decoding to request-valid SID paths. Experiments on the Tencent WeChat Channels advertising platform show that UniVA achieves a 37.04\% improvement in offline Hit Rate@100 over the baseline and a 1.5\% GMV lift in online A/B tests.
Learning to Build: Autonomous Robotic Assembly of Stable Structures Without Predefined Plans
Feb 27, 2026This paper presents a novel autonomous robotic assembly framework for constructing stable structures without relying on predefined architectural blueprints. Instead of following fixed plans, construction tasks are defined through targets and obstacles, allowing the system to adapt more flexibly to environmental uncertainty and variations during the building process. A reinforcement learning (RL) policy, trained using deep Q-learning with successor features, serves as the decision-making component. As a proof of concept, we evaluate the approach on a benchmark of 15 2D robotic assembly tasks of discrete block construction. Experiments using a real-world closed-loop robotic setup demonstrate the feasibility of the method and its ability to handle construction noise. The results suggest that our framework offers a promising direction for more adaptable and robust robotic construction in real-world environments.
End-to-End Semantic ID Generation for Generative Advertisement Recommendation
Feb 12, 2026Generative Recommendation (GR) has excelled by framing recommendation as next-token prediction. This paradigm relies on Semantic IDs (SIDs) to tokenize large-scale items into discrete sequences. Existing GR approaches predominantly generate SIDs via Residual Quantization (RQ), where items are encoded into embeddings and then quantized to discrete SIDs. However, this paradigm suffers from inherent limitations: 1) Objective misalignment and semantic degradation stemming from the two-stage compression; 2) Error accumulation inherent in the structure of RQ. To address these limitations, we propose UniSID, a Unified SID generation framework for generative advertisement recommendation. Specifically, we jointly optimize embeddings and SIDs in an end-to-end manner from raw advertising data, enabling semantic information to flow directly into the SID space and thus addressing the inherent limitations of the two-stage cascading compression paradigm. To capture fine-grained semantics, a multi-granularity contrastive learning strategy is introduced to align distinct items across SID levels. Finally, a summary-based ad reconstruction mechanism is proposed to encourage SIDs to capture high-level semantic information that is not explicitly present in advertising contexts. Experiments demonstrate that UniSID consistently outperforms state-of-the-art SID generation methods, yielding up to a 4.62% improvement in Hit Rate metrics across downstream advertising scenarios compared to the strongest baseline.
Less is More: Enhancing Structured Multi-Agent Reasoning via Quality-Guided Distillation
Apr 23, 2025

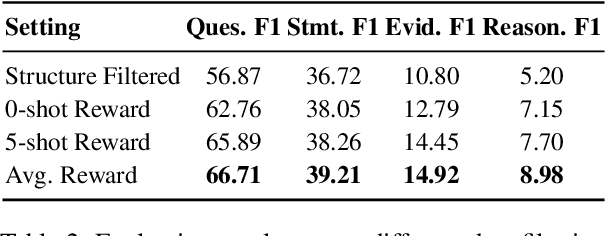

The XLLM@ACL2025 Shared Task-III formulates a low-resource structural reasoning task that challenges LLMs to generate interpretable, step-by-step rationales with minimal labeled data. We present Less is More, the third-place winning approach in the XLLM@ACL2025 Shared Task-III, which focuses on structured reasoning from only 24 labeled examples. Our approach leverages a multi-agent framework with reverse-prompt induction, retrieval-augmented reasoning synthesis via GPT-4o, and dual-stage reward-guided filtering to distill high-quality supervision across three subtasks: question parsing, CoT parsing, and step-level verification. All modules are fine-tuned from Meta-Llama-3-8B-Instruct under a unified LoRA+ setup. By combining structure validation with reward filtering across few-shot and zero-shot prompts, our pipeline consistently improves structure reasoning quality. These results underscore the value of controllable data distillation in enhancing structured inference under low-resource constraints. Our code is available at https://github.com/Jiahao-Yuan/Less-is-More.
Self-supervised Preference Optimization: Enhance Your Language Model with Preference Degree Awareness
Sep 26, 2024



Recently, there has been significant interest in replacing the reward model in Reinforcement Learning with Human Feedback (RLHF) methods for Large Language Models (LLMs), such as Direct Preference Optimization (DPO) and its variants. These approaches commonly use a binary cross-entropy mechanism on pairwise samples, i.e., minimizing and maximizing the loss based on preferred or dis-preferred responses, respectively. However, while this training strategy omits the reward model, it also overlooks the varying preference degrees within different responses. We hypothesize that this is a key factor hindering LLMs from sufficiently understanding human preferences. To address this problem, we propose a novel Self-supervised Preference Optimization (SPO) framework, which constructs a self-supervised preference degree loss combined with the alignment loss, thereby helping LLMs improve their ability to understand the degree of preference. Extensive experiments are conducted on two widely used datasets of different tasks. The results demonstrate that SPO can be seamlessly integrated with existing preference optimization methods and significantly boost their performance to achieve state-of-the-art performance. We also conduct detailed analyses to offer comprehensive insights into SPO, which verifies its effectiveness. The code is available at https://github.com/lijian16/SPO.
CIER: A Novel Experience Replay Approach with Causal Inference in Deep Reinforcement Learning
May 14, 2024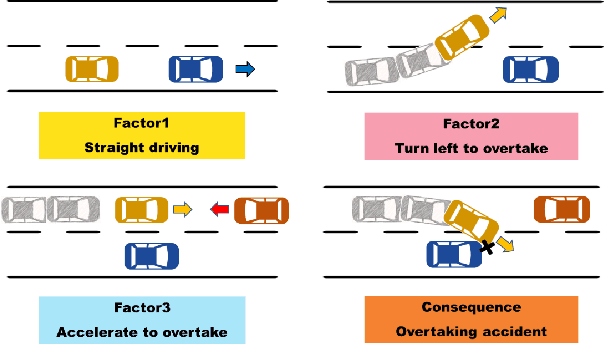


