 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Shortcuts to Reasoning: Robust Post-Training of Theory of Mind with Reinforcement Learning
Jun 08, 2026Theory of Mind (ToM) is a must-acquire skill for modern foundation model systems to operate effectively and safely in the real world. Recent works have explored honing ToM via post-training; however, we show that such progress is confounded by a pervasive "shortcut" issue: tasks can reach up to 99% accuracy by simply exploiting spurious causal correlations, leading to a false sense of ToM. Motivated by this, we first develop a framework to systematically examine ToM datasets for shortcuts and provide guidance for future development. We find that questions reducible to pure state tracking, such as "belief," are especially shortcut-prone compared to mind questions, such as "intention," where reasoning beyond tracking is required. Using four shortcut-free datasets across three ToM contexts, we then comprehensively study whether Reinforcement Fine-Tuning with verifiable rewards and explicit reasoning chains, called Thinking-RFT, elevates ToM beyond Supervised Fine-Tuning, or SFT. Our key findings are as follows. First, Thinking-RFT effectively improves ToM in all scenarios, with a 6% improvement over SFT, particularly in complex higher-order reasoning, with a 10% improvement over SFT, and multimodal cases, with a 7% improvement over SFT. It also generalizes notably better to unseen domains and higher-order queries while being more robust to counterfactuals. Second, ToM benefits specifically from the joint effect of reasoning and RL: Thinking-RFT outperforms Non-Thinking-RFT by 7% on average. Third, RFT works by learning to ground its reasoning on anchor cues, such as keywords and state changes, that correspond to causal factors. We believe our study is useful for developing effective and robust ToM post-training datasets and advancing critical ToM capabilities.
MERGE: Guided Vision-Language Models for Multi-Actor Event Reasoning and Grounding in Human-Robot Interaction
Mar 19, 2026We introduce MERGE, a system for situational grounding of actors, objects, and events in dynamic human-robot group interactions. Effective collaboration in such settings requires consistent situational awareness, built on persistent representations of people and objects and an episodic abstraction of events. MERGE achieves this by uniquely identifying physical instances of actors (humans or robots) and objects and structuring them into actor-action-object relations, ensuring temporal consistency across interactions. Central to MERGE is the integration of Vision-Language Models (VLMs) guided with a perception pipeline: a lightweight streaming module continuously processes visual input to detect changes and selectively invokes the VLM only when necessary. This decoupled design preserves the reasoning power and zero-shot generalization of VLMs while improving efficiency, avoiding both the high monetary cost and the latency of frame-by-frame captioning that leads to fragmented and delayed outputs. To address the absence of suitable benchmarks for multi-actor collaboration, we introduce the GROUND dataset, which offers fine-grained situational annotations of multi-person and human-robot interactions. On this dataset, our approach improves the average grounding score by a factor of 2 compared to the performance of VLM-only baselines - including GPT-4o, GPT-5 and Gemini 2.5 Flash - while also reducing run-time by a factor of 4. The code and data are available at www.github.com/HRI-EU/merge.
