 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Reasoning through Guided Adversarial Self-Play
Jan 30, 2026Reinforcement learning from verifiable rewards (RLVR) produces strong reasoning models, yet they can fail catastrophically when the conditioning context is fallible (e.g., corrupted chain-of-thought, misleading partial solutions, or mild input perturbations), since standard RLVR optimizes final-answer correctness only under clean conditioning. We introduce GASP (Guided Adversarial Self-Play), a robustification method that explicitly trains detect-and-repair capabilities using only outcome verification. Without human labels or external teachers, GASP forms an adversarial self-play game within a single model: a polluter learns to induce failure via locally coherent corruptions, while an agent learns to diagnose and recover under the same corrupted conditioning. To address the scarcity of successful recoveries early in training, we propose in-distribution repair guidance, an imitation term on self-generated repairs that increases recovery probability while preserving previously acquired capabilities. Across four open-weight models (1.5B--8B), GASP transforms strong-but-brittle reasoners into robust ones that withstand misleading and perturbed context while often improving clean accuracy. Further analysis shows that adversarial corruptions induce an effective curriculum, and in-distribution guidance enables rapid recovery learning with minimal representational drift.
Pose-Aware Weakly-Supervised Action Segmentation
Apr 08, 2025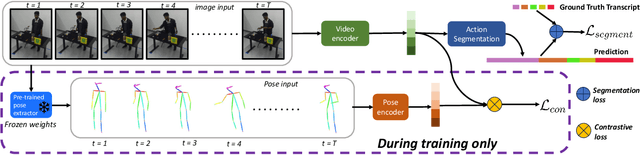
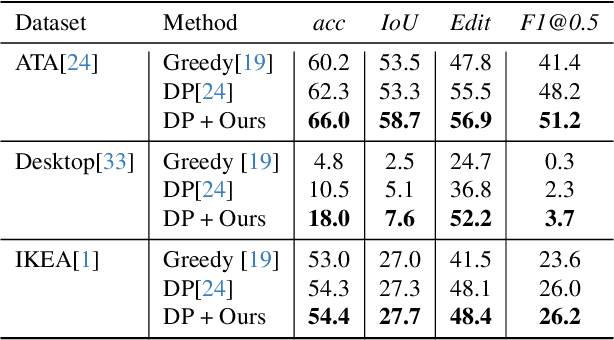
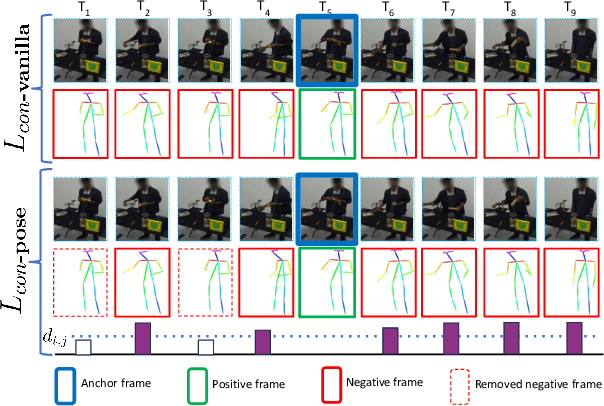
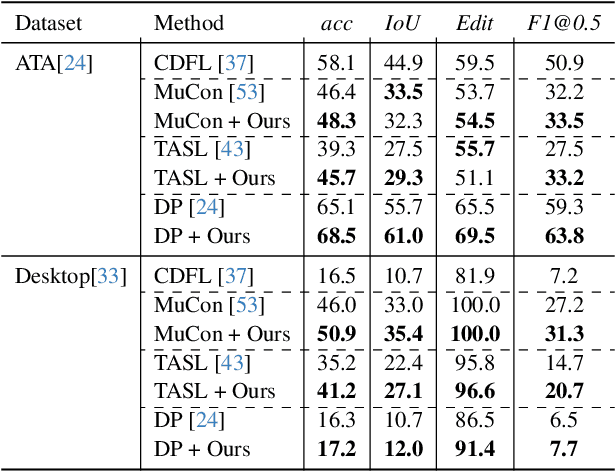
Understanding human behavior is an important problem in the pursuit of visual intelligence. A challenge in this endeavor is the extensive and costly effort required to accurately label action segments. To address this issue, we consider learning methods that demand minimal supervision for segmentation of human actions in long instructional videos. Specifically, we introduce a weakly-supervised framework that uniquely incorporates pose knowledge during training while omitting its use during inference, thereby distilling pose knowledge pertinent to each action component. We propose a pose-inspired contrastive loss as a part of the whole weakly-supervised framework which is trained to distinguish action boundaries more effectively. Our approach, validated through extensive experiments on representative datasets, outperforms previous state-of-the-art (SOTA) in segmenting long instructional videos under both online and offline settings. Additionally, we demonstrate the framework's adaptability to various segmentation backbones and pose extractors across different datasets.
