 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Foot Forward: Robust Foot Reconstruction in-the-wild
Feb 27, 2025Accurate 3D foot reconstruction is crucial for personalized orthotics, digital healthcare, and virtual fittings. However, existing methods struggle with incomplete scans and anatomical variations, particularly in self-scanning scenarios where user mobility is limited, making it difficult to capture areas like the arch and heel. We present a novel end-to-end pipeline that refines Structure-from-Motion (SfM) reconstruction. It first resolves scan alignment ambiguities using SE(3) canonicalization with a viewpoint prediction module, then completes missing geometry through an attention-based network trained on synthetically augmented point clouds. Our approach achieves state-of-the-art performance on reconstruction metrics while preserving clinically validated anatomical fidelity. By combining synthetic training data with learned geometric priors, we enable robust foot reconstruction under real-world capture conditions, unlocking new opportunities for mobile-based 3D scanning in healthcare and retail.
Self-Supervised Depth Completion for Active Stereo
Oct 07, 2021


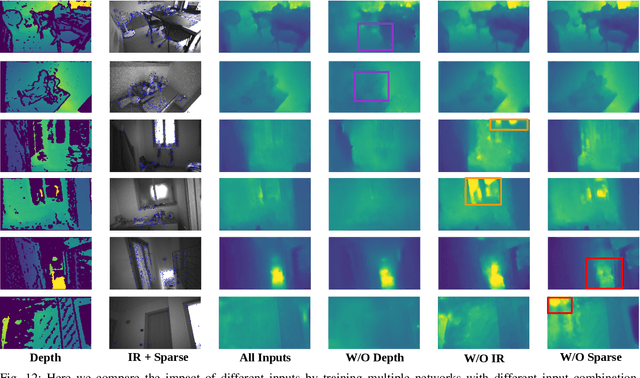
Active stereo systems are widely used in the robotics industry due to their low cost and high quality depth maps. These depth sensors, however, suffer from stereo artefacts and do not provide dense depth estimates. In this work, we present the first self-supervised depth completion method for active stereo systems that predicts accurate dense depth maps. Our system leverages a feature-based visual inertial SLAM system to produce motion estimates and accurate (but sparse) 3D landmarks. The 3D landmarks are used both as model input and as supervision during training. The motion estimates are used in our novel reconstruction loss that relies on a combination of passive and active stereo frames, resulting in significant improvements in textureless areas that are common in indoor environments. Due to the non-existence of publicly available active stereo datasets, we release a real dataset together with additional information for a publicly available synthetic dataset needed for active depth completion and prediction. Through rigorous evaluations we show that our method outperforms state of the art on both datasets. Additionally we show how our method obtains more complete, and therefore safer, 3D maps when used in a robotic platform
Towards Bounding-Box Free Panoptic Segmentation
Feb 19, 2020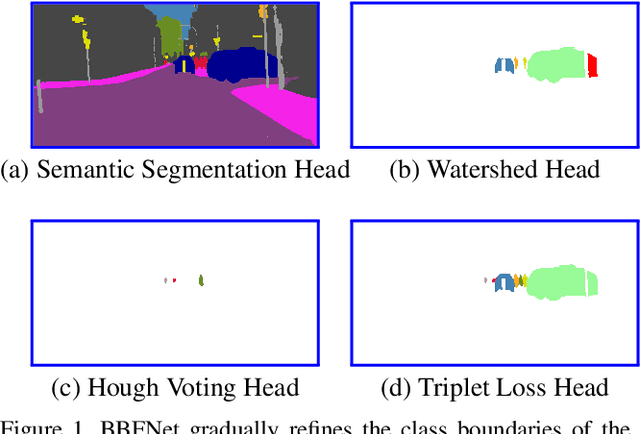

