 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERGE: Guided Vision-Language Models for Multi-Actor Event Reasoning and Grounding in Human-Robot Interaction
Mar 19, 2026We introduce MERGE, a system for situational grounding of actors, objects, and events in dynamic human-robot group interactions. Effective collaboration in such settings requires consistent situational awareness, built on persistent representations of people and objects and an episodic abstraction of events. MERGE achieves this by uniquely identifying physical instances of actors (humans or robots) and objects and structuring them into actor-action-object relations, ensuring temporal consistency across interactions. Central to MERGE is the integration of Vision-Language Models (VLMs) guided with a perception pipeline: a lightweight streaming module continuously processes visual input to detect changes and selectively invokes the VLM only when necessary. This decoupled design preserves the reasoning power and zero-shot generalization of VLMs while improving efficiency, avoiding both the high monetary cost and the latency of frame-by-frame captioning that leads to fragmented and delayed outputs. To address the absence of suitable benchmarks for multi-actor collaboration, we introduce the GROUND dataset, which offers fine-grained situational annotations of multi-person and human-robot interactions. On this dataset, our approach improves the average grounding score by a factor of 2 compared to the performance of VLM-only baselines - including GPT-4o, GPT-5 and Gemini 2.5 Flash - while also reducing run-time by a factor of 4. The code and data are available at www.github.com/HRI-EU/merge.
Pose-Aware Weakly-Supervised Action Segmentation
Apr 08, 2025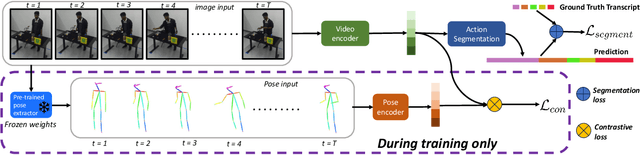
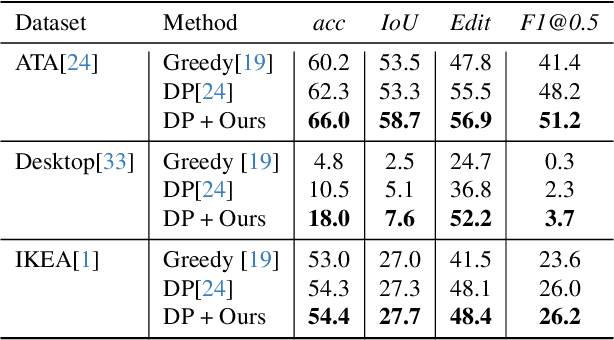
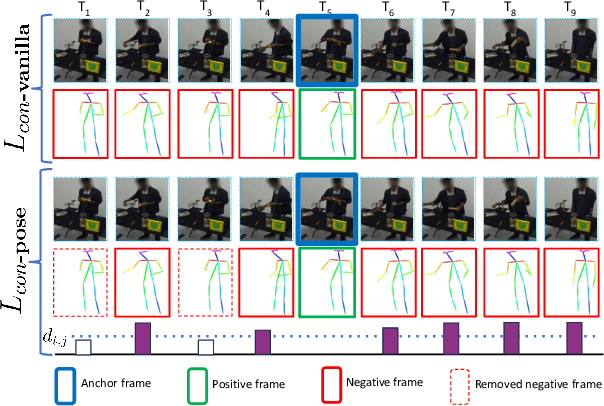
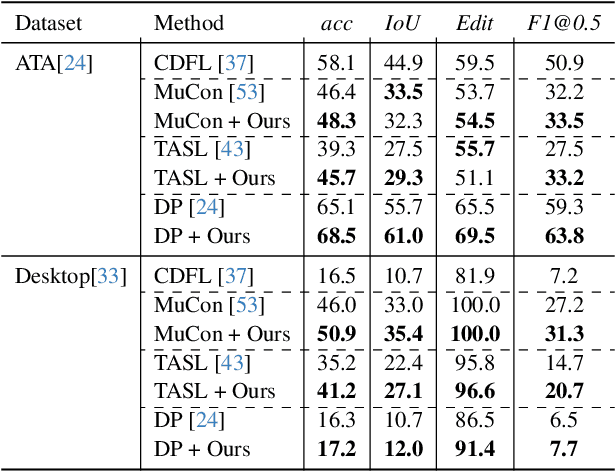
Understanding human behavior is an important problem in the pursuit of visual intelligence. A challenge in this endeavor is the extensive and costly effort required to accurately label action segments. To address this issue, we consider learning methods that demand minimal supervision for segmentation of human actions in long instructional videos. Specifically, we introduce a weakly-supervised framework that uniquely incorporates pose knowledge during training while omitting its use during inference, thereby distilling pose knowledge pertinent to each action component. We propose a pose-inspired contrastive loss as a part of the whole weakly-supervised framework which is trained to distinguish action boundaries more effectively. Our approach, validated through extensive experiments on representative datasets, outperforms previous state-of-the-art (SOTA) in segmenting long instructional videos under both online and offline settings. Additionally, we demonstrate the framework's adaptability to various segmentation backbones and pose extractors across different datasets.
