 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtlas: End-to-End 3D Scene Reconstruction from Posed Images
Mar 23, 2020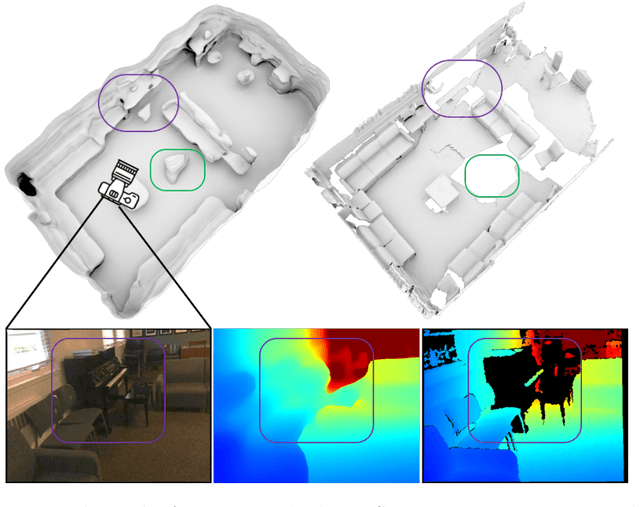
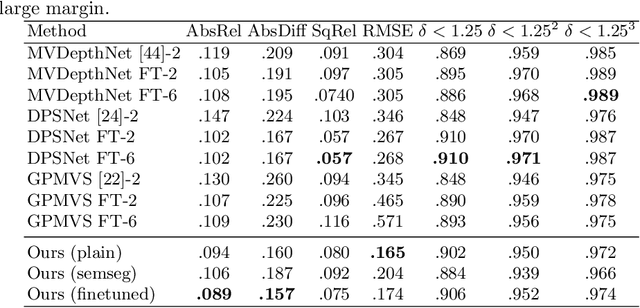
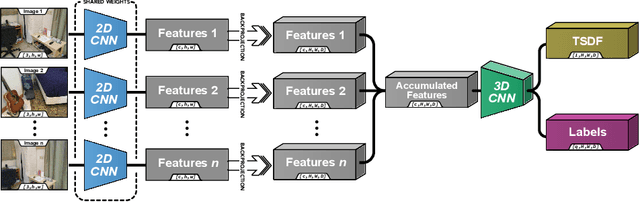
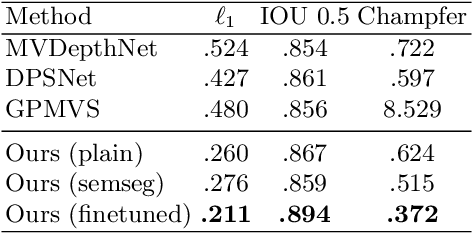
We present an end-to-end 3D reconstruction method for a scene by directly regressing a truncated signed distance function (TSDF) from a set of posed RGB images. Traditional approaches to 3D reconstruction rely on an intermediate representation of depth maps prior to estimating a full 3D model of a scene. We hypothesize that a direct regression to 3D is more effective. A 2D CNN extracts features from each image independently which are then back-projected and accumulated into a voxel volume using the camera intrinsics and extrinsics. After accumulation, a 3D CNN refines the accumulated features and predicts the TSDF values. Additionally, semantic segmentation of the 3D model is obtained without significant computation. This approach is evaluated on the Scannet dataset where we significantly outperform state-of-the-art baselines (deep multiview stereo followed by traditional TSDF fusion) both quantitatively and qualitatively. We compare our 3D semantic segmentation to prior methods that use a depth sensor since no previous work attempts the problem with only RGB input.