ACE: Action Concept Enhancement of Video-Language Models in Procedural Videos
Nov 23, 2024
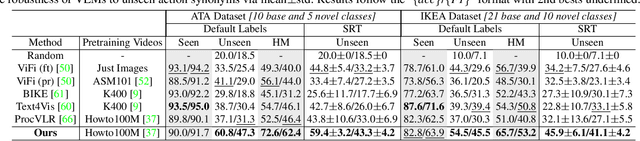
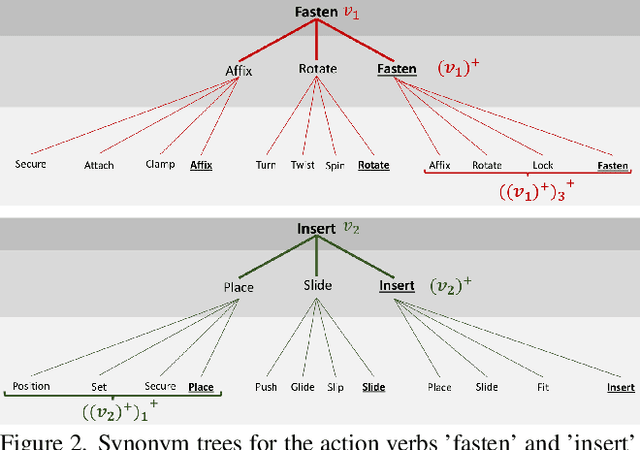
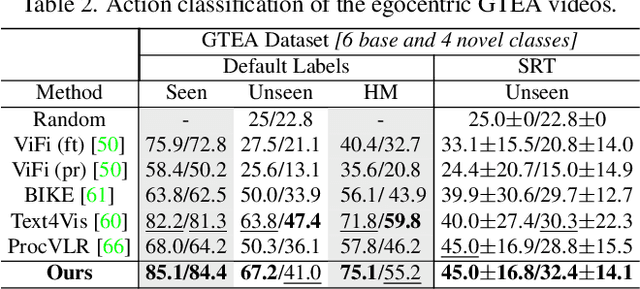
Vision-language models (VLMs) are capable of recognizing unseen actions. However, existing VLMs lack intrinsic understanding of procedural action concepts. Hence, they overfit to fixed labels and are not invariant to unseen action synonyms. To address this, we propose a simple fine-tuning technique, Action Concept Enhancement (ACE), to improve the robustness and concept understanding of VLMs in procedural action classification. ACE continually incorporates augmented action synonyms and negatives in an auxiliary classification loss by stochastically replacing fixed labels during training. This creates new combinations of action labels over the course of fine-tuning and prevents overfitting to fixed action representations. We show the enhanced concept understanding of our VLM, by visualizing the alignment of encoded embeddings of unseen action synonyms in the embedding space. Our experiments on the ATA, IKEA and GTEA datasets demonstrate the efficacy of ACE in domains of cooking and assembly leading to significant improvements in zero-shot action classification while maintaining competitive performance on seen actions.
IIT Bombay Racing Driverless: Autonomous Driving Stack for Formula Student AI
Aug 12, 2024This work presents the design and development of IIT Bombay Racing's Formula Student style autonomous racecar algorithm capable of running at the racing events of Formula Student-AI, held in the UK. The car employs a cutting-edge sensor suite of the compute unit NVIDIA Jetson Orin AGX, 2 ZED2i stereo cameras, 1 Velodyne Puck VLP16 LiDAR and SBG Systems Ellipse N GNSS/INS IMU. It features deep learning algorithms and control systems to navigate complex tracks and execute maneuvers without any human intervention. The design process involved extensive simulations and testing to optimize the vehicle's performance and ensure its safety. The algorithms have been tested on a small scale, in-house manufactured 4-wheeled robot and on simulation software. The results obtained for testing various algorithms in perception, simultaneous localization and mapping, path planning and controls have been detailed.
