 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemplateNet for Depth-Based Object Instance Recognition
Paper and Code
Nov 10, 2015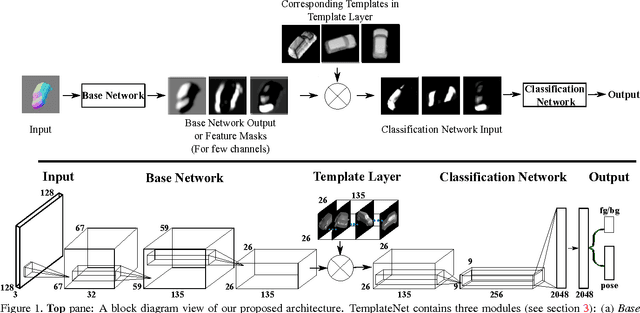

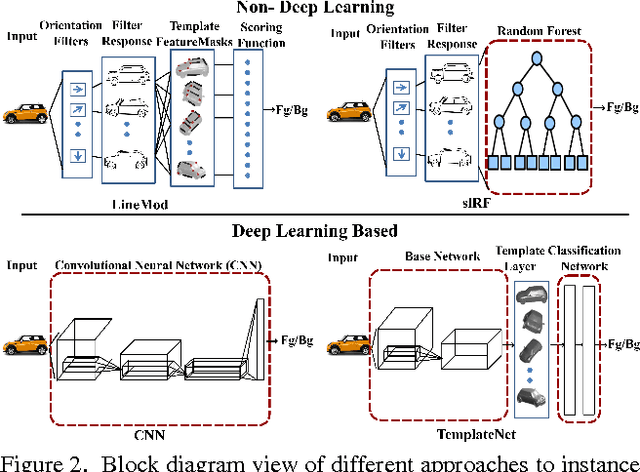
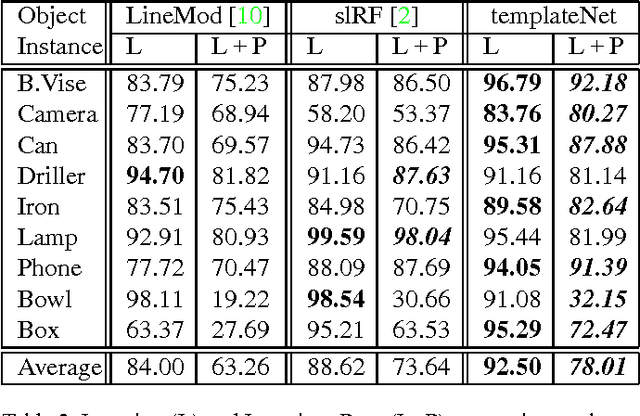
We present a novel deep architecture termed templateNet for depth based object instance recognition. Using an intermediate template layer we exploit prior knowledge of an object's shape to sparsify the feature maps. This has three advantages: (i) the network is better regularised resulting in structured filters; (ii) the sparse feature maps results in intuitive features been learnt which can be visualized as the output of the template layer and (iii) the resulting network achieves state-of-the-art performance. The network benefits from this without any additional parametrization from the template layer. We derive the weight updates needed to efficiently train this network in an end-to-end manner. We benchmark the templateNet for depth based object instance recognition using two publicly available datasets. The datasets present multiple challenges of clutter, large pose variations and similar looking distractors. Through our experiments we show that with the addition of a template layer, a depth based CNN is able to outperform existing state-of-the-art methods in the field.