 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeMLaPS: Real-time Semantic Mapping with Latent Prior Networks and Quasi-Planar Segmentation
Jun 28, 2023



The availability of real-time semantics greatly improves the core geometric functionality of SLAM systems, enabling numerous robotic and AR/VR applications. We present a new methodology for real-time semantic mapping from RGB-D sequences that combines a 2D neural network and a 3D network based on a SLAM system with 3D occupancy mapping. When segmenting a new frame we perform latent feature re-projection from previous frames based on differentiable rendering. Fusing re-projected feature maps from previous frames with current-frame features greatly improves image segmentation quality, compared to a baseline that processes images independently. For 3D map processing, we propose a novel geometric quasi-planar over-segmentation method that groups 3D map elements likely to belong to the same semantic classes, relying on surface normals. We also describe a novel neural network design for lightweight semantic map post-processing. Our system achieves state-of-the-art semantic mapping quality within 2D-3D networks-based systems and matches the performance of 3D convolutional networks on three real indoor datasets, while working in real-time. Moreover, it shows better cross-sensor generalization abilities compared to 3D CNNs, enabling training and inference with different depth sensors. Code and data will be released on project page: http://jingwenwang95.github.io/SeMLaPS
Self-Supervised Depth Completion for Active Stereo
Oct 07, 2021


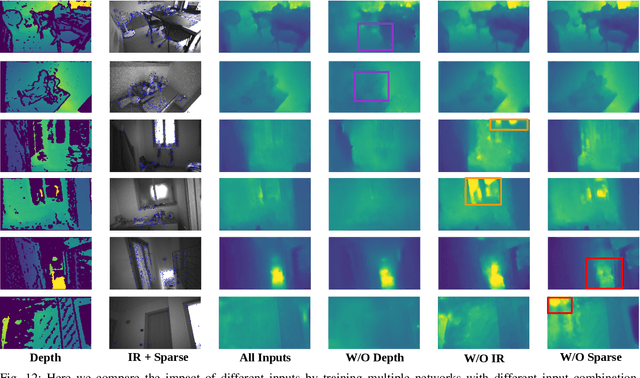
Active stereo systems are widely used in the robotics industry due to their low cost and high quality depth maps. These depth sensors, however, suffer from stereo artefacts and do not provide dense depth estimates. In this work, we present the first self-supervised depth completion method for active stereo systems that predicts accurate dense depth maps. Our system leverages a feature-based visual inertial SLAM system to produce motion estimates and accurate (but sparse) 3D landmarks. The 3D landmarks are used both as model input and as supervision during training. The motion estimates are used in our novel reconstruction loss that relies on a combination of passive and active stereo frames, resulting in significant improvements in textureless areas that are common in indoor environments. Due to the non-existence of publicly available active stereo datasets, we release a real dataset together with additional information for a publicly available synthetic dataset needed for active depth completion and prediction. Through rigorous evaluations we show that our method outperforms state of the art on both datasets. Additionally we show how our method obtains more complete, and therefore safer, 3D maps when used in a robotic platform
Multi-Resolution 3D Mapping with Explicit Free Space Representation for Fast and Accurate Mobile Robot Motion Planning
Oct 19, 2020
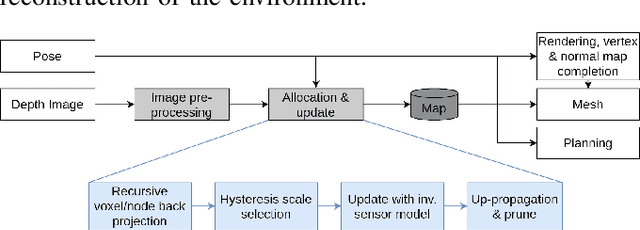
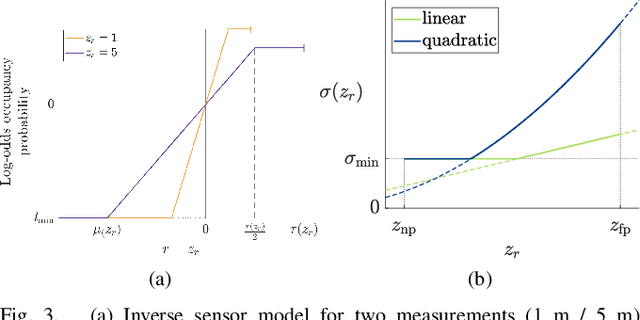
With the aim of bridging the gap between high quality reconstruction and mobile robot motion planning, we propose an efficient system that leverages the concept of adaptive-resolution volumetric mapping, which naturally integrates with the hierarchical decomposition of space in an octree data structure. Instead of a Truncated Signed Distance Function (TSDF), we adopt mapping of occupancy probabilities in log-odds representation, which allows to represent both surfaces, as well as the entire free, i.e. observed space, as opposed to unobserved space. We introduce a method for choosing resolution -- on the fly -- in real-time by means of a multi-scale max-min pooling of the input depth image. The notion of explicit free space mapping paired with the spatial hierarchy in the data structure, as well as map resolution, allows for collision queries, as needed for robot motion planning, at unprecedented speed. We quantitatively evaluate mapping accuracy, memory, runtime performance, and planning performance showing improvements over the state of the art, particularly in cases requiring high resolution maps.