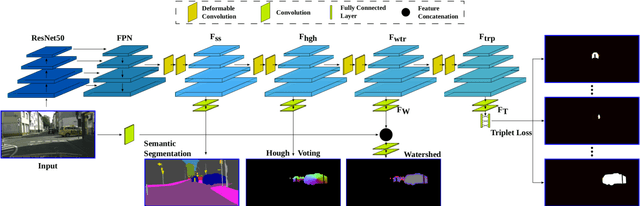

In this work we introduce a new bounding-box free network (BBFNet) for panoptic segmentation. Panoptic segmentation is an ideal problem for a bounding-box free approach as it already requires per-pixel semantic class labels. We use this observation to exploit class boundaries from an off-the-shelf semantic segmentation network and refine them to predict instance labels. Towards this goal BBFNet predicts coarse watershed levels and use it to detect large instance candidates where boundaries are well defined. For smaller instances, whose boundaries are less reliable, BBFNet also predicts instance centers by means of Hough voting followed by mean-shift to reliably detect small objects. A novel triplet loss network helps merging fragmented instances while refining boundary pixels. Our approach is distinct from previous works in panoptic segmentation that rely on a combination of a semantic segmentation network with a computationally costly instance segmentation network based on bounding boxes, such as Mask R-CNN, to guide the prediction of instance labels using a Mixture-of-Expert (MoE) approach. We benchmark our non-MoE method on Cityscapes and Microsoft COCO datasets and show competitive performance with other MoE based approaches while outperfroming exisiting non-proposal based approaches. We achieve this while been computationally more efficient in terms of number of parameters and FLOPs. Video results are provided here https://blog.slamcore.com/reducing-the-cost-of-understanding.
ContextNet: Exploring Context and Detail for Semantic Segmentation in Real-time
Nov 05, 2018



Modern deep learning architectures produce highly accurate results on many challenging semantic segmentation datasets. State-of-the-art methods are, however, not directly transferable to real-time applications or embedded devices, since naive adaptation of such systems to reduce computational cost (speed, memory and energy) causes a significant drop in accuracy. We propose ContextNet, a new deep neural network architecture which builds on factorized convolution, network compression and pyramid representation to produce competitive semantic segmentation in real-time with low memory requirement. ContextNet combines a deep network branch at low resolution that captures global context information efficiently with a shallow branch that focuses on high-resolution segmentation details. We analyse our network in a thorough ablation study and present results on the Cityscapes dataset, achieving 66.1% accuracy at 18.3 frames per second at full (1024x2048) resolution (41.9 fps with pipelined computations for streamed data).
Weakly supervised learning of indoor geometry by dual warping
Aug 10, 2018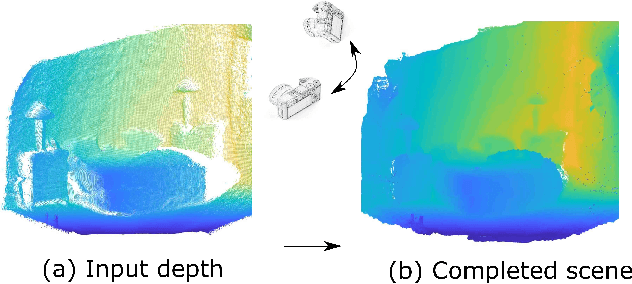
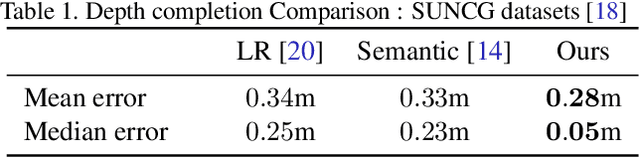
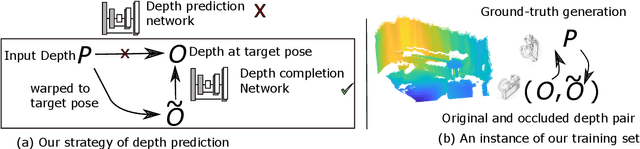
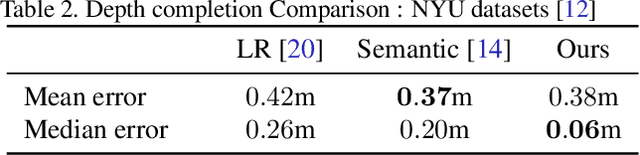
A major element of depth perception and 3D understanding is the ability to predict the 3D layout of a scene and its contained objects for a novel pose. Indoor environments are particularly suitable for novel view prediction, since the set of objects in such environments is relatively restricted. In this work we address the task of 3D prediction especially for indoor scenes by leveraging only weak supervision. In the literature 3D scene prediction is usually solved via a 3D voxel grid. However, such methods are limited to estimating rather coarse 3D voxel grids, since predicting entire voxel spaces has large computational costs. Hence, our method operates in image-space rather than in voxel space, and the task of 3D estimation essentially becomes a depth image completion problem. We propose a novel approach to easily generate training data containing depth maps with realistic occlusions, and subsequently train a network for completing those occluded regions. Using multiple publicly available dataset~\cite{song2017semantic,Silberman:ECCV12} we benchmark our method against existing approaches and are able to obtain superior performance. We further demonstrate the flexibility of our method by presenting results for new view synthesis of RGB-D images.
TemplateNet for Depth-Based Object Instance Recognition
Nov 10, 2015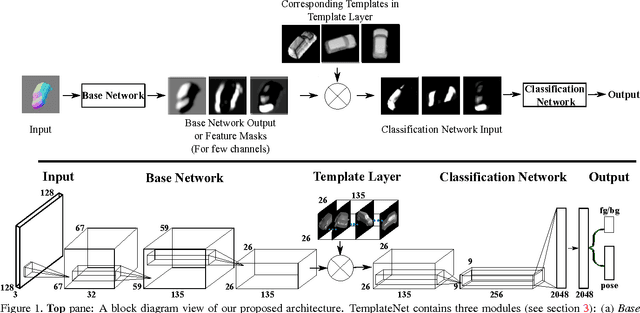

