 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtlas: End-to-End 3D Scene Reconstruction from Posed Images
Mar 23, 2020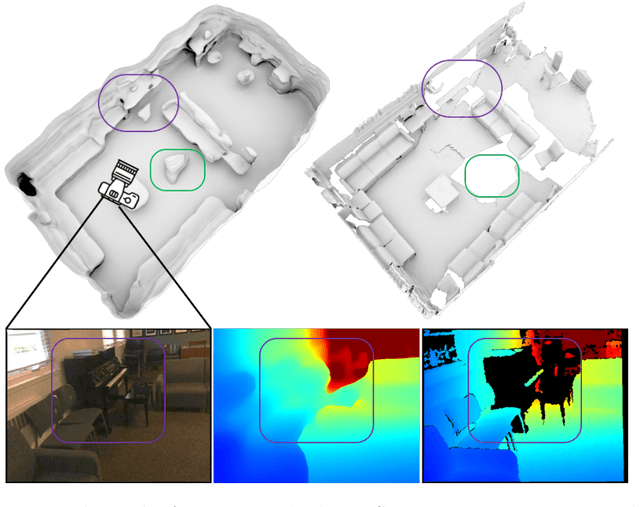
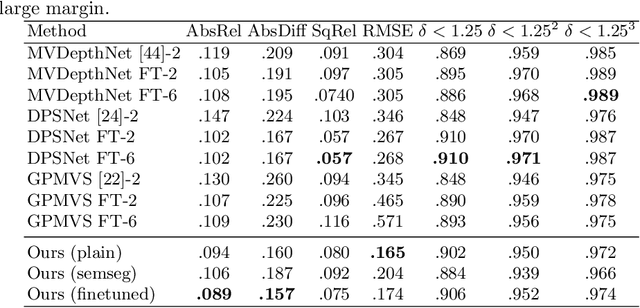
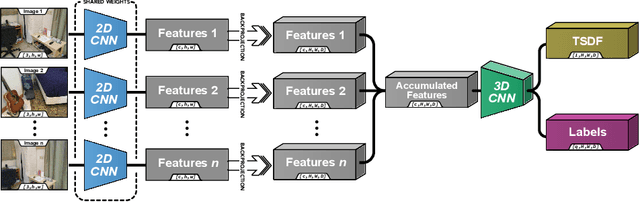
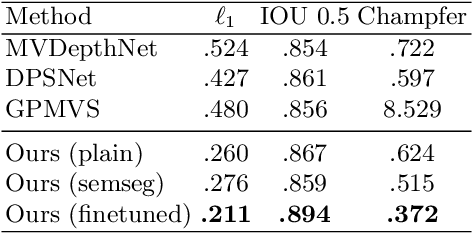
We present an end-to-end 3D reconstruction method for a scene by directly regressing a truncated signed distance function (TSDF) from a set of posed RGB images. Traditional approaches to 3D reconstruction rely on an intermediate representation of depth maps prior to estimating a full 3D model of a scene. We hypothesize that a direct regression to 3D is more effective. A 2D CNN extracts features from each image independently which are then back-projected and accumulated into a voxel volume using the camera intrinsics and extrinsics. After accumulation, a 3D CNN refines the accumulated features and predicts the TSDF values. Additionally, semantic segmentation of the 3D model is obtained without significant computation. This approach is evaluated on the Scannet dataset where we significantly outperform state-of-the-art baselines (deep multiview stereo followed by traditional TSDF fusion) both quantitatively and qualitatively. We compare our 3D semantic segmentation to prior methods that use a depth sensor since no previous work attempts the problem with only RGB input.
MagicEyes: A Large Scale Eye Gaze Estimation Dataset for Mixed Reality
Mar 18, 2020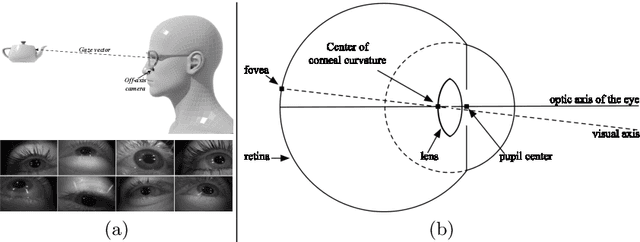
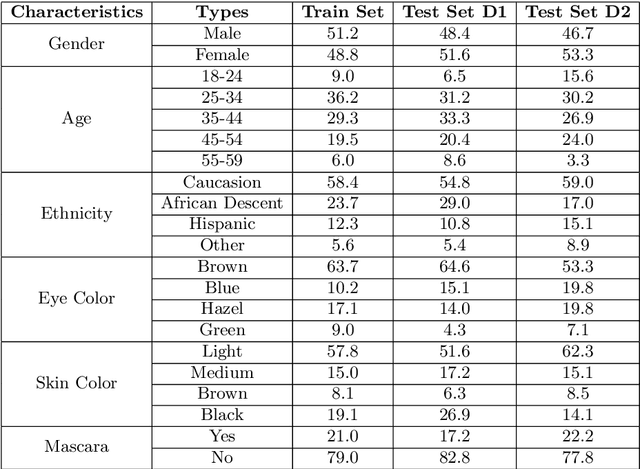

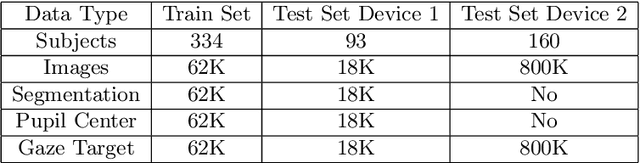
With the emergence of Virtual and Mixed Reality (XR) devices, eye tracking has received significant attention in the computer vision community. Eye gaze estimation is a crucial component in XR -- enabling energy efficient rendering, multi-focal displays, and effective interaction with content. In head-mounted XR devices, the eyes are imaged off-axis to avoid blocking the field of view. This leads to increased challenges in inferring eye related quantities and simultaneously provides an opportunity to develop accurate and robust learning based approaches. To this end, we present MagicEyes, the first large scale eye dataset collected using real MR devices with comprehensive ground truth labeling. MagicEyes includes $587$ subjects with $80,000$ images of human-labeled ground truth and over $800,000$ images with gaze target labels. We evaluate several state-of-the-art methods on MagicEyes and also propose a new multi-task EyeNet model designed for detecting the cornea, glints and pupil along with eye segmentation in a single forward pass.
