 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuardMarkGS: Unified Ownership Tracing and Edit Deterrence for 3D Gaussian Splatting
May 13, 20263D Gaussian Splatting (3DGS) is becoming a practical representation for novel view synthesis, but its growing adoption, together with rapid advances in instruction-driven 3DGS editing, also exposes a dual copyright risk: once a 3DGS-based asset is released, it can be used without permission and manipulated through 3D editing. Existing protection methods address only one side of this problem. Watermarking can trace ownership after unauthorized use, but it cannot prevent malicious editing. Adversarial edit-deterrence methods can disrupt editing, but they do not provide evidence of ownership. To the best of our knowledge, we present the first unified protection framework for 3DGS that jointly optimizes ownership tracing and unauthorized editing deterrence. Our framework combines a scene-wide watermarking objective over all Gaussians with an adversarial objective for edit deterrence. The adversarial branch combines latent-anchor separation, denoising-trajectory diversion, and cross-attention diversion to divert the editing trajectory, while an update-saliency-motivated Gaussian selection strategy assigns stronger adversarial updates to mask-selected Gaussians, improving the balance among watermark recovery, edit deterrence, and rendering fidelity. Experiments on scenes from Mip-NeRF 360 and Instruct-NeRF2NeRF demonstrate that the proposed framework achieves a favorable balance among bit accuracy, edit deterrence, and rendering quality. These results suggest that practical copyright protection of 3DGS-based assets can be more effectively addressed by integrating ownership tracing and unauthorized editing deterrence into a single optimization framework.
FaceShield: Defending Facial Image against Deepfake Threats
Dec 13, 2024The rising use of deepfakes in criminal activities presents a significant issue, inciting widespread controversy. While numerous studies have tackled this problem, most primarily focus on deepfake detection. These reactive solutions are insufficient as a fundamental approach for crimes where authenticity verification is not critical. Existing proactive defenses also have limitations, as they are effective only for deepfake models based on specific Generative Adversarial Networks (GANs), making them less applicable in light of recent advancements in diffusion-based models. In this paper, we propose a proactive defense method named FaceShield, which introduces novel attack strategies targeting deepfakes generated by Diffusion Models (DMs) and facilitates attacks on various existing GAN-based deepfake models through facial feature extractor manipulations. Our approach consists of three main components: (i) manipulating the attention mechanism of DMs to exclude protected facial features during the denoising process, (ii) targeting prominent facial feature extraction models to enhance the robustness of our adversarial perturbation, and (iii) employing Gaussian blur and low-pass filtering techniques to improve imperceptibility while enhancing robustness against JPEG distortion. Experimental results on the CelebA-HQ and VGGFace2-HQ datasets demonstrate that our method achieves state-of-the-art performance against the latest deepfake models based on DMs, while also exhibiting applicability to GANs and showcasing greater imperceptibility of noise along with enhanced robustness.
Posture-Informed Muscular Force Learning for Robust Hand Pressure Estimation
Oct 31, 2024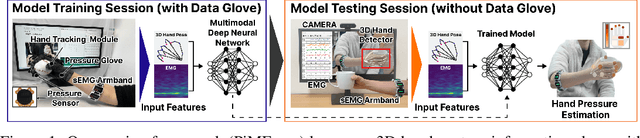
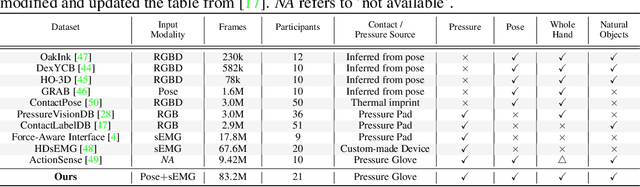
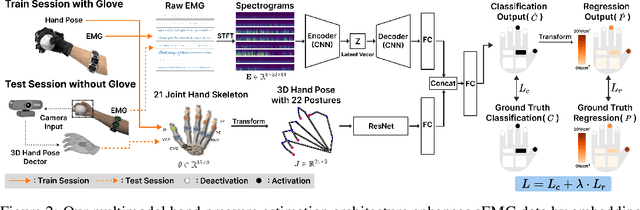

We present PiMForce, a novel framework that enhances hand pressure estimation by leveraging 3D hand posture information to augment forearm surface electromyography (sEMG) signals. Our approach utilizes detailed spatial information from 3D hand poses in conjunction with dynamic muscle activity from sEMG to enable accurate and robust whole-hand pressure measurements under diverse hand-object interactions. We also developed a multimodal data collection system that combines a pressure glove, an sEMG armband, and a markerless finger-tracking module. We created a comprehensive dataset from 21 participants, capturing synchronized data of hand posture, sEMG signals, and exerted hand pressure across various hand postures and hand-object interaction scenarios using our collection system. Our framework enables precise hand pressure estimation in complex and natural interaction scenarios. Our approach substantially mitigates the limitations of traditional sEMG-based or vision-based methods by integrating 3D hand posture information with sEMG signals. Video demos, data, and code are available online.
