 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingoQA: Video Question Answering for Autonomous Driving
Dec 21, 2023Autonomous driving has long faced a challenge with public acceptance due to the lack of explainability in the decision-making process. Video question-answering (QA) in natural language provides the opportunity for bridging this gap. Nonetheless, evaluating the performance of Video QA models has proved particularly tough due to the absence of comprehensive benchmarks. To fill this gap, we introduce LingoQA, a benchmark specifically for autonomous driving Video QA. The LingoQA trainable metric demonstrates a 0.95 Spearman correlation coefficient with human evaluations. We introduce a Video QA dataset of central London consisting of 419k samples that we release with the paper. We establish a baseline vision-language model and run extensive ablation studies to understand its performance.
Linking vision and motion for self-supervised object-centric perception
Jul 14, 2023Object-centric representations enable autonomous driving algorithms to reason about interactions between many independent agents and scene features. Traditionally these representations have been obtained via supervised learning, but this decouples perception from the downstream driving task and could harm generalization. In this work we adapt a self-supervised object-centric vision model to perform object decomposition using only RGB video and the pose of the vehicle as inputs. We demonstrate that our method obtains promising results on the Waymo Open perception dataset. While object mask quality lags behind supervised methods or alternatives that use more privileged information, we find that our model is capable of learning a representation that fuses multiple camera viewpoints over time and successfully tracks many vehicles and pedestrians in the dataset. Code for our model is available at https://github.com/wayveai/SOCS.
Reimagining an autonomous vehicle
Aug 12, 2021
The self driving challenge in 2021 is this century's technological equivalent of the space race, and is now entering the second major decade of development. Solving the technology will create social change which parallels the invention of the automobile itself. Today's autonomous driving technology is laudable, though rooted in decisions made a decade ago. We argue that a rethink is required, reconsidering the autonomous vehicle (AV) problem in the light of the body of knowledge that has been gained since the DARPA challenges which seeded the industry. What does AV2.0 look like? We present an alternative vision: a recipe for driving with machine learning, and grand challenges for research in driving.
