 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechVerse: Evaluating Physical Motion Consistency in Video Generation Models
May 14, 2026Text- and image-conditioned video generation models have achieved strong visual fidelity and temporal coherence, but they often fail to generate motion governed by kinematic and geometric constraints. In these settings, object parts must remain rigid, maintain contact or coupling with neighboring components, and transfer motion consistently across connected parts. These requirements are especially explicit in articulated mechanical assemblies, where motion is constrained by rigid-link geometry, contact/coupling relations, and transmission through kinematic chains. A generated video may therefore appear plausible while violating the intended mechanism, such as rotating a part that should translate, deforming a rigid component, breaking coupling between parts, or failing to move downstream components. To evaluate this gap, We introduce MechVerse, a benchmark for mechanically consistent image-to-video generation. MechVerse contains 21,156 synthetic clips from 1,357 mechanical assemblies across 141 categories, organized into three tiers of increasing kinematic complexity: independent articulation, pairwise coupling, and densely coupled multi-part mechanisms. Each clip is paired with a structured prompt describing part identities, stationary supports, moving components, motion primitives, direction, speed/extent, and inter-part dependencies. We evaluate proprietary, open-source, and fine-tuned image-to-video models using standard video metrics, instruction-following scores, and human judgments of motion correctness and kinematic coupling. Results show that current models can preserve appearance and smoothness while failing to generate mechanically admissible motion, with errors increasing as coupling complexity grows. MechVerse provides a benchmark for measuring and improving mechanism-aware video generation from image and language inputs.
Exploring Vision-Language Models for Open-Vocabulary Zero-Shot Action Segmentation
Feb 24, 2026Temporal Action Segmentation (TAS) requires dividing videos into action segments, yet the vast space of activities and alternative breakdowns makes collecting comprehensive datasets infeasible. Existing methods remain limited to closed vocabularies and fixed label sets. In this work, we explore the largely unexplored problem of Open-Vocabulary Zero-Shot Temporal Action Segmentation (OVTAS) by leveraging the strong zero-shot capabilities of Vision-Language Models (VLMs). We introduce a training-free pipeline that follows a segmentation-by-classification design: Frame-Action Embedding Similarity (FAES) matches video frames to candidate action labels, and Similarity-Matrix Temporal Segmentation (SMTS) enforces temporal consistency. Beyond proposing OVTAS, we present a systematic study across 14 diverse VLMs, providing the first broad analysis of their suitability for open-vocabulary action segmentation. Experiments on standard benchmarks show that OVTAS achieves strong results without task-specific supervision, underscoring the potential of VLMs for structured temporal understanding.
Towards Natural Language Environment: Understanding Seamless Natural-Language-Based Human-Multi-Robot Interactions
Jan 19, 2026As multiple robots are expected to coexist in future households, natural language is increasingly envisioned as a primary medium for human-robot and robot-robot communication. This paper introduces the concept of a Natural Language Environment (NLE), defined as an interaction space in which humans and multiple heterogeneous robots coordinate primarily through natural language. Rather than proposing a deployable system, this work aims to explore the design space of such environments. We first synthesize prior work on language-based human-robot interaction to derive a preliminary design space for NLEs. We then conduct a role-playing study in virtual reality to investigate how people conceptualize, negotiate, and coordinate human-multi-robot interactions within this imagined environment. Based on qualitative and quantitative analysis, we refine the preliminary design space and derive design implications that highlight key tensions and opportunities around task coordination dominance, robot autonomy, and robot personality in Natural Language Environments.
DYNAMO: Dependency-Aware Deep Learning Framework for Articulated Assembly Motion Prediction
Sep 15, 2025Understanding the motion of articulated mechanical assemblies from static geometry remains a core challenge in 3D perception and design automation. Prior work on everyday articulated objects such as doors and laptops typically assumes simplified kinematic structures or relies on joint annotations. However, in mechanical assemblies like gears, motion arises from geometric coupling, through meshing teeth or aligned axes, making it difficult for existing methods to reason about relational motion from geometry alone. To address this gap, we introduce MechBench, a benchmark dataset of 693 diverse synthetic gear assemblies with part-wise ground-truth motion trajectories. MechBench provides a structured setting to study coupled motion, where part dynamics are induced by contact and transmission rather than predefined joints. Building on this, we propose DYNAMO, a dependency-aware neural model that predicts per-part SE(3) motion trajectories directly from segmented CAD point clouds. Experiments show that DYNAMO outperforms strong baselines, achieving accurate and temporally consistent predictions across varied gear configurations. Together, MechBench and DYNAMO establish a novel systematic framework for data-driven learning of coupled mechanical motion in CAD assemblies.