Depth Estimation by Learning Triangulation and Densification of Sparse Points for Multi-view Stereo
Mar 19, 2020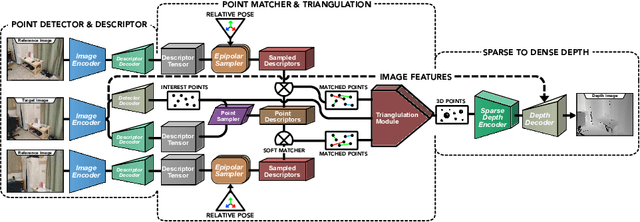
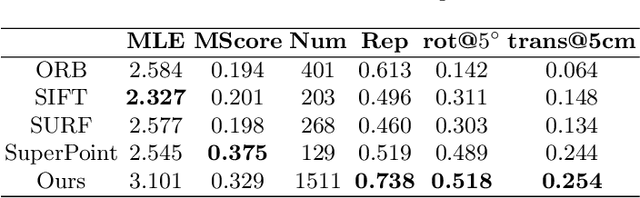
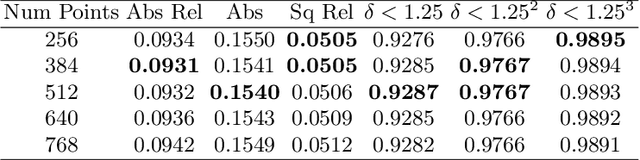

Multi-view stereo (MVS) is the golden mean between the accuracy of active depth sensing and the practicality of monocular depth estimation. Cost volume based approaches employing 3D convolutional neural networks (CNNs) have considerably improved the accuracy of MVS systems. However, this accuracy comes at a high computational cost which impedes practical adoption. Distinct from cost volume approaches, we propose an efficient depth estimation approach by first (a) detecting and evaluating descriptors for interest points, then (b) learning to match and triangulate a small set of interest points, and finally (c) densifying this sparse set of 3D points using CNNs. An end-to-end network efficiently performs all three steps within a deep learning framework and trained with intermediate 2D image and 3D geometric supervision, along with depth supervision. Crucially, our first step complements pose estimation using interest point detection and descriptor learning. We demonstrate that state-of-the-art results on depth estimation with lower compute for different scene lengths. Furthermore, our method generalizes to newer environments and the descriptors output by our network compare favorably to strong baselines.
Efficient 2.5D Hand Pose Estimation via Auxiliary Multi-Task Training for Embedded Devices
Sep 12, 2019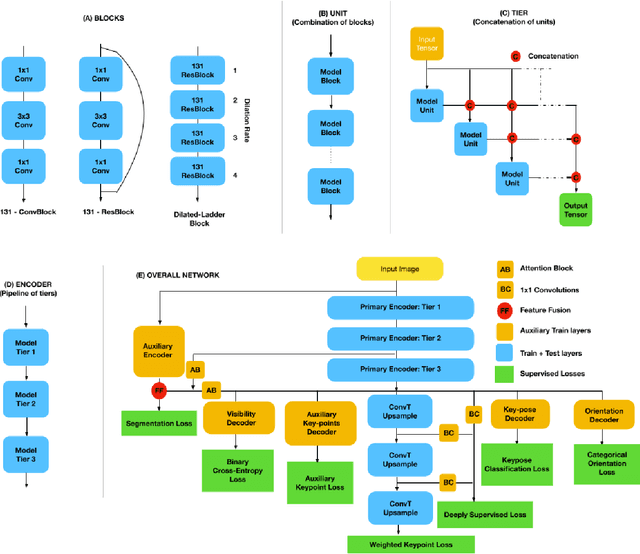
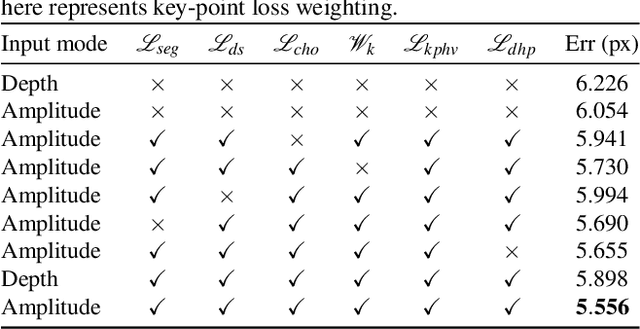

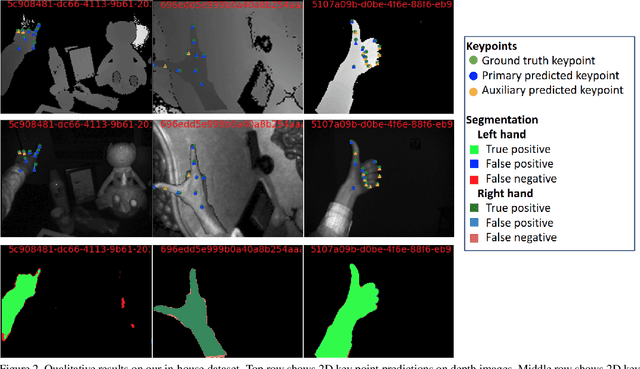
2D Key-point estimation is an important precursor to 3D pose estimation problems for human body and hands. In this work, we discuss the data, architecture, and training procedure necessary to deploy extremely efficient 2.5D hand pose estimation on embedded devices with highly constrained memory and compute envelope, such as AR/VR wearables. Our 2.5D hand pose estimation consists of 2D key-point estimation of joint positions on an egocentric image, captured by a depth sensor, and lifted to 2.5D using the corresponding depth values. Our contributions are two fold: (a) We discuss data labeling and augmentation strategies, the modules in the network architecture that collectively