FIERY: Future Instance Prediction in Bird's-Eye View from Surround Monocular Cameras
Apr 21, 2021
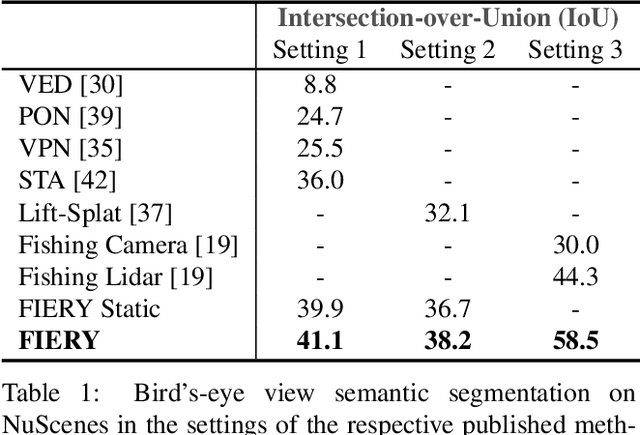
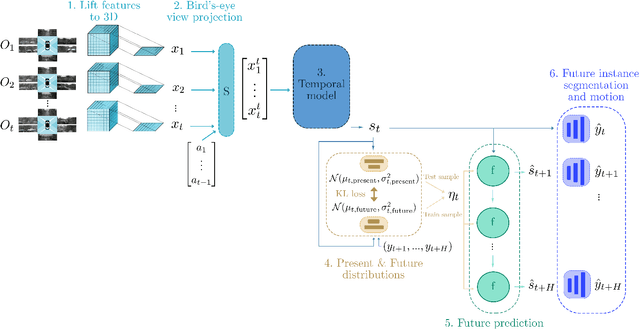
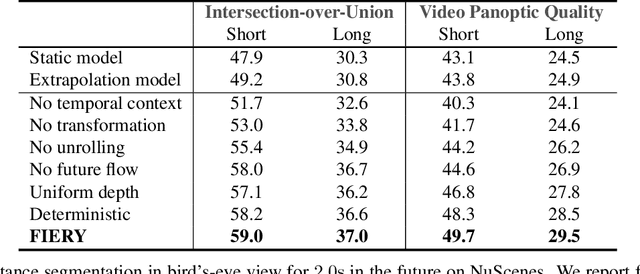
Driving requires interacting with road agents and predicting their future behaviour in order to navigate safely. We present FIERY: a probabilistic future prediction model in bird's-eye view from monocular cameras. Our model predicts future instance segmentation and motion of dynamic agents that can be transformed into non-parametric future trajectories. Our approach combines the perception, sensor fusion and prediction components of a traditional autonomous driving stack by estimating bird's-eye-view prediction directly from surround RGB monocular camera inputs. FIERY learns to model the inherent stochastic nature of the future directly from camera driving data in an end-to-end manner, without relying on HD maps, and predicts multimodal future trajectories. We show that our model outperforms previous prediction baselines on the NuScenes and Lyft datasets. Code is available at https://github.com/wayveai/fiery
Atlas: End-to-End 3D Scene Reconstruction from Posed Images
Mar 23, 2020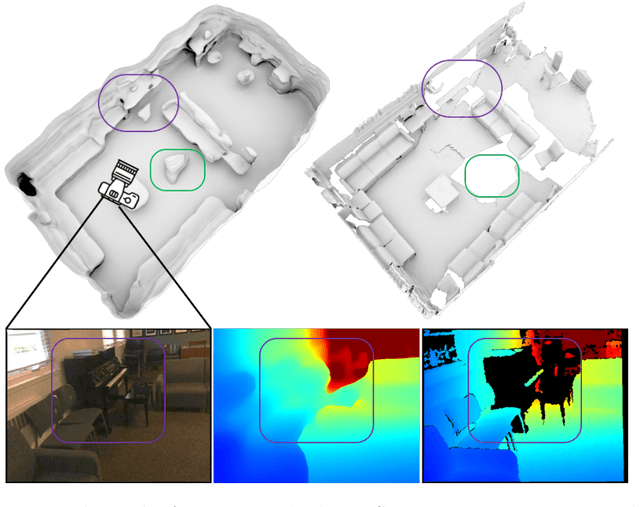
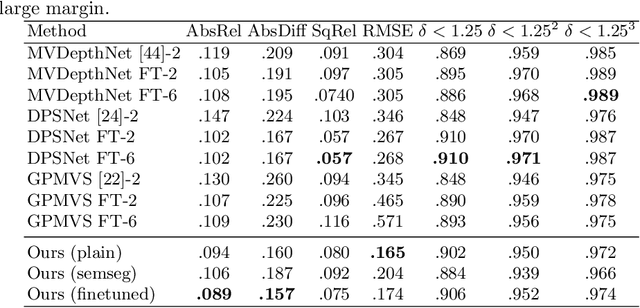
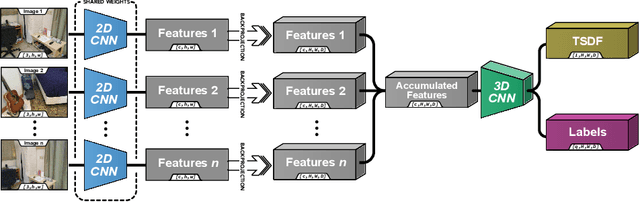
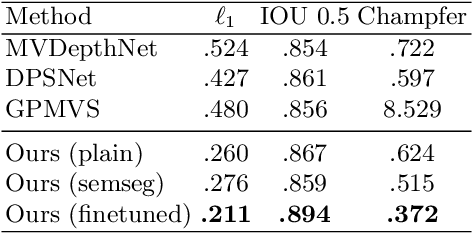
We present an end-to-end 3D reconstruction method for a scene by directly regressing a truncated signed distance function (TSDF) from a set of posed RGB images. Traditional approaches to 3D reconstruction rely on an intermediate representation of depth maps prior to estimating a full 3D model of a scene. We hypothesize that a direct regression to 3D is more effective. A 2D CNN extracts features from each image independently which are then back-projected and accumulated into a voxel volume using the camera intrinsics and extrinsics. After accumulation, a 3D CNN refines the accumulated features and predicts the TSDF values. Additionally, semantic segmentation of the 3D model is obtained without significant computation. This approach is evaluated on the Scannet dataset where we significantly outperform state-of-the-art baselines (deep multiview stereo followed by traditional TSDF fusion) both quantitatively and qualitatively. We compare our 3D semantic segmentation to prior methods that use a depth sensor since no previous work attempts the problem with only RGB input.