ACE: Action Concept Enhancement of Video-Language Models in Procedural Videos
Nov 23, 2024
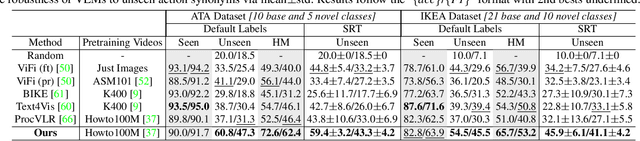
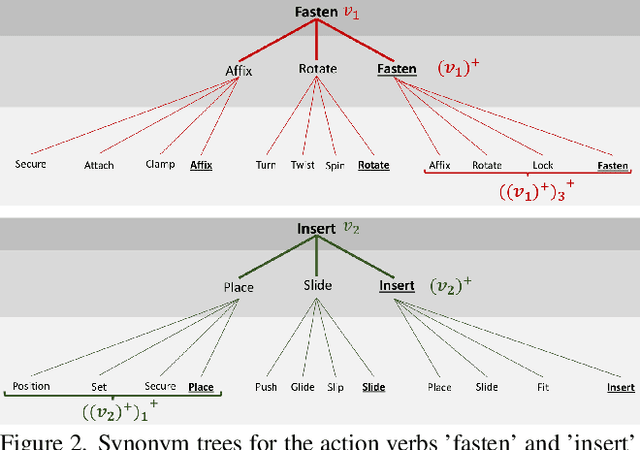
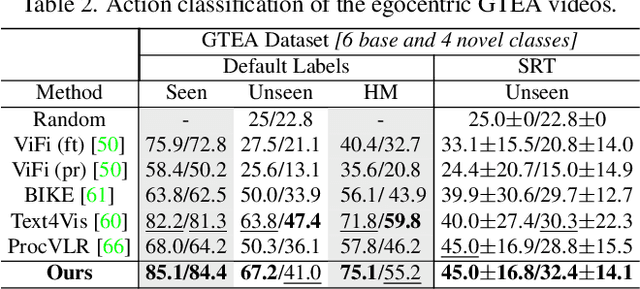
Vision-language models (VLMs) are capable of recognizing unseen actions. However, existing VLMs lack intrinsic understanding of procedural action concepts. Hence, they overfit to fixed labels and are not invariant to unseen action synonyms. To address this, we propose a simple fine-tuning technique, Action Concept Enhancement (ACE), to improve the robustness and concept understanding of VLMs in procedural action classification. ACE continually incorporates augmented action synonyms and negatives in an auxiliary classification loss by stochastically replacing fixed labels during training. This creates new combinations of action labels over the course of fine-tuning and prevents overfitting to fixed action representations. We show the enhanced concept understanding of our VLM, by visualizing the alignment of encoded embeddings of unseen action synonyms in the embedding space. Our experiments on the ATA, IKEA and GTEA datasets demonstrate the efficacy of ACE in domains of cooking and assembly leading to significant improvements in zero-shot action classification while maintaining competitive performance on seen actions.
