 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT-GAN: Conditional Transformation Generative Adversarial Network for Image Attribute Modification
Paper and Code
Aug 31, 2018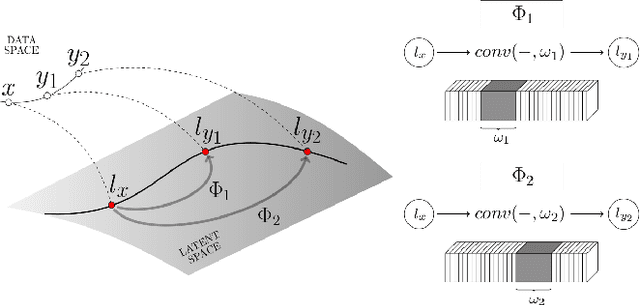

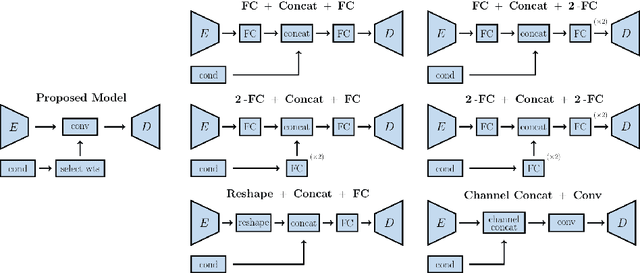
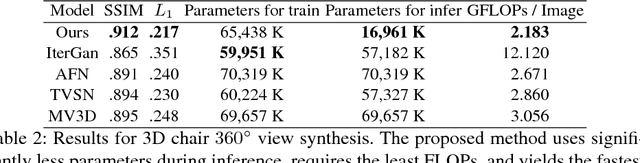
We propose a novel, fully-convolutional conditional generative model capable of learning image transformations using a light-weight network suited for real-time applications. We introduce the conditional transformation unit (CTU) designed to produce specified attribute modifications and an adaptive discriminator used to stabilize the learning procedure. We show that the network is capable of accurately modeling several discrete modifications simultaneously and can produce seamless continuous attribute modification via piece-wise interpolation. We also propose a task-divided decoder that incorporates a refinement map, designed to improve the network's coarse pixel estimation, along with RGB color balance parameters. We exceed state-of-the-art results on synthetic face and chair datasets and demonstrate the model's robustness using real hand pose datasets. Moreover, the proposed fully-convolutional model requires significantly fewer weights than conventional alternatives and is shown to provide an effective framework for producing a diverse range of real-time image attribute modifications.