 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound-Guided Semantic Video Generation
Apr 21, 2022
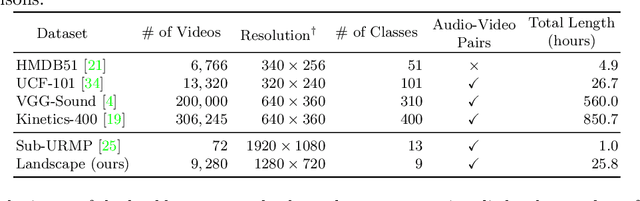
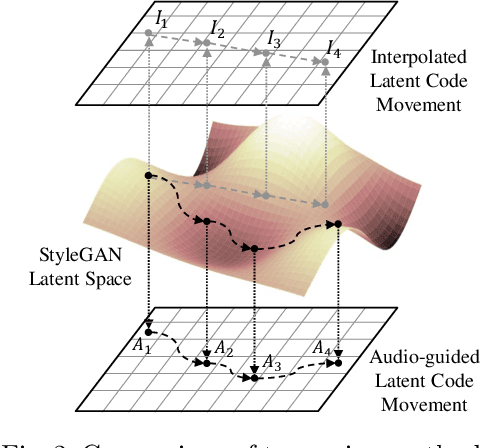

The recent success in StyleGAN demonstrates that pre-trained StyleGAN latent space is useful for realistic video generation. However, the generated motion in the video is usually not semantically meaningful due to the difficulty of determining the direction and magnitude in the StyleGAN latent space. In this paper, we propose a framework to generate realistic videos by leveraging multimodal (sound-image-text) embedding space. As sound provides the temporal contexts of the scene, our framework learns to generate a video that is semantically consistent with sound. First, our sound inversion module maps the audio directly into the StyleGAN latent space. We then incorporate the CLIP-based multimodal embedding space to further provide the audio-visual relationships. Finally, the proposed frame generator learns to find the trajectory in the latent space which is coherent with the corresponding sound and generates a video in a hierarchical manner. We provide the new high-resolution landscape video dataset (audio-visual pair) for the sound-guided video generation task. The experiments show that our model outperforms the state-of-the-art methods in terms of video quality. We further show several applications including image and video editing to verify the effectiveness of our method.
Egocentric View Hand Action Recognition by Leveraging Hand Surface and Hand Grasp Type
Sep 08, 2021

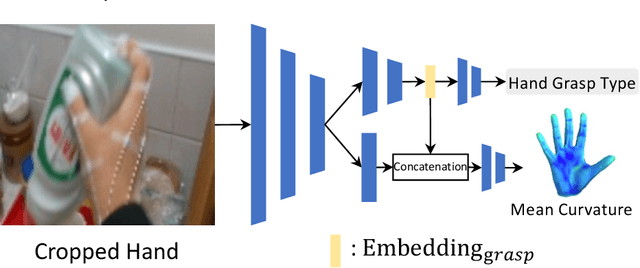

We introduce a multi-stage framework that uses mean curvature on a hand surface and focuses on learning interaction between hand and object by analyzing hand grasp type for hand action recognition in egocentric videos. The proposed method does not require 3D information of objects including 6D object poses which are difficult to annotate for learning an object's behavior while it interacts with hands. Instead, the framework synthesizes the mean curvature of the hand mesh model to encode the hand surface geometry in 3D space. Additionally, our method learns the hand grasp type which is highly correlated with the hand action. From our experiment, we notice that using hand grasp type and mean curvature of hand increases the performance of the hand action recognition.