Weakly-Supervised Online Action Segmentation in Multi-View Instructional Videos
Mar 24, 2022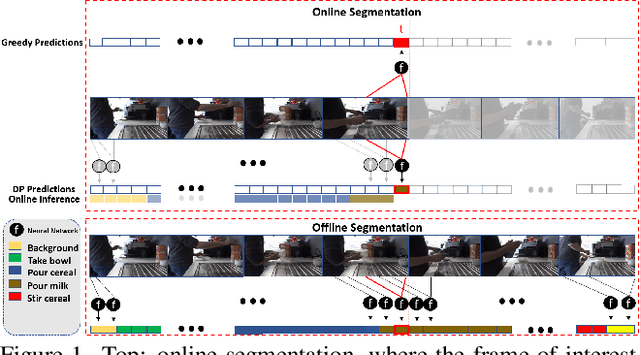
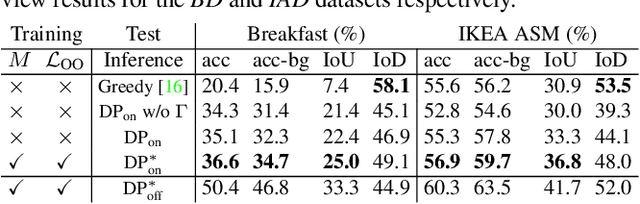
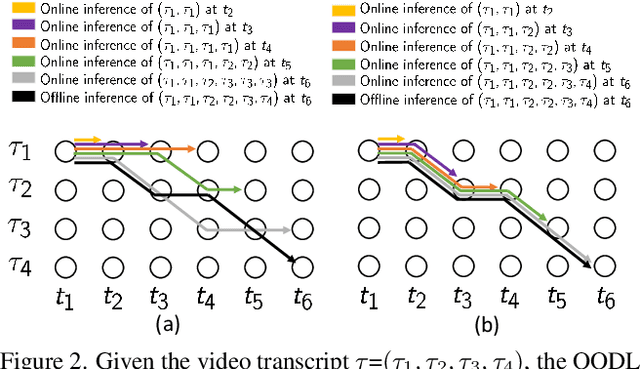
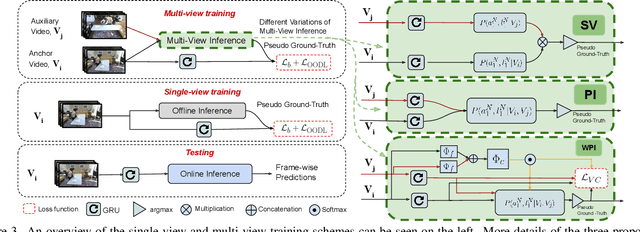
This paper addresses a new problem of weakly-supervised online action segmentation in instructional videos. We present a framework to segment streaming videos online at test time using Dynamic Programming and show its advantages over greedy sliding window approach. We improve our framework by introducing the Online-Offline Discrepancy Loss (OODL) to encourage the segmentation results to have a higher temporal consistency. Furthermore, only during training, we exploit frame-wise correspondence between multiple views as supervision for training weakly-labeled instructional videos. In particular, we investigate three different multi-view inference techniques to generate more accurate frame-wise pseudo ground-truth with no additional annotation cost. We present results and ablation studies on two benchmark multi-view datasets, Breakfast and IKEA ASM. Experimental results show efficacy of the proposed methods both qualitatively and quantitatively in two domains of cooking and assembly.
