 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeMLaPS: Real-time Semantic Mapping with Latent Prior Networks and Quasi-Planar Segmentation
Jun 28, 2023



The availability of real-time semantics greatly improves the core geometric functionality of SLAM systems, enabling numerous robotic and AR/VR applications. We present a new methodology for real-time semantic mapping from RGB-D sequences that combines a 2D neural network and a 3D network based on a SLAM system with 3D occupancy mapping. When segmenting a new frame we perform latent feature re-projection from previous frames based on differentiable rendering. Fusing re-projected feature maps from previous frames with current-frame features greatly improves image segmentation quality, compared to a baseline that processes images independently. For 3D map processing, we propose a novel geometric quasi-planar over-segmentation method that groups 3D map elements likely to belong to the same semantic classes, relying on surface normals. We also describe a novel neural network design for lightweight semantic map post-processing. Our system achieves state-of-the-art semantic mapping quality within 2D-3D networks-based systems and matches the performance of 3D convolutional networks on three real indoor datasets, while working in real-time. Moreover, it shows better cross-sensor generalization abilities compared to 3D CNNs, enabling training and inference with different depth sensors. Code and data will be released on project page: http://jingwenwang95.github.io/SeMLaPS
Multi-Resolution 3D Mapping with Explicit Free Space Representation for Fast and Accurate Mobile Robot Motion Planning
Oct 19, 2020
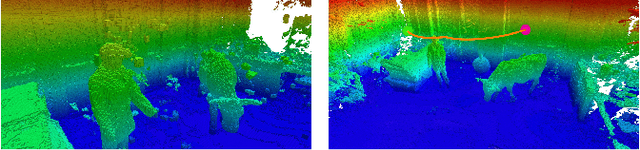
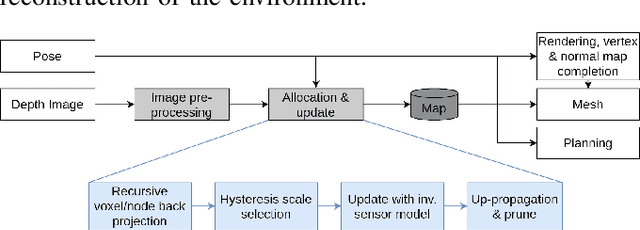
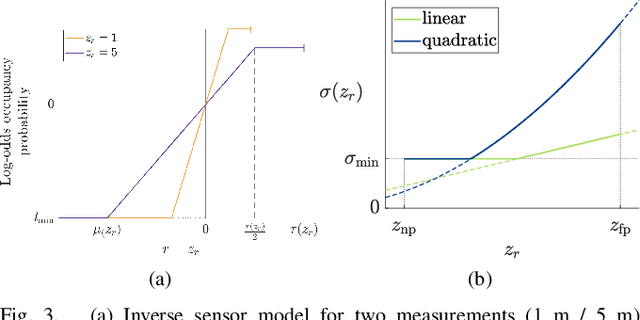
With the aim of bridging the gap between high quality reconstruction and mobile robot motion planning, we propose an efficient system that leverages the concept of adaptive-resolution volumetric mapping, which naturally integrates with the hierarchical decomposition of space in an octree data structure. Instead of a Truncated Signed Distance Function (TSDF), we adopt mapping of occupancy probabilities in log-odds representation, which allows to represent both surfaces, as well as the entire free, i.e. observed space, as opposed to unobserved space. We introduce a method for choosing resolution -- on the fly -- in real-time by means of a multi-scale max-min pooling of the input depth image. The notion of explicit free space mapping paired with the spatial hierarchy in the data structure, as well as map resolution, allows for collision queries, as needed for robot motion planning, at unprecedented speed. We quantitatively evaluate mapping accuracy, memory, runtime performance, and planning performance showing improvements over the state of the art, particularly in cases requiring high resolution maps.