Depth Estimation by Learning Triangulation and Densification of Sparse Points for Multi-view Stereo
Mar 19, 2020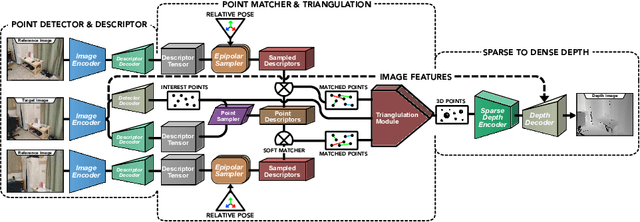
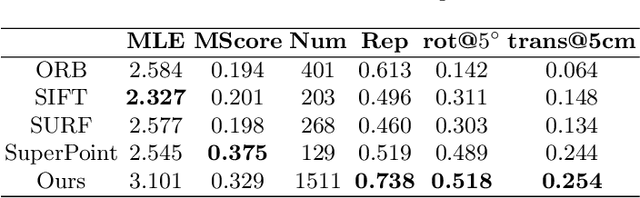
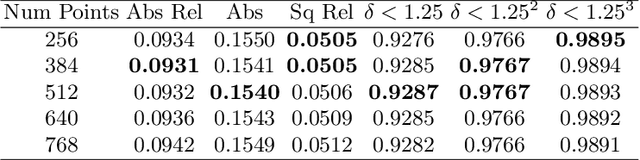

Multi-view stereo (MVS) is the golden mean between the accuracy of active depth sensing and the practicality of monocular depth estimation. Cost volume based approaches employing 3D convolutional neural networks (CNNs) have considerably improved the accuracy of MVS systems. However, this accuracy comes at a high computational cost which impedes practical adoption. Distinct from cost volume approaches, we propose an efficient depth estimation approach by first (a) detecting and evaluating descriptors for interest points, then (b) learning to match and triangulate a small set of interest points, and finally (c) densifying this sparse set of 3D points using CNNs. An end-to-end network efficiently performs all three steps within a deep learning framework and trained with intermediate 2D image and 3D geometric supervision, along with depth supervision. Crucially, our first step complements pose estimation using interest point detection and descriptor learning. We demonstrate that state-of-the-art results on depth estimation with lower compute for different scene lengths. Furthermore, our method generalizes to newer environments and the descriptors output by our network compare favorably to strong baselines.