Pose-Aware Weakly-Supervised Action Segmentation
Apr 08, 2025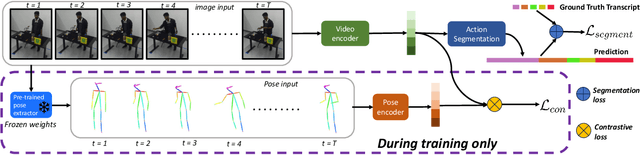
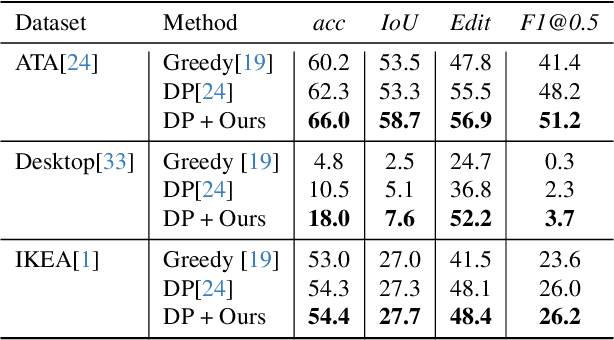
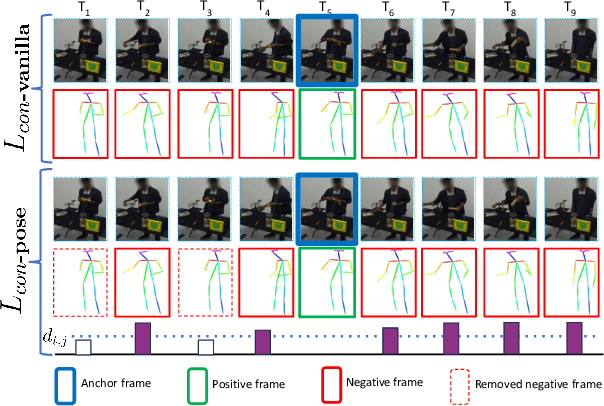
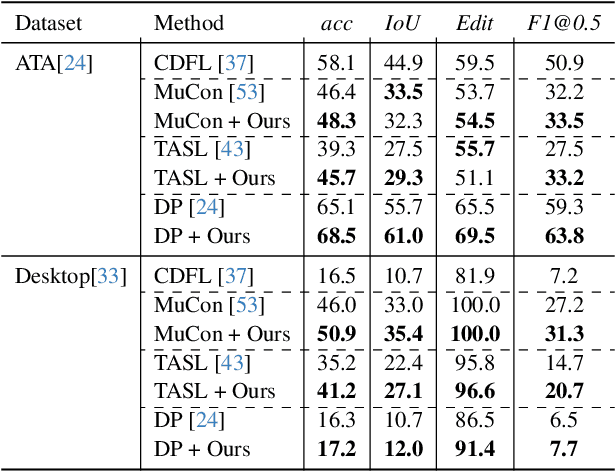
Understanding human behavior is an important problem in the pursuit of visual intelligence. A challenge in this endeavor is the extensive and costly effort required to accurately label action segments. To address this issue, we consider learning methods that demand minimal supervision for segmentation of human actions in long instructional videos. Specifically, we introduce a weakly-supervised framework that uniquely incorporates pose knowledge during training while omitting its use during inference, thereby distilling pose knowledge pertinent to each action component. We propose a pose-inspired contrastive loss as a part of the whole weakly-supervised framework which is trained to distinguish action boundaries more effectively. Our approach, validated through extensive experiments on representative datasets, outperforms previous state-of-the-art (SOTA) in segmenting long instructional videos under both online and offline settings. Additionally, we demonstrate the framework's adaptability to various segmentation backbones and pose extractors across different datasets.
Generalized Mission Planning for Heterogeneous Multi-Robot Teams via LLM-constructed Hierarchical Trees
Jan 27, 2025We present a novel mission-planning strategy for heterogeneous multi-robot teams, taking into account the specific constraints and capabilities of each robot. Our approach employs hierarchical trees to systematically break down complex missions into manageable sub-tasks. We develop specialized APIs and tools, which are utilized by Large Language Models (LLMs) to efficiently construct these hierarchical trees. Once the hierarchical tree is generated, it is further decomposed to create optimized schedules for each robot, ensuring adherence to their individual constraints and capabilities. We demonstrate the effectiveness of our framework through detailed examples covering a wide range of missions, showcasing its flexibility and scalability.