LISA: Localized Image Stylization with Audio via Implicit Neural Representation
Nov 21, 2022
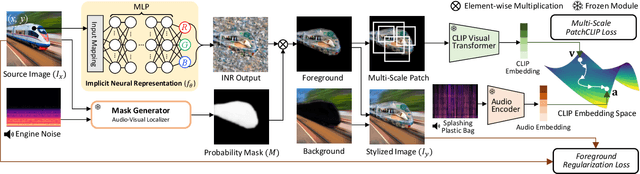
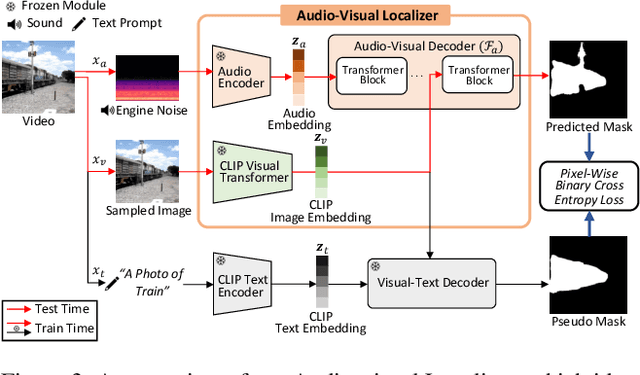
We present a novel framework, Localized Image Stylization with Audio (LISA) which performs audio-driven localized image stylization. Sound often provides information about the specific context of the scene and is closely related to a certain part of the scene or object. However, existing image stylization works have focused on stylizing the entire image using an image or text input. Stylizing a particular part of the image based on audio input is natural but challenging. In this work, we propose a framework that a user provides an audio input to localize the sound source in the input image and another for locally stylizing the target object or scene. LISA first produces a delicate localization map with an audio-visual localization network by leveraging CLIP embedding space. We then utilize implicit neural representation (INR) along with the predicted localization map to stylize the target object or scene based on sound information. The proposed INR can manipulate the localized pixel values to be semantically consistent with the provided audio input. Through a series of experiments, we show that the proposed framework outperforms the other audio-guided stylization methods. Moreover, LISA constructs concise localization maps and naturally manipulates the target object or scene in accordance with the given audio input.
Robust Sound-Guided Image Manipulation
Aug 31, 2022


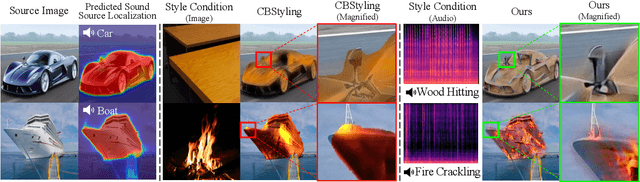
Recent successes suggest that an image can be manipulated by a text prompt, e.g., a landscape scene on a sunny day is manipulated into the same scene on a rainy day driven by a text input "raining". These approaches often utilize a StyleCLIP-based image generator, which leverages multi-modal (text and image) embedding space. However, we observe that such text inputs are often bottlenecked in providing and synthesizing rich semantic cues, e.g., differentiating heavy rain from rain with thunderstorms. To address this issue, we advocate leveraging an additional modality, sound, which has notable advantages in image manipulation as it can convey more diverse semantic cues (vivid emotions or dynamic expressions of the natural world) than texts. In this paper, we propose a novel approach that first extends the image-text joint embedding space with sound and applies a direct latent optimization method to manipulate a given image based on audio input, e.g., the sound of rain. Our extensive experiments show that our sound-guided image manipulation approach produces semantically and visually more plausible manipulation results than the state-of-the-art text and sound-guided image manipulation methods, which are further confirmed by our human evaluations. Our downstream task evaluations also show that our learned image-text-sound joint embedding space effectively encodes sound inputs.