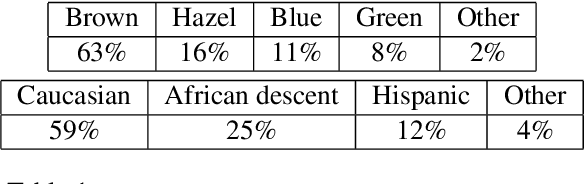
MagicEyes: A Large Scale Eye Gaze Estimation Dataset for Mixed Reality
Mar 18, 2020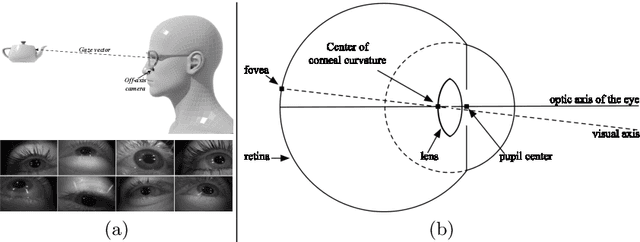
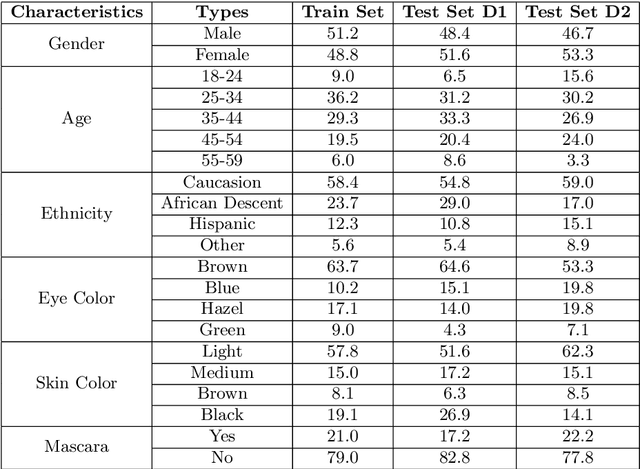

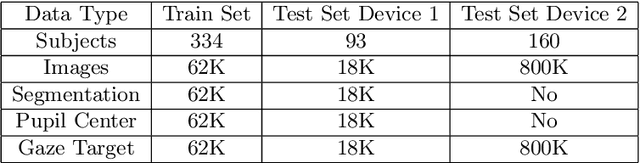
With the emergence of Virtual and Mixed Reality (XR) devices, eye tracking has received significant attention in the computer vision community. Eye gaze estimation is a crucial component in XR -- enabling energy efficient rendering, multi-focal displays, and effective interaction with content. In head-mounted XR devices, the eyes are imaged off-axis to avoid blocking the field of view. This leads to increased challenges in inferring eye related quantities and simultaneously provides an opportunity to develop accurate and robust learning based approaches. To this end, we present MagicEyes, the first large scale eye dataset collected using real MR devices with comprehensive ground truth labeling. MagicEyes includes $587$ subjects with $80,000$ images of human-labeled ground truth and over $800,000$ images with gaze target labels. We evaluate several state-of-the-art methods on MagicEyes and also propose a new multi-task EyeNet model designed for detecting the cornea, glints and pupil along with eye segmentation in a single forward pass.
Scan2Plan: Efficient Floorplan Generation from 3D Scans of Indoor Scenes
Mar 16, 2020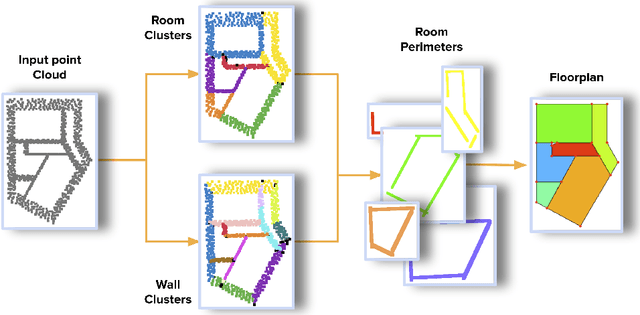
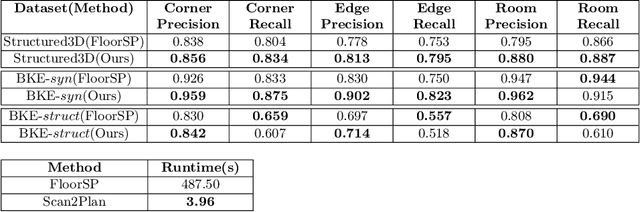
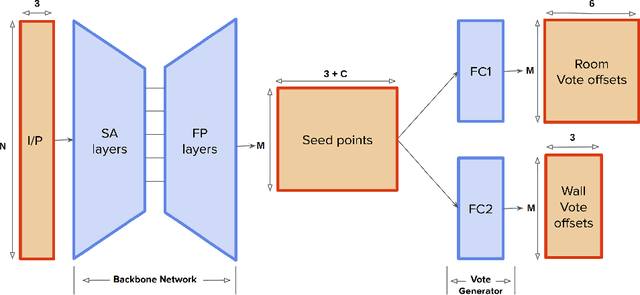
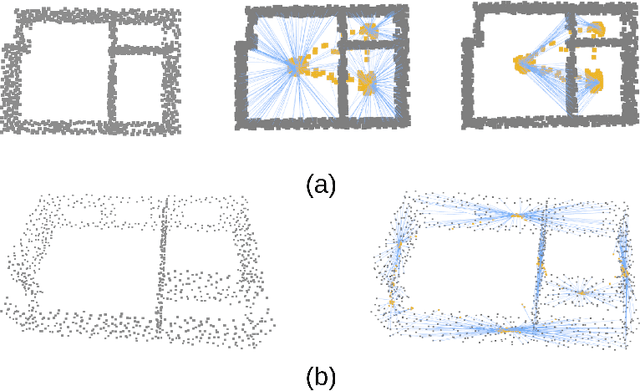
We introduce Scan2Plan, a novel approach for accurate estimation of a floorplan from a 3D scan of the structural elements of indoor environments. The proposed method incorporates a two-stage approach where the initial stage clusters an unordered point cloud representation of the scene into room instances and wall instances using a deep neural network based voting