M2D2M: Multi-Motion Generation from Text with Discrete Diffusion Models
Jul 19, 2024



We introduce the Multi-Motion Discrete Diffusion Models (M2D2M), a novel approach for human motion generation from textual descriptions of multiple actions, utilizing the strengths of discrete diffusion models. This approach adeptly addresses the challenge of generating multi-motion sequences, ensuring seamless transitions of motions and coherence across a series of actions. The strength of M2D2M lies in its dynamic transition probability within the discrete diffusion model, which adapts transition probabilities based on the proximity between motion tokens, encouraging mixing between different modes. Complemented by a two-phase sampling strategy that includes independent and joint denoising steps, M2D2M effectively generates long-term, smooth, and contextually coherent human motion sequences, utilizing a model trained for single-motion generation. Extensive experiments demonstrate that M2D2M surpasses current state-of-the-art benchmarks for motion generation from text descriptions, showcasing its efficacy in interpreting language semantics and generating dynamic, realistic motions.
Can't make an Omelette without Breaking some Eggs: Plausible Action Anticipation using Large Video-Language Models
May 30, 2024



We introduce PlausiVL, a large video-language model for anticipating action sequences that are plausible in the real-world. While significant efforts have been made towards anticipating future actions, prior approaches do not take into account the aspect of plausibility in an action sequence. To address this limitation, we explore the generative capability of a large video-language model in our work and further, develop the understanding of plausibility in an action sequence by introducing two objective functions, a counterfactual-based plausible action sequence learning loss and a long-horizon action repetition loss. We utilize temporal logical constraints as well as verb-noun action pair logical constraints to create implausible/counterfactual action sequences and use them to train the model with plausible action sequence learning loss. This loss helps the model to differentiate between plausible and not plausible action sequences and also helps the model to learn implicit temporal cues crucial for the task of action anticipation. The long-horizon action repetition loss puts a higher penalty on the actions that are more prone to repetition over a longer temporal window. With this penalization, the model is able to generate diverse, plausible action sequences. We evaluate our approach on two large-scale datasets, Ego4D and EPIC-Kitchens-100, and show improvements on the task of action anticipation.
Multi-Objective Recommendation via Multivariate Policy Learning
May 03, 2024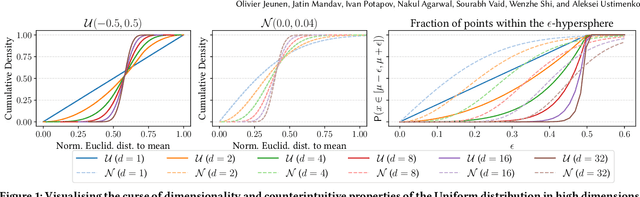

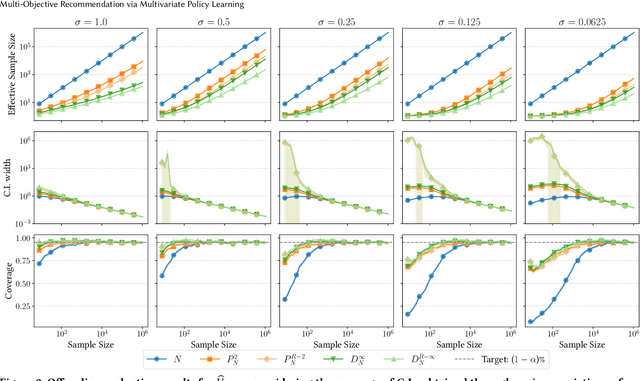
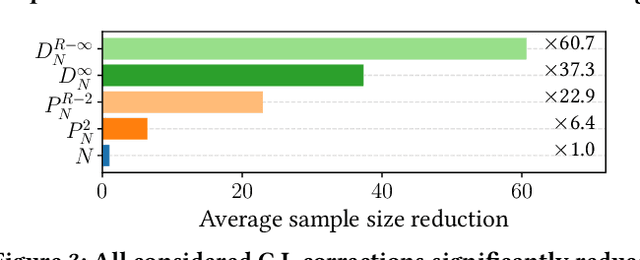
Real-world recommender systems often need to balance multiple objectives when deciding which recommendations to present to users. These include behavioural signals (e.g. clicks, shares, dwell time), as well as broader objectives (e.g. diversity, fairness). Scalarisation methods are commonly used to handle this balancing task, where a weighted average of per-objective reward signals determines the final score used for ranking. Naturally, how these weights are computed exactly, is key to success for any online platform. We frame this as a decision-making task, where the scalarisation weights are actions taken to maximise an overall North Star reward (e.g. long-term user retention or growth). We extend existing policy learning methods to the continuous multivariate action domain, proposing to maximise a pessimistic lower bound on the North Star reward that the learnt policy will yield. Typical lower bounds based on normal approximations suffer from insufficient coverage, and we propose an efficient and effective policy-dependent correction for this. We provide guidance to design stochastic data collection policies, as well as highly sensitive reward signals. Empirical observations from simulations, offline and online experiments highlight the efficacy of our deployed approach.