Towards Bounding-Box Free Panoptic Segmentation
Feb 19, 2020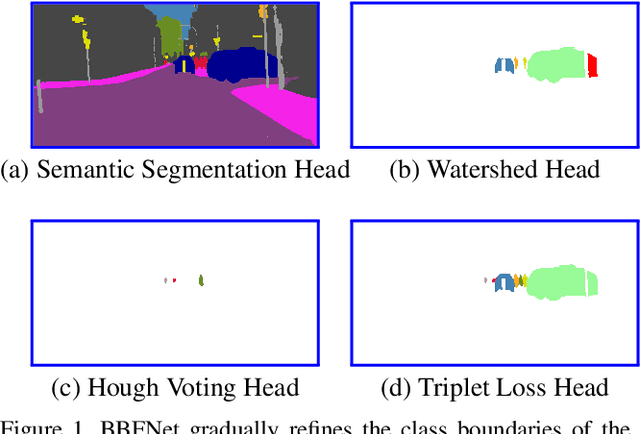

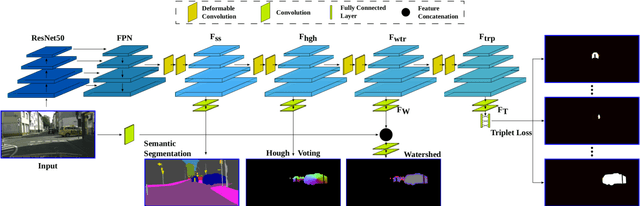

In this work we introduce a new bounding-box free network (BBFNet) for panoptic segmentation. Panoptic segmentation is an ideal problem for a bounding-box free approach as it already requires per-pixel semantic class labels. We use this observation to exploit class boundaries from an off-the-shelf semantic segmentation network and refine them to predict instance labels. Towards this goal BBFNet predicts coarse watershed levels and use it to detect large instance candidates where boundaries are well defined. For smaller instances, whose boundaries are less reliable, BBFNet also predicts instance centers by means of Hough voting followed by mean-shift to reliably detect small objects. A novel triplet loss network helps merging fragmented instances while refining boundary pixels. Our approach is distinct from previous works in panoptic segmentation that rely on a combination of a semantic segmentation network with a computationally costly instance segmentation network based on bounding boxes, such as Mask R-CNN, to guide the prediction of instance labels using a Mixture-of-Expert (MoE) approach. We benchmark our non-MoE method on Cityscapes and Microsoft COCO datasets and show competitive performance with other MoE based approaches while outperfroming exisiting non-proposal based approaches. We achieve this while been computationally more efficient in terms of number of parameters and FLOPs. Video results are provided here https://blog.slamcore.com/reducing-the-cost-of-understanding.
A Continuous Optimization Approach for Efficient and Accurate Scene Flow
Jul 27, 2016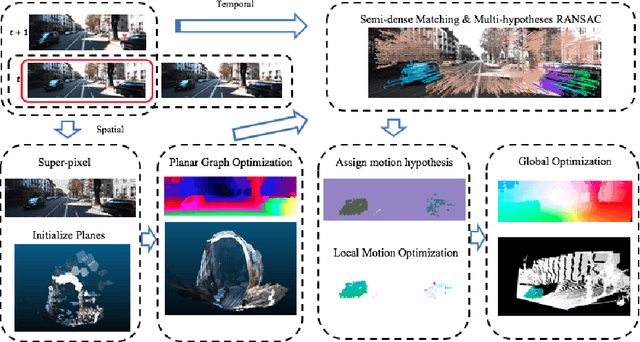

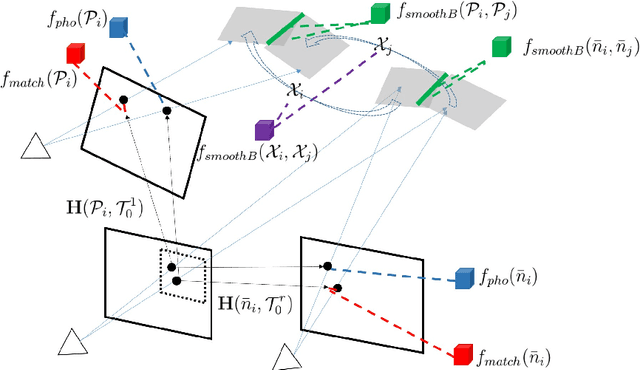

We propose a continuous optimization method for solving dense 3D scene flow problems from stereo imagery. As in recent work, we represent the dynamic 3D scene as a collection of rigidly moving planar segments. The scene flow problem then becomes the joint estimation of pixel-to-segment assignment, 3D position, normal vector and rigid motion parameters for each segment, leading to a complex and expensive discrete-continuous optimization problem. In contrast, we propose a purely continuous formulation which can be solved more efficiently. Using a fine superpixel segmentation that is fixed a-priori, we propose a factor graph formulation that decomposes the problem into photometric, geometric, and smoothing constraints. We initialize the solution with a novel, high-quality initialization method, then independently refine the geometry and motion of the scene, and finally perform a global non-linear refinement using Levenberg-Marquardt. We evaluate our method in the challenging KITTI Scene Flow benchmark, ranking in third position, while being 3 to 30 times faster than the top competitors.