approach. The subsequent stage estimates a closed perimeter, parameterized by a simple polygon, for each individual room by finding the shortest path along the predicted room and wall keypoints. The final floorplan is simply an assembly of all such room perimeters in the global co-ordinate system. The Scan2Plan pipeline produces accurate floorplans for complex layouts, is highly parallelizable and extremely efficient compared to existing methods. The voting module is trained only on synthetic data and evaluated on publicly available Structured3D and BKE datasets to demonstrate excellent qualitative and quantitative results outperforming state-of-the-art techniques.
EyeNet: A Multi-Task Network for Off-Axis Eye Gaze Estimation and User Understanding
Aug 24, 2019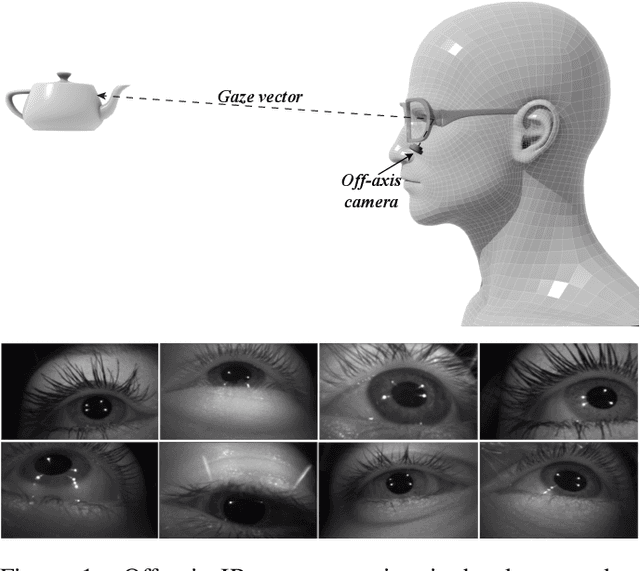
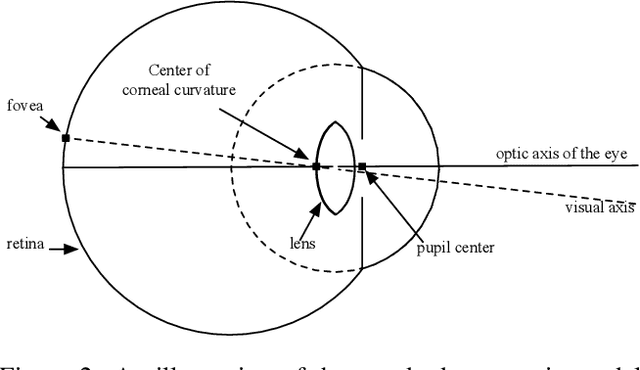
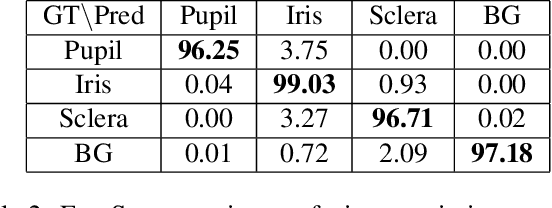
Eye gaze estimation and simultaneous semantic understanding of a user through eye images is a crucial component in Virtual and Mixed Reality; enabling energy efficient rendering, multi-focal displays and effective interaction with 3D content. In head-mounted VR/MR devices the eyes are imaged off-axis to avoid blocking the user's gaze, this view-point makes drawing eye related inferences very challenging. In this work, we present EyeNet, the first single deep neural network which solves multiple heterogeneous tasks related to eye gaze estimation and semantic user understanding for an off-axis camera setting. The tasks include eye segmentation, blink detection, emotive expression classification, IR LED glints detection, pupil and cornea center estimation. To train EyeNet end-to-end we employ both hand labelled supervision and model based supervision. We benchmark all tasks on MagicEyes, a large and new dataset of 587 subjects with varying morphology, gender, skin-color, make-up and imaging conditions.