CATSplat: Context-Aware Transformer with Spatial Guidance for Generalizable 3D Gaussian Splatting from A Single-View Image
Dec 17, 2024



Recently, generalizable feed-forward methods based on 3D Gaussian Splatting have gained significant attention for their potential to reconstruct 3D scenes using finite resources. These approaches create a 3D radiance field, parameterized by per-pixel 3D Gaussian primitives, from just a few images in a single forward pass. However, unlike multi-view methods that benefit from cross-view correspondences, 3D scene reconstruction with a single-view image remains an underexplored area. In this work, we introduce CATSplat, a novel generalizable transformer-based framework designed to break through the inherent constraints in monocular settings. First, we propose leveraging textual guidance from a visual-language model to complement insufficient information from a single image. By incorporating scene-specific contextual details from text embeddings through cross-attention, we pave the way for context-aware 3D scene reconstruction beyond relying solely on visual cues. Moreover, we advocate utilizing spatial guidance from 3D point features toward comprehensive geometric understanding under single-view settings. With 3D priors, image features can capture rich structural insights for predicting 3D Gaussians without multi-view techniques. Extensive experiments on large-scale datasets demonstrate the state-of-the-art performance of CATSplat in single-view 3D scene reconstruction with high-quality novel view synthesis.
Estimating Ego-Body Pose from Doubly Sparse Egocentric Video Data
Nov 05, 2024



We study the problem of estimating the body movements of a camera wearer from egocentric videos. Current methods for ego-body pose estimation rely on temporally dense sensor data, such as IMU measurements from spatially sparse body parts like the head and hands. However, we propose that even temporally sparse observations, such as hand poses captured intermittently from egocentric videos during natural or periodic hand movements, can effectively constrain overall body motion. Naively applying diffusion models to generate full-body pose from head pose and sparse hand pose leads to suboptimal results. To overcome this, we develop a two-stage approach that decomposes the problem into temporal completion and spatial completion. First, our method employs masked autoencoders to impute hand trajectories by leveraging the spatiotemporal correlations between the head pose sequence and intermittent hand poses, providing uncertainty estimates. Subsequently, we employ conditional diffusion models to generate plausible full-body motions based on these temporally dense trajectories of the head and hands, guided by the uncertainty estimates from the imputation. The effectiveness of our method was rigorously tested and validated through comprehensive experiments conducted on various HMD setup with AMASS and Ego-Exo4D datasets.
M2D2M: Multi-Motion Generation from Text with Discrete Diffusion Models
Jul 19, 2024



We introduce the Multi-Motion Discrete Diffusion Models (M2D2M), a novel approach for human motion generation from textual descriptions of multiple actions, utilizing the strengths of discrete diffusion models. This approach adeptly addresses the challenge of generating multi-motion sequences, ensuring seamless transitions of motions and coherence across a series of actions. The strength of M2D2M lies in its dynamic transition probability within the discrete diffusion model, which adapts transition probabilities based on the proximity between motion tokens, encouraging mixing between different modes. Complemented by a two-phase sampling strategy that includes independent and joint denoising steps, M2D2M effectively generates long-term, smooth, and contextually coherent human motion sequences, utilizing a model trained for single-motion generation. Extensive experiments demonstrate that M2D2M surpasses current state-of-the-art benchmarks for motion generation from text descriptions, showcasing its efficacy in interpreting language semantics and generating dynamic, realistic motions.