lead to $3\%$ the flop count and $2\%$ the number of parameters when compared to the state of the art MobileNetV2 architecture. (b) We propose an auxiliary multi-task training strategy needed to compensate for the small capacity of the network while achieving comparable performance to MobileNetV2. Our 32-bit trained model has a memory footprint of less than 300 Kilobytes, operates at more than 50 Hz with less than 35 MFLOPs.
Gradient Adversarial Training of Neural Networks
Jun 21, 2018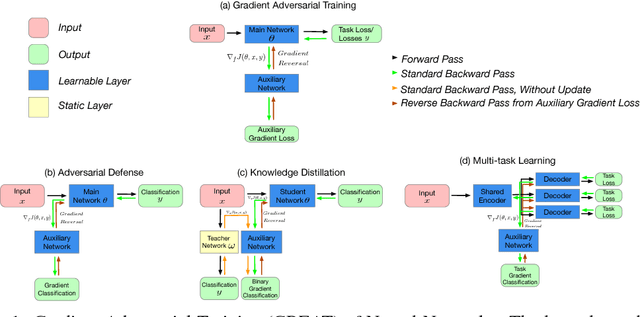
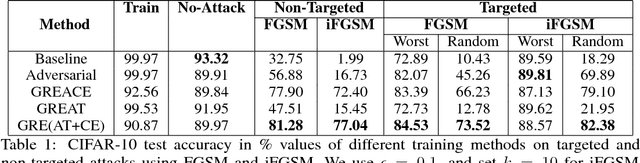
We propose gradient adversarial training, an auxiliary deep learning framework applicable to different machine learning problems. In gradient adversarial training, we leverage a prior belief that in many contexts, simultaneous gradient updates should be statistically indistinguishable from each other. We enforce this consistency using an auxiliary network that classifies the origin of the gradient tensor, and the main network serves as an adversary to the auxiliary network in addition to performing standard task-based training. We demonstrate gradient adversarial training for three different scenarios: (1) as a defense to adversarial examples we classify gradient tensors and tune them to be agnostic to the class of their corresponding example, (2) for knowledge distillation, we do binary classification of gradient tensors derived from the student or teacher network and tune the student gradient tensor to mimic the teacher's gradient tensor; and (3) for multi-task learning we classify the gradient tensors derived from different task loss functions and tune them to be statistically indistinguishable. For each of the three scenarios we show the potential of gradient adversarial training procedure. Specifically, gradient adversarial training increases the robustness of a network to adversarial attacks, is able to better distill the knowledge from a teacher network to a student network compared to soft targets, and boosts multi-task learning by aligning the gradient tensors derived from the task specific loss functions. Overall, our experiments demonstrate that gradient tensors contain latent information about whatever tasks are being trained, and can support diverse machine learning problems when intelligently guided through adversarialization using a auxiliary network.