DeepPerimeter: Indoor Boundary Estimation from Posed Monocular Sequences
Apr 25, 2019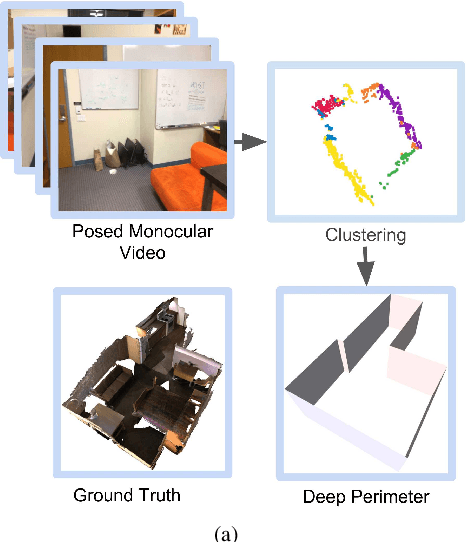
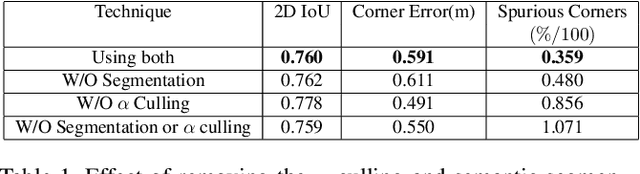
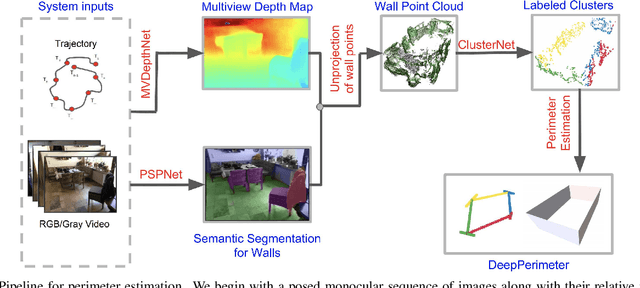
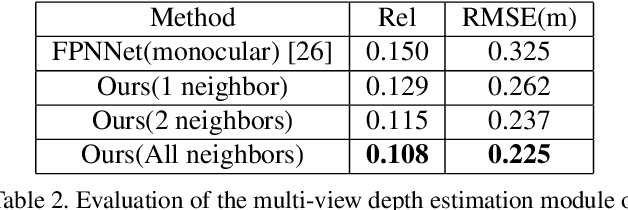
We present DeepPerimeter, a deep learning based pipeline for inferring a full indoor perimeter (i.e. exterior boundary map) from a sequence of posed RGB images. Our method relies on robust deep methods for depth estimation and wall segmentation to generate an exterior boundary point cloud, and then uses deep unsupervised clustering to fit wall planes to obtain a final boundary map of the room. We demonstrate that DeepPerimeter results in excellent visual and quantitative performance on the popular ScanNet and FloorNet datasets and works for room shapes of various complexities as well as in multiroom scenarios. We also establish important baselines for future work on indoor perimeter estimation, topics which will become increasingly prevalent as application areas like augmented reality and robotics become more significant.