EyeNet: A Multi-Task Network for Off-Axis Eye Gaze Estimation and User Understanding
Aug 24, 2019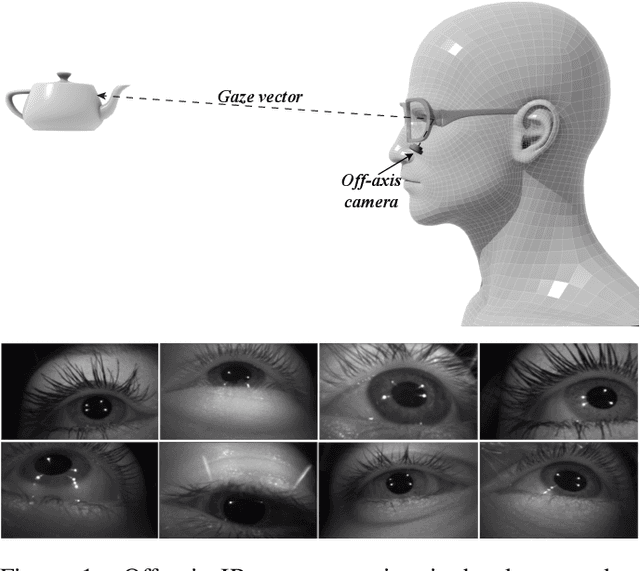
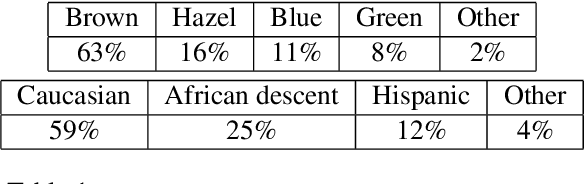
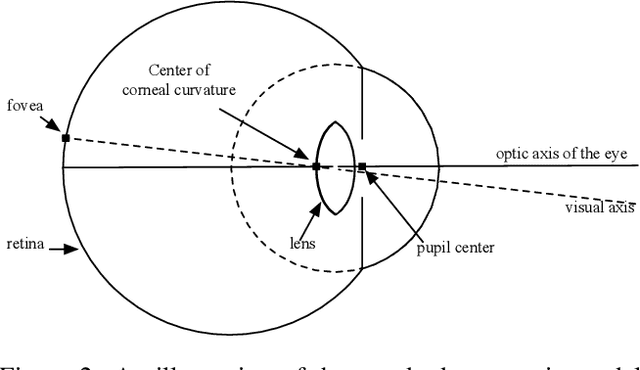
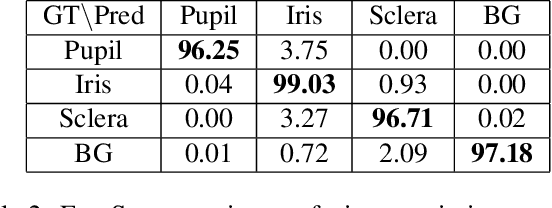
Eye gaze estimation and simultaneous semantic understanding of a user through eye images is a crucial component in Virtual and Mixed Reality; enabling energy efficient rendering, multi-focal displays and effective interaction with 3D content. In head-mounted VR/MR devices the eyes are imaged off-axis to avoid blocking the user's gaze, this view-point makes drawing eye related inferences very challenging. In this work, we present EyeNet, the first single deep neural network which solves multiple heterogeneous tasks related to eye gaze estimation and semantic user understanding for an off-axis camera setting. The tasks include eye segmentation, blink detection, emotive expression classification, IR LED glints detection, pupil and cornea center estimation. To train EyeNet end-to-end we employ both hand labelled supervision and model based supervision. We benchmark all tasks on MagicEyes, a large and new dataset of 587 subjects with varying morphology, gender, skin-color, make-up and imaging conditions.