Hierarchical Modeling for Task Recognition and Action Segmentation in Weakly-Labeled Instructional Videos
Oct 12, 2021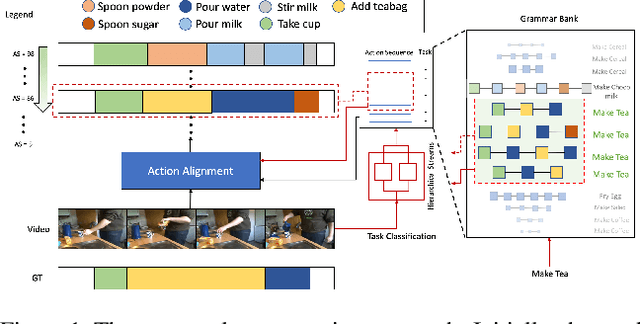
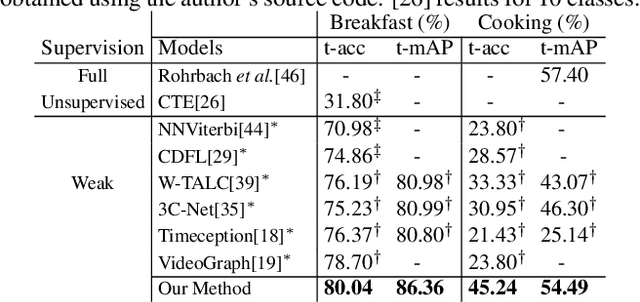
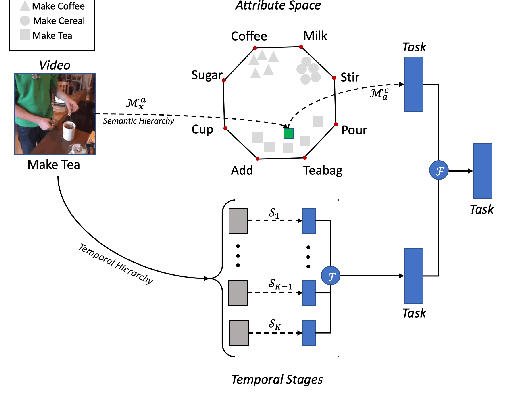
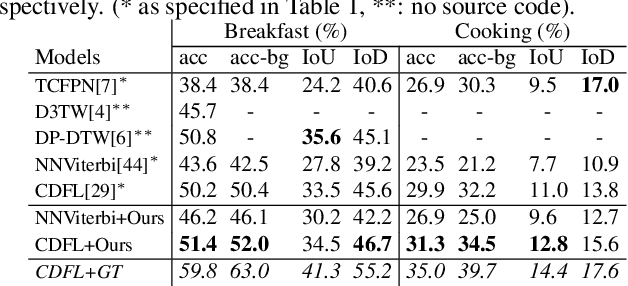
This paper focuses on task recognition and action segmentation in weakly-labeled instructional videos, where only the ordered sequence of video-level actions is available during training. We propose a two-stream framework, which exploits semantic and temporal hierarchies to recognize top-level tasks in instructional videos. Further, we present a novel top-down weakly-supervised action segmentation approach, where the predicted task is used to constrain the inference of fine-grained action sequences. Experimental results on the popular Breakfast and Cooking 2 datasets show that our two-stream hierarchical task modeling significantly outperforms existing methods in top-level task recognition for all datasets and metrics. Additionally, using our task recognition framework in the proposed top-down action segmentation approach consistently improves the state of the art, while also reducing segmentation inference time by 80-90 percent.
Action Duration Prediction for Segment-Level Alignment of Weakly-Labeled Videos
Nov 20, 2020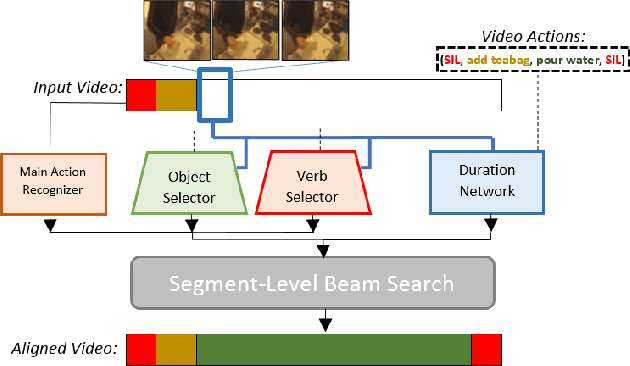
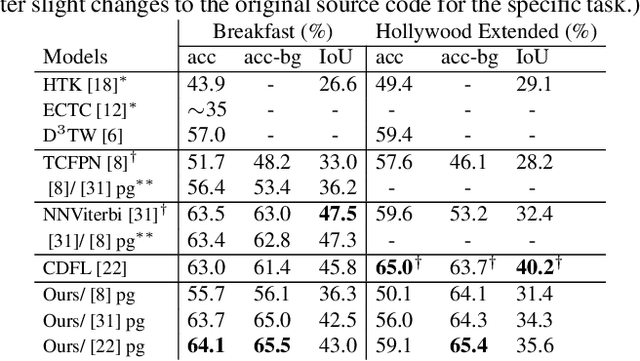
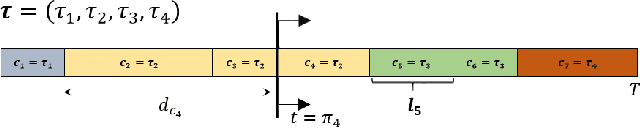
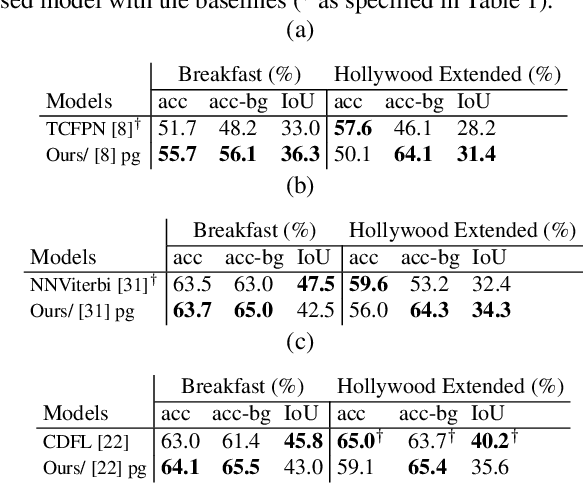
This paper focuses on weakly-supervised action alignment, where only the ordered sequence of video-level actions is available for training. We propose a novel Duration Network, which captures a short temporal window of the video and learns to predict the remaining duration of a given