Lensless computational imaging through deep learning
Jun 26, 2017

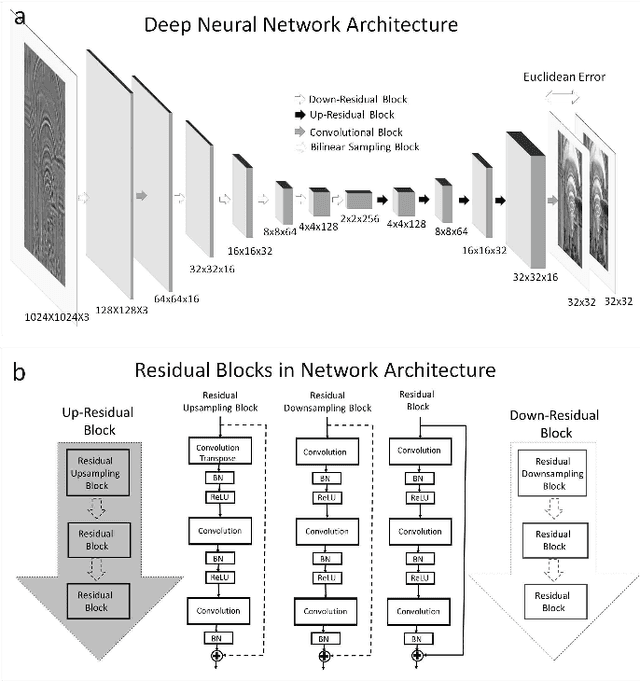
Deep learning has been proven to yield reliably generalizable answers to numerous classification and decision tasks. Here, we demonstrate for the first time, to our knowledge, that deep neural networks (DNNs) can be trained to solve inverse problems in computational imaging. We experimentally demonstrate a lens-less imaging system where a DNN was trained to recover a phase object given a raw intensity image recorded some distance away.
SurfNet: Generating 3D shape surfaces using deep residual networks
Mar 12, 2017
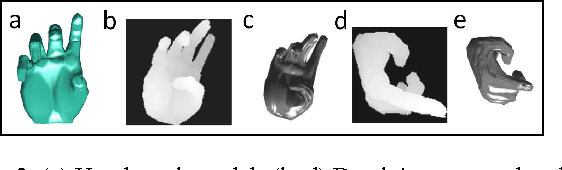
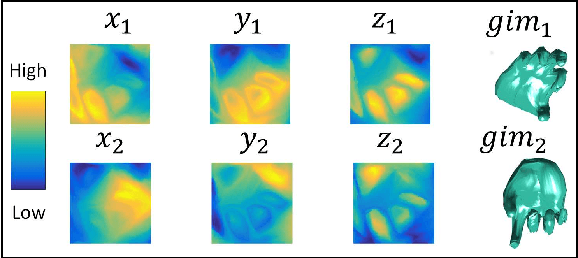
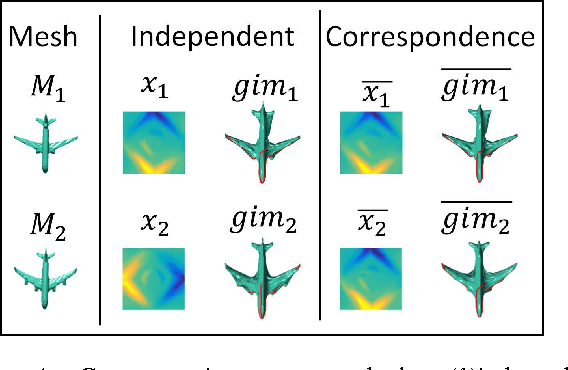
3D shape models are naturally parameterized using vertices and faces, \ie, composed of polygons forming a surface. However, current 3D learning paradigms for predictive and generative tasks using convolutional neural networks focus on a voxelized representation of the object. Lifting convolution operators from the traditional 2D to 3D results in high computational overhead with little additional benefit as most of the geometry information is contained on the surface boundary. Here we study the problem of directly generating the 3D shape surface of rigid and non-rigid shapes using deep convolutional neural networks. We develop a procedure to create consistent `geometry images' representing the shape surface of a category of 3D objects. We then use this consistent representation for category-specific shape surface generation from a parametric representation or an image by developing novel extensions of deep residual networks for the task of geometry image generation. Our experiments indicate that our network learns a meaningful representation of shape surfaces allowing it to interpolate between shape orientations and poses, invent new shape surfaces and reconstruct 3D shape surfaces from previously unseen images.