Optimal Driver Warning Generation in Dynamic Driving Environment
Nov 09, 2024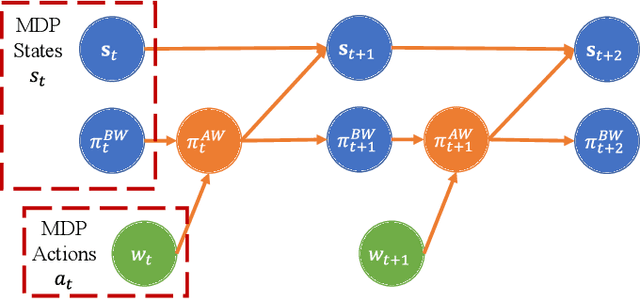
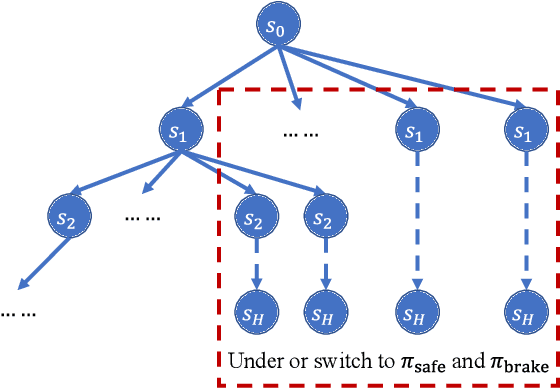
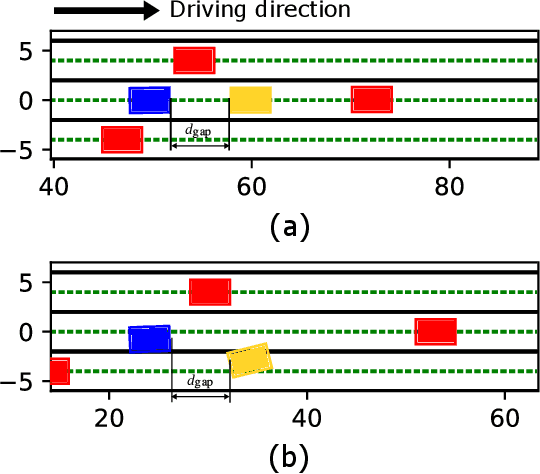
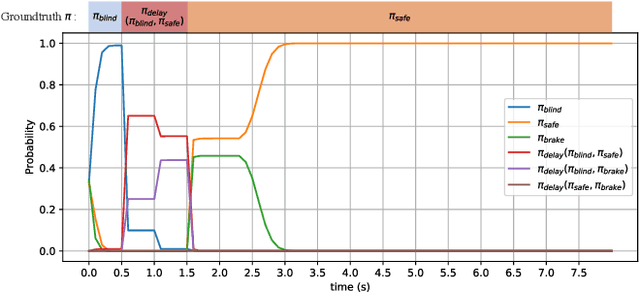
The driver warning system that alerts the human driver about potential risks during driving is a key feature of an advanced driver assistance system. Existing driver warning technologies, mainly the forward collision warning and unsafe lane change warning, can reduce the risk of collision caused by human errors. However, the current design methods have several major limitations. Firstly, the warnings are mainly generated in a one-shot manner without modeling the ego driver's reactions and surrounding objects, which reduces the flexibility and generality of the system over different scenarios. Additionally, the triggering conditions of warning are mostly rule-based threshold-checking given the current state, which lacks the prediction of the potential risk in a sufficiently long future horizon. In this work, we study the problem of optimally generating driver warnings by considering the interactions among the generated warning, the driver behavior, and the states of ego and surrounding vehicles on a long horizon. The warning generation problem is formulated as a partially observed Markov decision process (POMDP). An optimal warning generation framework is proposed as a solution to the proposed POMDP. The simulation experiments demonstrate the superiority of the proposed solution to the existing warning generation methods.
Constrained Human-AI Cooperation: An Inclusive Embodied Social Intelligence Challenge
Nov 05, 2024



We introduce Constrained Human-AI Cooperation (CHAIC), an inclusive embodied social intelligence challenge designed to test social perception and cooperation in embodied agents. In CHAIC, the goal is for an embodied agent equipped with egocentric observations to assist a human who may be operating under physical constraints -- e.g., unable to reach high places or confined to a wheelchair -- in performing common household or outdoor tasks as efficiently as possible. To achieve this, a successful helper must: (1) infer the human's intents and constraints by following the human and observing their behaviors (social perception), and (2) make a cooperative plan tailored to the human partner to solve the task as quickly as possible, working together as a team (cooperative planning). To benchmark this challenge, we create four new agents with real physical constraints and eight long-horizon tasks featuring both indoor and outdoor scenes with various constraints, emergency events, and potential risks. We benchmark planning- and learning-based baselines on the challenge and introduce a new method that leverages large language models and behavior modeling. Empirical evaluations demonstrate the effectiveness of our benchmark in enabling systematic assessment of key aspects of machine social intelligence. Our benchmark and code are publicly available at https://github.com/UMass-Foundation-Model/CHAIC.