action at any point in time with a level of granularity based on the type of that action. Further, we introduce a Segment-Level Beam Search to obtain the best alignment, that maximizes our posterior probability. Segment-Level Beam Search efficiently aligns actions by considering only a selected set of frames that have more confident predictions. The experimental results show that our alignments for long videos are more robust than existing models. Moreover, the proposed method achieves state of the art results in certain cases on the popular Breakfast and Hollywood Extended datasets.
A Realistic Dataset and Baseline Temporal Model for Early Drowsiness Detection
Apr 15, 2019

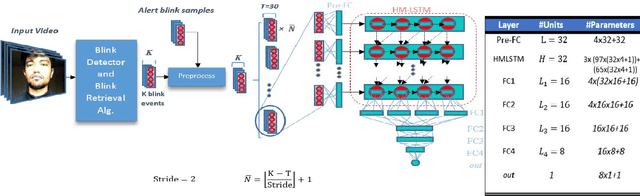
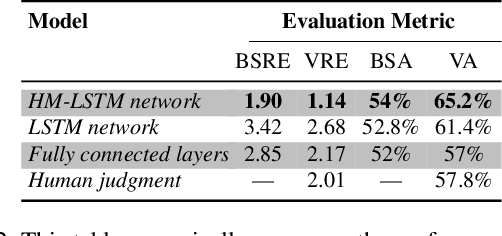
Drowsiness can put lives of many drivers and workers in danger. It is important to design practical and easy-to-deploy real-world systems to detect the onset of drowsiness.In this paper, we address early drowsiness detection, which can provide early alerts and offer subjects ample time to react. We present a large and public real-life dataset of 60 subjects, with video segments labeled as alert, low vigilant, or drowsy. This dataset consists of around 30 hours of video, with contents ranging from subtle signs of drowsiness to more obvious ones. We also benchmark a temporal model for our dataset, which has low computational and storage demands. The core of our proposed method is a Hierarchical Multiscale Long Short-Term Memory (HM-LSTM) network, that is fed by detected blink features in sequence. Our experiments demonstrate the relationship between the sequential blink features and drowsiness. In the experimental results, our baseline method produces higher accuracy than human judgment.