InfoGCN++: Learning Representation by Predicting the Future for Online Human Skeleton-based Action Recognition
Oct 16, 2023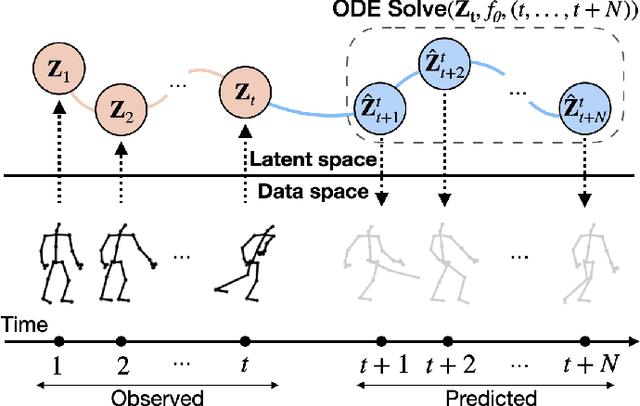
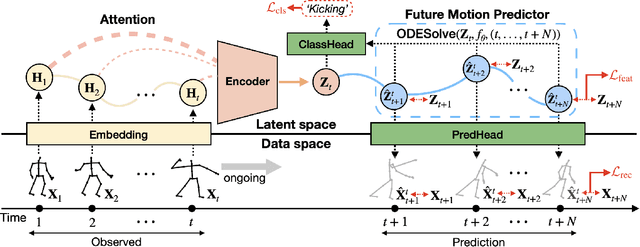
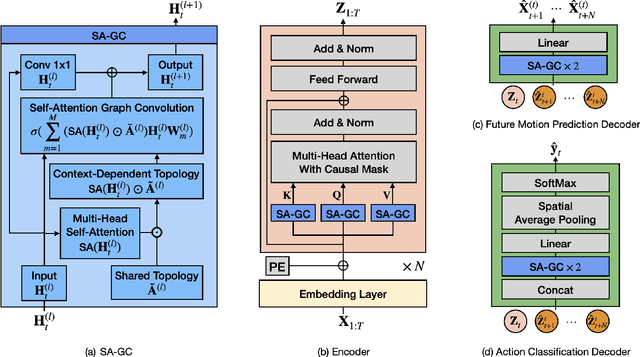
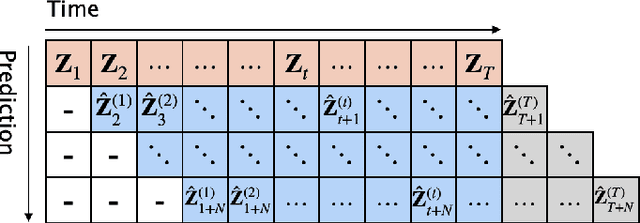
Skeleton-based action recognition has made significant advancements recently, with models like InfoGCN showcasing remarkable accuracy. However, these models exhibit a key limitation: they necessitate complete action observation prior to classification, which constrains their applicability in real-time situations such as surveillance and robotic systems. To overcome this barrier, we introduce InfoGCN++, an innovative extension of InfoGCN, explicitly developed for online skeleton-based action recognition. InfoGCN++ augments the abilities of the original InfoGCN model by allowing real-time categorization of action types, independent of the observation sequence's length. It transcends conventional approaches by learning from current and anticipated future movements, thereby creating a more thorough representation of the entire sequence. Our approach to prediction is managed as an extrapolation issue, grounded on observed actions. To enable this, InfoGCN++ incorporates Neural Ordinary Differential Equations, a concept that lets it effectively model the continuous evolution of hidden states. Following rigorous evaluations on three skeleton-based action recognition benchmarks, InfoGCN++ demonstrates exceptional performance in online action recognition. It consistently equals or exceeds existing techniques, highlighting its significant potential to reshape the landscape of real-time action recognition applications. Consequently, this work represents a major leap forward from InfoGCN, pushing the limits of what's possible in online, skeleton-based action recognition. The code for InfoGCN++ is publicly available at https://github.com/stnoah1/infogcn2 for further exploration and validation.