Disentangled Neural Relational Inference for Interpretable Motion Prediction
Jan 07, 2024Effective interaction modeling and behavior prediction of dynamic agents play a significant role in interactive motion planning for autonomous robots. Although existing methods have improved prediction accuracy, few research efforts have been devoted to enhancing prediction model interpretability and out-of-distribution (OOD) generalizability. This work addresses these two challenging aspects by designing a variational auto-encoder framework that integrates graph-based representations and time-sequence models to efficiently capture spatio-temporal relations between interactive agents and predict their dynamics. Our model infers dynamic interaction graphs in a latent space augmented with interpretable edge features that characterize the interactions. Moreover, we aim to enhance model interpretability and performance in OOD scenarios by disentangling the latent space of edge features, thereby strengthening model versatility and robustness. We validate our approach through extensive experiments on both simulated and real-world datasets. The results show superior performance compared to existing methods in modeling spatio-temporal relations, motion prediction, and identifying time-invariant latent features.
Vamos: Versatile Action Models for Video Understanding
Nov 22, 2023


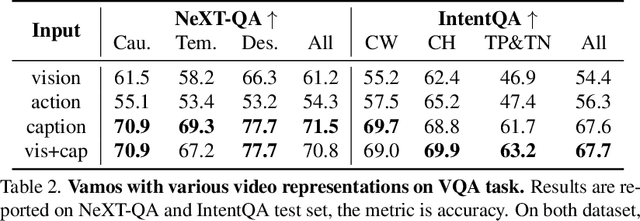
What makes good video representations for video understanding, such as anticipating future activities, or answering video-conditioned questions? While earlier approaches focus on end-to-end learning directly from video pixels, we propose to revisit text-based representations, such as discrete action labels, or free-form video captions, which are interpretable and can be directly consumed by large language models (LLMs). Intuitively, different video understanding tasks may require representations that are complementary and at different granularities. To this end, we propose versatile action models (Vamos), a learning framework powered by a large language model as the "reasoner", and can flexibly leverage visual embeddings, action labels, and free-form descriptions extracted from videos as its input. We evaluate Vamos on four complementary video understanding benchmarks, Ego4D, Next-QA, IntentQA, and EgoSchema, on its capability to model temporal dynamics, encode visual history, and perform reasoning. Surprisingly, we observe that text-based representations consistently achieve competitive performance on all benchmarks, and that visual embeddings provide marginal or no performance improvement, demonstrating the effectiveness of text-based video representation in the LLM era. We perform extensive ablation study and qualitative analysis to support our observations, and achieve state-of-the-art performance on three benchmarks.
Object-centric Video Representation for Long-term Action Anticipation
Oct 31, 2023



This paper focuses on building object-centric representations for long-term action anticipation in videos. Our key motivation is that objects provide important cues to recognize and predict human-object interactions, especially when the predictions are longer term, as an observed "background" object could be used by the human actor in the future. We observe that existing object-based video recognition frameworks either assume the existence of in-domain supervised object detectors or follow a fully weakly-supervised pipeline to infer object locations from action labels. We propose to build object-centric video representations by leveraging visual-language pretrained models. This is achieved by "object prompts", an approach to extract task-specific object-centric representations from general-purpose pretrained models without finetuning. To recognize and predict human-object interactions, we use a Transformer-based neural architecture which allows the "retrieval" of relevant objects for action anticipation at various time scales. We conduct extensive evaluations on the Ego4D, 50Salads, and EGTEA Gaze+ benchmarks. Both quantitative and qualitative results confirm the effectiveness of our proposed method.