Sound-Guided Semantic Video Generation
Apr 21, 2022
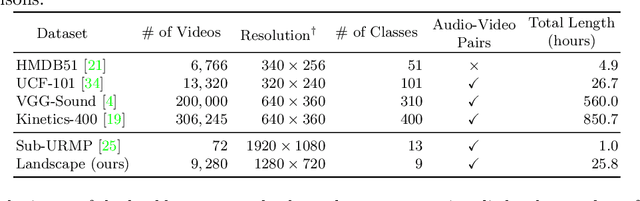
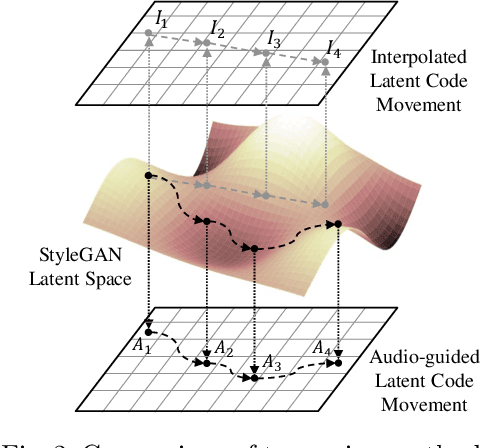

The recent success in StyleGAN demonstrates that pre-trained StyleGAN latent space is useful for realistic video generation. However, the generated motion in the video is usually not semantically meaningful due to the difficulty of determining the direction and magnitude in the StyleGAN latent space. In this paper, we propose a framework to generate realistic videos by leveraging multimodal (sound-image-text) embedding space. As sound provides the temporal contexts of the scene, our framework learns to generate a video that is semantically consistent with sound. First, our sound inversion module maps the audio directly into the StyleGAN latent space. We then incorporate the CLIP-based multimodal embedding space to further provide the audio-visual relationships. Finally, the proposed frame generator learns to find the trajectory in the latent space which is coherent with the corresponding sound and generates a video in a hierarchical manner. We provide the new high-resolution landscape video dataset (audio-visual pair) for the sound-guided video generation task. The experiments show that our model outperforms the state-of-the-art methods in terms of video quality. We further show several applications including image and video editing to verify the effectiveness of our method.
Sound-Guided Semantic Image Manipulation
Nov 30, 2021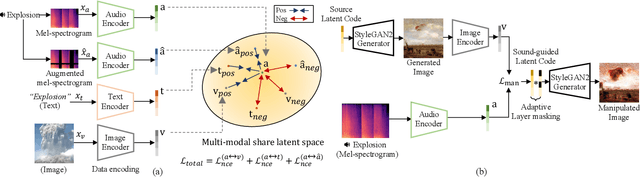
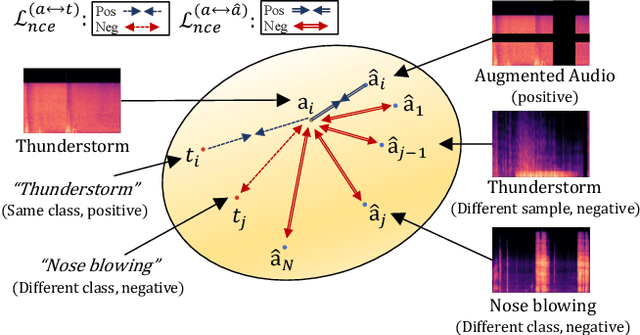


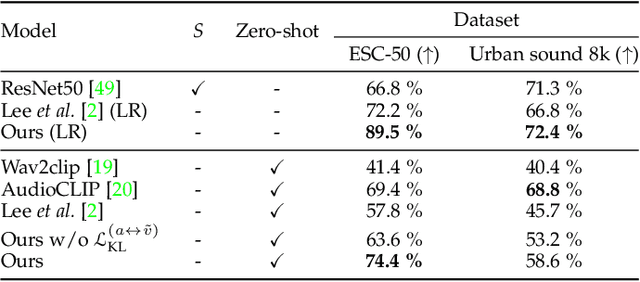
The recent success of the generative model shows that leveraging the multi-modal embedding space can manipulate an image using text information. However, manipulating an image with other sources rather than text, such as sound, is not easy due to the dynamic characteristics of the sources. Especially, sound can convey vivid emotions and dynamic expressions of the real world. Here, we propose a framework that directly encodes sound into the multi-modal (image-text) embedding space and manipulates an image from the space. Our audio encoder is trained to produce a latent representation from an audio input, which is forced to be aligned with image and text representations in the multi-modal embedding space. We use a direct latent optimization method based on aligned embeddings for sound-guided image manipulation. We also show that our method can mix text and audio modalities, which enrich the variety of the image modification. We verify the effectiveness of our sound-guided image manipulation quantitatively and qualitatively. We also show that our method can mix different modalities, i.e., text and audio, which enrich the variety of the image modification. The experiments on zero-shot audio classification and semantic-level image classification show that our proposed model outperforms other text and sound-guided state-of-the-art methods.