Noise Models in Feature-based Stereo Visual Odometry
Jul 01, 2016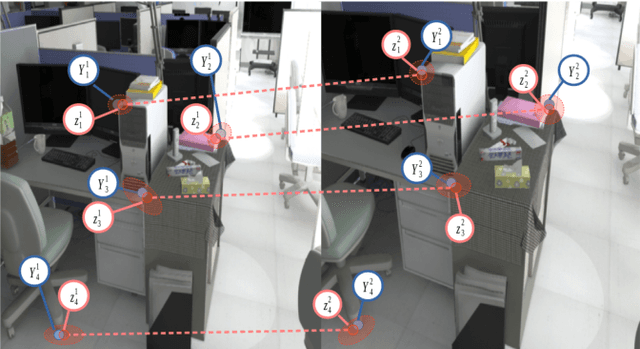
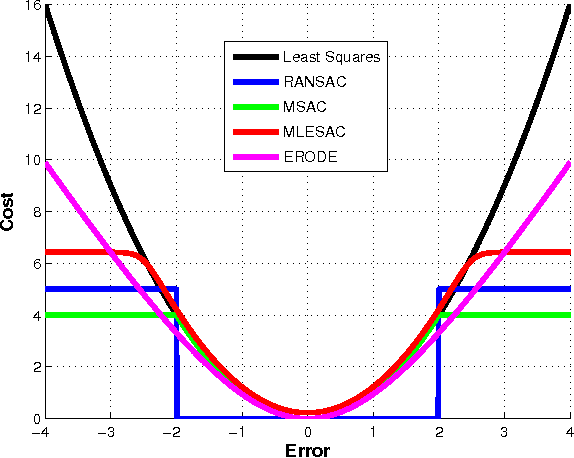
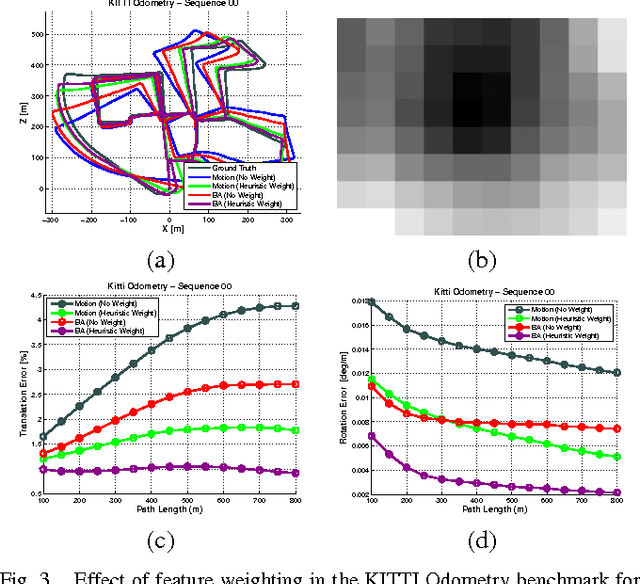
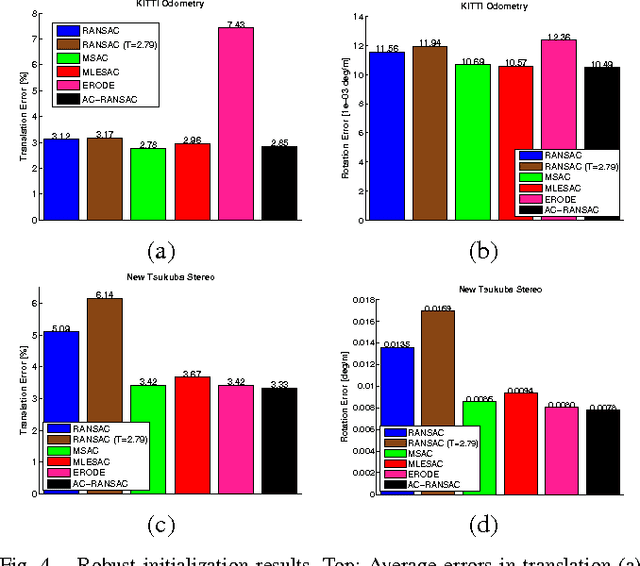
Feature-based visual structure and motion reconstruction pipelines, common in visual odometry and large-scale reconstruction from photos, use the location of corresponding features in different images to determine the 3D structure of the scene, as well as the camera parameters associated with each image. The noise model, which defines the likelihood of the location of each feature in each image, is a key factor in the accuracy of such pipelines, alongside optimization strategy. Many different noise models have been proposed in the literature; in this paper we investigate the performance of several. We evaluate these models specifically w.r.t. stereo visual odometry, as this task is both simple (camera intrinsics are constant and known; geometry can be initialized reliably) and has datasets with ground truth readily available (KITTI Odometry and New Tsukuba Stereo Dataset). Our evaluation shows that noise models which are more adaptable to the varying nature of noise generally perform better.