AircraftVerse: A Large-Scale Multimodal Dataset of Aerial Vehicle Designs
Jun 08, 2023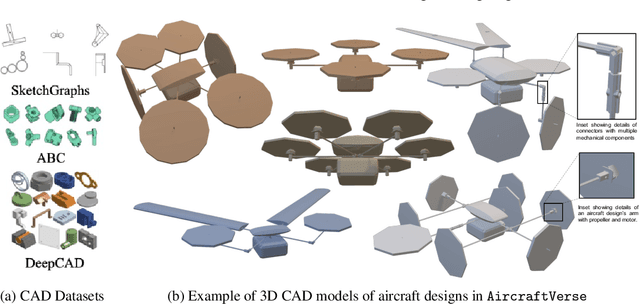
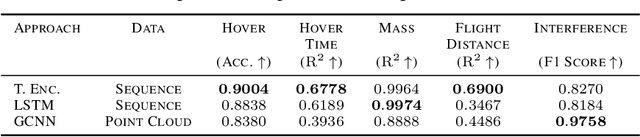
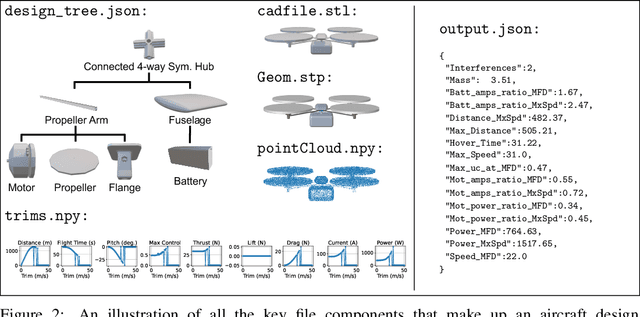

We present AircraftVerse, a publicly available aerial vehicle design dataset. Aircraft design encompasses different physics domains and, hence, multiple modalities of representation. The evaluation of these cyber-physical system (CPS) designs requires the use of scientific analytical and simulation models ranging from computer-aided design tools for structural and manufacturing analysis, computational fluid dynamics tools for drag and lift computation, battery models for energy estimation, and simulation models for flight control and dynamics. AircraftVerse contains 27,714 diverse air vehicle designs - the largest corpus of engineering designs with this level of complexity. Each design comprises the following artifacts: a symbolic design tree describing topology, propulsion subsystem, battery subsystem, and other design details; a STandard for the Exchange of Product (STEP) model data; a 3D CAD design using a stereolithography (STL) file format; a 3D point cloud for the shape of the design; and evaluation results from high fidelity state-of-the-art physics models that characterize performance metrics such as maximum flight distance and hover-time. We also present baseline surrogate models that use different modalities of design representation to predict design performance metrics, which we provide as part of our dataset release. Finally, we discuss the potential impact of this dataset on the use of learning in aircraft design and, more generally, in CPS. AircraftVerse is accompanied by a data card, and it is released under Creative Commons Attribution-ShareAlike (CC BY-SA) license. The dataset is hosted at https://zenodo.org/record/6525446, baseline models and code at https://github.com/SRI-CSL/AircraftVerse, and the dataset description at https://aircraftverse.onrender.com/.
Egocentric View Hand Action Recognition by Leveraging Hand Surface and Hand Grasp Type
Sep 08, 2021

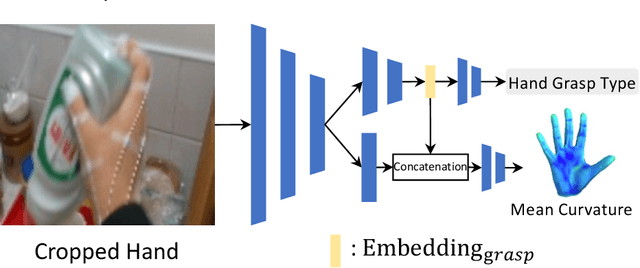

We introduce a multi-stage framework that uses mean curvature on a hand surface and focuses on learning interaction between hand and object by analyzing hand grasp type for hand action recognition in egocentric videos. The proposed method does not require 3D information of objects including 6D object poses which are difficult to annotate for learning an object's behavior while it interacts with hands. Instead, the framework synthesizes the mean curvature of the hand mesh model to encode the hand surface geometry in 3D space. Additionally, our method learns the hand grasp type which is highly correlated with the hand action. From our experiment, we notice that using hand grasp type and mean curvature of hand increases the performance of the hand action recognition.