Follow the Rules: Reasoning for Video Anomaly Detection with Large Language Models
Jul 14, 2024Video Anomaly Detection (VAD) is crucial for applications such as security surveillance and autonomous driving. However, existing VAD methods provide little rationale behind detection, hindering public trust in real-world deployments. In this paper, we approach VAD with a reasoning framework. Although Large Language Models (LLMs) have shown revolutionary reasoning ability, we find that their direct use falls short of VAD. Specifically, the implicit knowledge pre-trained in LLMs focuses on general context and thus may not apply to every specific real-world VAD scenario, leading to inflexibility and inaccuracy. To address this, we propose AnomalyRuler, a novel rule-based reasoning framework for VAD with LLMs. AnomalyRuler comprises two main stages: induction and deduction. In the induction stage, the LLM is fed with few-shot normal reference samples and then summarizes these normal patterns to induce a set of rules for detecting anomalies. The deduction stage follows the induced rules to spot anomalous frames in test videos. Additionally, we design rule aggregation, perception smoothing, and robust reasoning strategies to further enhance AnomalyRuler's robustness. AnomalyRuler is the first reasoning approach for the one-class VAD task, which requires only few-normal-shot prompting without the need for full-shot training, thereby enabling fast adaption to various VAD scenarios. Comprehensive experiments across four VAD benchmarks demonstrate AnomalyRuler's state-of-the-art detection performance and reasoning ability.
Rank2Tell: A Multimodal Driving Dataset for Joint Importance Ranking and Reasoning
Sep 12, 2023The widespread adoption of commercial autonomous vehicles (AVs) and advanced driver assistance systems (ADAS) may largely depend on their acceptance by society, for which their perceived trustworthiness and interpretability to riders are crucial. In general, this task is challenging because modern autonomous systems software relies heavily on black-box artificial intelligence models. Towards this goal, this paper introduces a novel dataset, Rank2Tell, a multi-modal ego-centric dataset for Ranking the importance level and Telling the reason for the importance. Using various close and open-ended visual question answering, the dataset provides dense annotations of various semantic, spatial, temporal, and relational attributes of various important objects in complex traffic scenarios. The dense annotations and unique attributes of the dataset make it a valuable resource for researchers working on visual scene understanding and related fields. Further, we introduce a joint model for joint importance level ranking and natural language captions generation to benchmark our dataset and demonstrate performance with quantitative evaluations.