Training Constrained Deconvolutional Networks for Road Scene Semantic Segmentation
Apr 06, 2016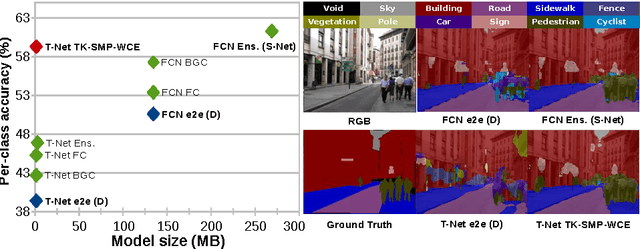
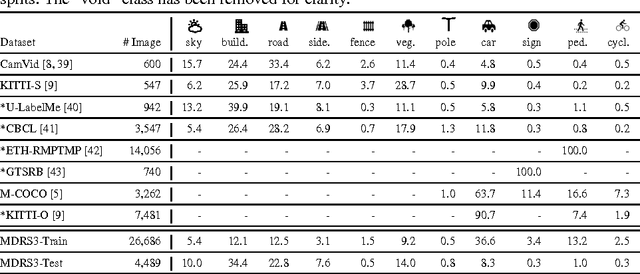

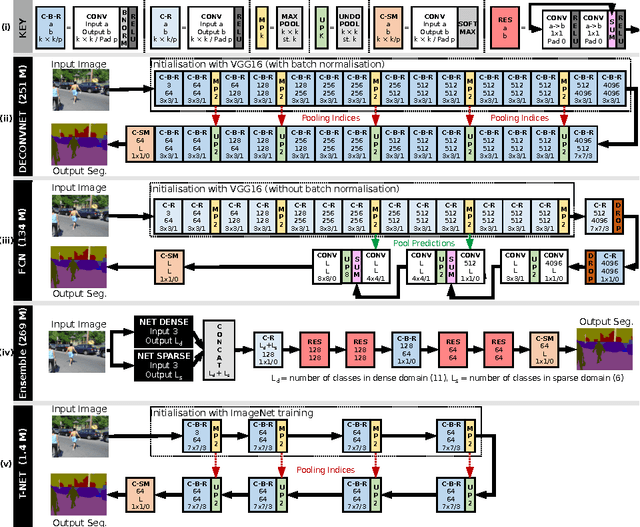
In this work we investigate the problem of road scene semantic segmentation using Deconvolutional Networks (DNs). Several constraints limit the practical performance of DNs in this context: firstly, the paucity of existing pixel-wise labelled training data, and secondly, the memory constraints of embedded hardware, which rule out the practical use of state-of-the-art DN architectures such as fully convolutional networks (FCN). To address the first constraint, we introduce a Multi-Domain Road Scene Semantic Segmentation (MDRS3) dataset, aggregating data from six existing densely and sparsely labelled datasets for training our models, and two existing, separate datasets for testing their generalisation performance. We show that, while MDRS3 offers a greater volume and variety of data, end-to-end training of a memory efficient DN does not yield satisfactory performance. We propose a new training strategy to overcome this, based on (i) the creation of a best-possible source network (S-Net) from the aggregated data, ignoring time and memory constraints; and (ii) the transfer of knowledge from S-Net to the memory-efficient target network (T-Net). We evaluate different techniques for S-Net creation and T-Net transferral, and demonstrate that training a constrained deconvolutional network in this manner can unlock better performance than existing training approaches. Specifically, we show that a target network can be trained to achieve improved accuracy versus an FCN despite using less than 1\% of the memory. We believe that our approach can be useful beyond automotive scenarios where labelled data is similarly scarce or fragmented and where practical constraints exist on the desired model size. We make available our network models and aggregated multi-domain dataset for reproducibility.