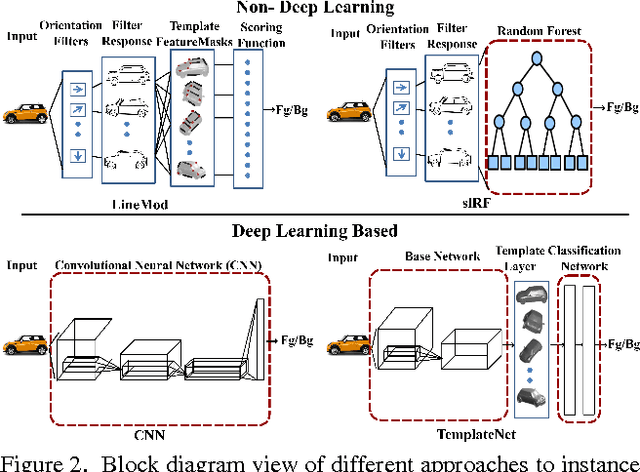
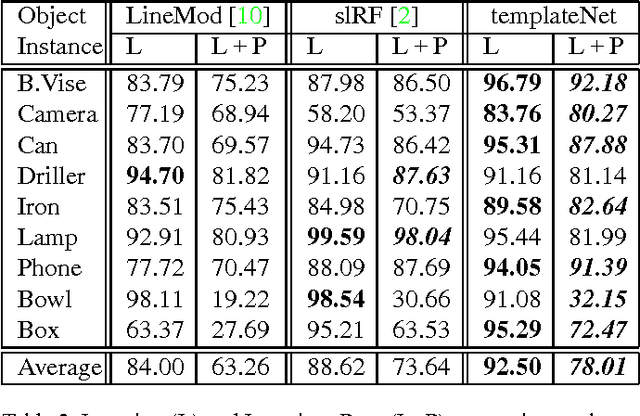
We present a novel deep architecture termed templateNet for depth based object instance recognition. Using an intermediate template layer we exploit prior knowledge of an object's shape to sparsify the feature maps. This has three advantages: (i) the network is better regularised resulting in structured filters; (ii) the sparse feature maps results in intuitive features been learnt which can be visualized as the output of the template layer and (iii) the resulting network achieves state-of-the-art performance. The network benefits from this without any additional parametrization from the template layer. We derive the weight updates needed to efficiently train this network in an end-to-end manner. We benchmark the templateNet for depth based object instance recognition using two publicly available datasets. The datasets present multiple challenges of clutter, large pose variations and similar looking distractors. Through our experiments we show that with the addition of a template layer, a depth based CNN is able to outperform existing state-of-the-art methods in the field.