Weakly-Supervised Online Action Segmentation in Multi-View Instructional Videos
Mar 24, 2022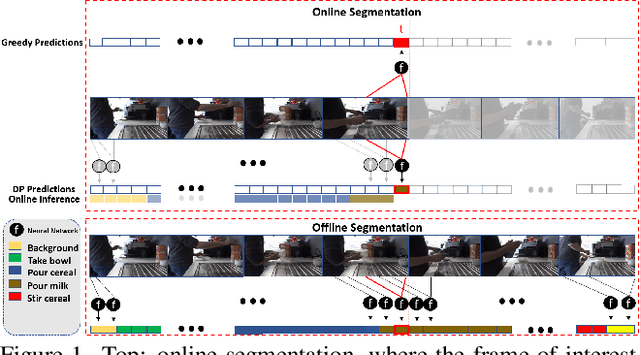
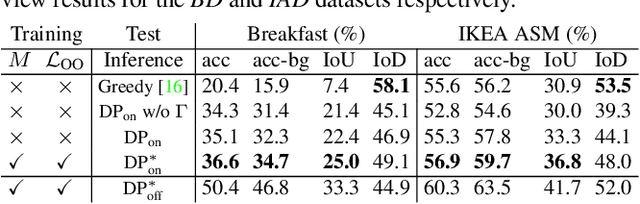
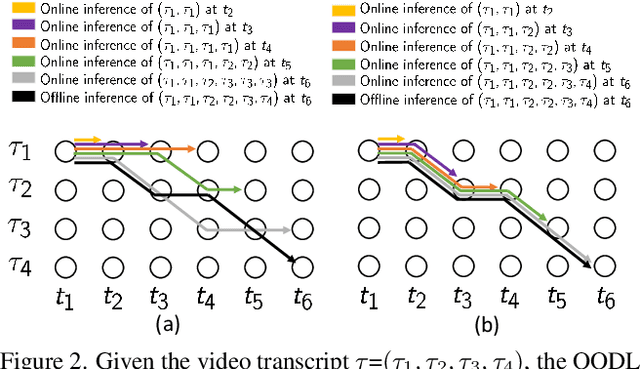
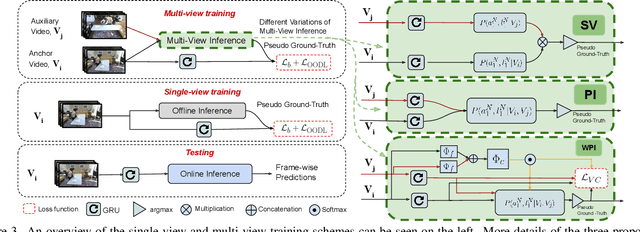
This paper addresses a new problem of weakly-supervised online action segmentation in instructional videos. We present a framework to segment streaming videos online at test time using Dynamic Programming and show its advantages over greedy sliding window approach. We improve our framework by introducing the Online-Offline Discrepancy Loss (OODL) to encourage the segmentation results to have a higher temporal consistency. Furthermore, only during training, we exploit frame-wise correspondence between multiple views as supervision for training weakly-labeled instructional videos. In particular, we investigate three different multi-view inference techniques to generate more accurate frame-wise pseudo ground-truth with no additional annotation cost. We present results and ablation studies on two benchmark multi-view datasets, Breakfast and IKEA ASM. Experimental results show efficacy of the proposed methods both qualitatively and quantitatively in two domains of cooking and assembly.
Social-STAGE: Spatio-Temporal Multi-Modal Future Trajectory Forecast
Nov 10, 2020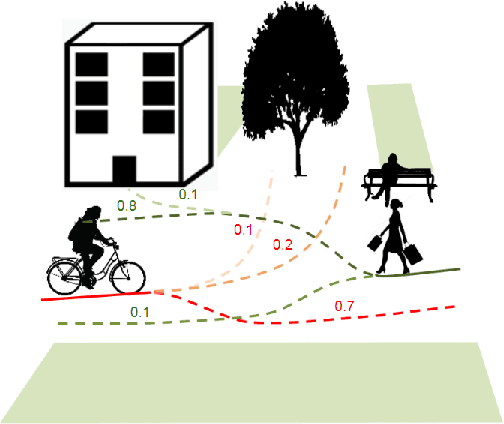
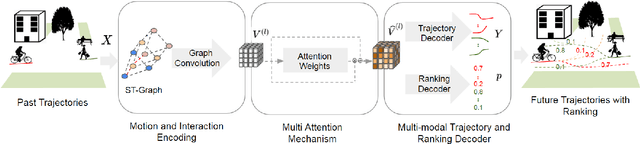
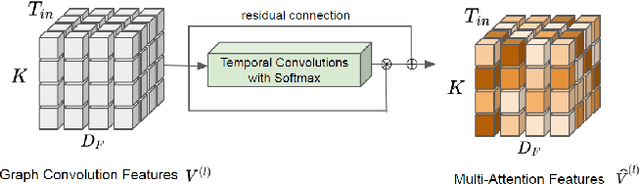
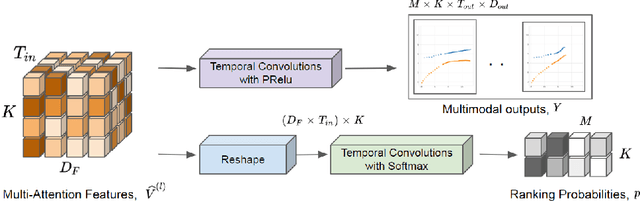
This paper considers the problem of multi-modal future trajectory forecast with ranking. Here, multi-modality and ranking refer to the multiple plausible path predictions and the confidence in those predictions, respectively. We propose Social-STAGE, Social interaction-aware Spatio-Temporal multi-Attention Graph convolution network with novel Evaluation for multi-modality. Our main contributions include analysis and formulation of multi-modality with ranking using interaction and multi-attention, and introduction of new metrics to evaluate the diversity and associated confidence of multi-modal predictions. We evaluate our approach on existing public datasets ETH and UCY and show that the proposed algorithm outperforms the state of the arts on these datasets.