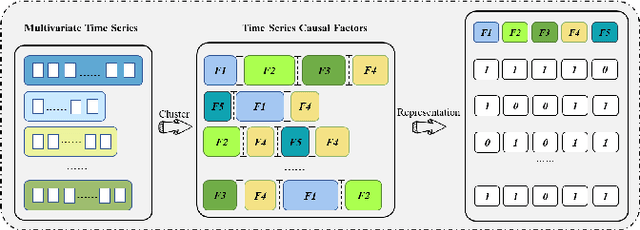
In the training process of Deep Reinforcement Learning (DRL), agents require repetitive interactions with the environment. With an increase in training volume and model complexity, it is still a challenging problem to enhance data utilization and explainability of DRL training. This paper addresses these challenges by focusing on the temporal correlations within the time dimension of time series. We propose a novel approach to segment multivariate time series into meaningful subsequences and represent the time series based on these subsequences. Furthermore, the subsequences are employed for causal inference to identify fundamental causal factors that significantly impact training outcomes. We design a module to provide feedback on the causality during DRL training. Several experiments demonstrate the feasibility of our approach in common environments, confirming its ability to enhance the effectiveness of DRL training and impart a certain level of explainability to the training process. Additionally, we extended our approach with priority experience replay algorithm, and experimental results demonstrate the continued effectiveness of our approach.
MorpheuS: Neural Dynamic 360° Surface Reconstruction from Monocular RGB-D Video
Dec 01, 2023Neural rendering has demonstrated remarkable success in dynamic scene reconstruction. Thanks to the expressiveness of neural representations, prior works can accurately capture the motion and achieve high-fidelity reconstruction of the target object. Despite this, real-world video scenarios often feature large unobserved regions where neural representations struggle to achieve realistic completion. To tackle this challenge, we introduce MorpheuS, a framework for dynamic 360{\deg} surface reconstruction from a casually captured RGB-D video. Our approach models the target scene as a canonical field that encodes its geometry and appearance, in conjunction with a deformation field that warps points from the current frame to the canonical space. We leverage a view-dependent diffusion prior and distill knowledge from it to achieve realistic completion of unobserved regions. Experimental results on various real-world and synthetic datasets show that our method can achieve high-fidelity 360{\deg} surface reconstruction of a deformable object from a monocular RGB-D video.
SeMLaPS: Real-time Semantic Mapping with Latent Prior Networks and Quasi-Planar Segmentation
Jun 28, 2023



The availability of real-time semantics greatly improves the core geometric functionality of SLAM systems, enabling numerous robotic and AR/VR applications. We present a new methodology for real-time semantic mapping from RGB-D sequences that combines a 2D neural network and a 3D network based on a SLAM system with 3D occupancy mapping. When segmenting a new frame we perform latent feature re-projection from previous frames based on differentiable rendering. Fusing re-projected feature maps from previous frames with current-frame features greatly improves image segmentation quality, compared to a baseline that processes images independently. For 3D map processing, we propose a novel geometric quasi-planar over-segmentation method that groups 3D map elements likely to belong to the same semantic classes, relying on surface normals. We also describe a novel neural network design for lightweight semantic map post-processing. Our system achieves state-of-the-art semantic mapping quality within 2D-3D networks-based systems and matches the performance of 3D convolutional networks on three real indoor datasets, while working in real-time. Moreover, it shows better cross-sensor generalization abilities compared to 3D CNNs, enabling training and inference with different depth sensors. Code and data will be released on project page: http://jingwenwang95.github.io/SeMLaPS
First Place Solution to the CVPR'2023 AQTC Challenge: A Function-Interaction Centric Approach with Spatiotemporal Visual-Language Alignment
Jun 23, 2023



Affordance-Centric Question-driven Task Completion (AQTC) has been proposed to acquire knowledge from videos to furnish users with comprehensive and systematic instructions. However, existing methods have hitherto neglected the necessity of aligning spatiotemporal visual and linguistic signals, as well as the crucial interactional information between humans and objects. To tackle these limitations, we propose to combine large-scale pre-trained vision-language and video-language models, which serve to contribute stable and reliable multimodal data and facilitate effective spatiotemporal visual-textual alignment. Additionally, a novel hand-object-interaction (HOI) aggregation module is proposed which aids in capturing human-object interaction information, thereby further augmenting the capacity to understand the presented scenario. Our method achieved first place in the CVPR'2023 AQTC Challenge, with a Recall@1 score of 78.7\%. The code is available at https://github.com/tomchen-ctj/CVPR23-LOVEU-AQTC.
Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM
Apr 27, 2023We present Co-SLAM, a neural RGB-D SLAM system based on a hybrid representation, that performs robust camera tracking and high-fidelity surface reconstruction in real time. Co-SLAM represents the scene as a multi-resolution hash-grid to exploit its high convergence speed and ability to represent high-frequency local features. In addition, Co-SLAM incorporates one-blob encoding, to encourage surface coherence and completion in unobserved areas. This joint parametric-coordinate encoding enables real-time and robust performance by bringing the best of both worlds: fast convergence and surface hole filling. Moreover, our ray sampling strategy allows Co-SLAM to perform global bundle adjustment over all keyframes instead of requiring keyframe selection to maintain a small number of active keyframes as competing neural SLAM approaches do. Experimental results show that Co-SLAM runs at 10-17Hz and achieves state-of-the-art scene reconstruction results, and competitive tracking performance in various datasets and benchmarks (ScanNet, TUM, Replica, Synthetic RGBD). Project page: https://hengyiwang.github.io/projects/CoSLAM