 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Myopic Constrained POMDP Planning with Recursive Dual Ascent
Mar 26, 2024



Lagrangian-guided Monte Carlo tree search with global dual ascent has been applied to solve large constrained partially observable Markov decision processes (CPOMDPs) online. In this work, we demonstrate that these global dual parameters can lead to myopic action selection during exploration, ultimately leading to suboptimal decision making. To address this, we introduce history-dependent dual variables that guide local action selection and are optimized with recursive dual ascent. We empirically compare the performance of our approach on a motivating toy example and two large CPOMDPs, demonstrating improved exploration, and ultimately, safer outcomes.
Rank2Tell: A Multimodal Driving Dataset for Joint Importance Ranking and Reasoning
Sep 12, 2023The widespread adoption of commercial autonomous vehicles (AVs) and advanced driver assistance systems (ADAS) may largely depend on their acceptance by society, for which their perceived trustworthiness and interpretability to riders are crucial. In general, this task is challenging because modern autonomous systems software relies heavily on black-box artificial intelligence models. Towards this goal, this paper introduces a novel dataset, Rank2Tell, a multi-modal ego-centric dataset for Ranking the importance level and Telling the reason for the importance. Using various close and open-ended visual question answering, the dataset provides dense annotations of various semantic, spatial, temporal, and relational attributes of various important objects in complex traffic scenarios. The dense annotations and unique attributes of the dataset make it a valuable resource for researchers working on visual scene understanding and related fields. Further, we introduce a joint model for joint importance level ranking and natural language captions generation to benchmark our dataset and demonstrate performance with quantitative evaluations.
Improving debris flow evacuation alerts in Taiwan using machine learning
Aug 27, 2022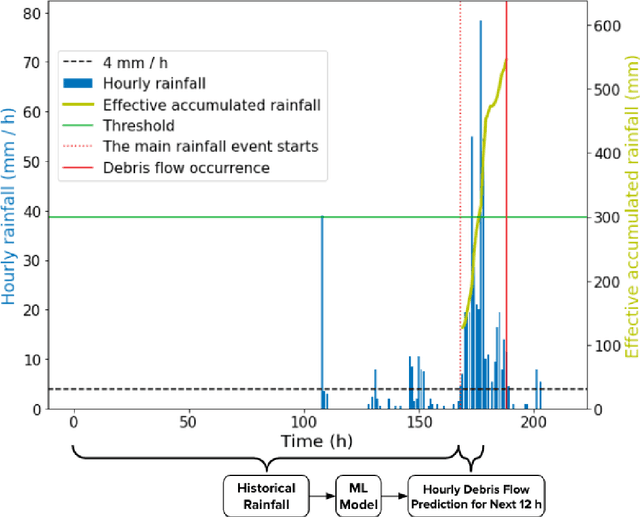
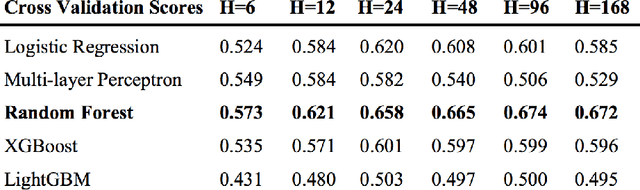
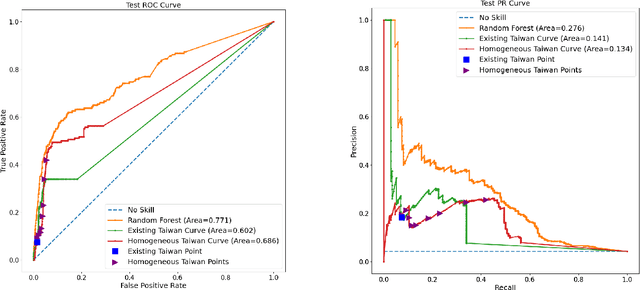
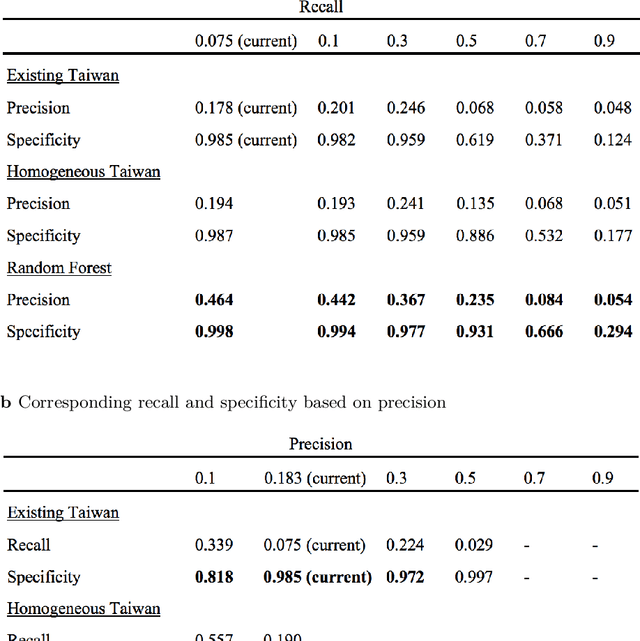
Taiwan has the highest susceptibility to and fatalities from debris flows worldwide. The existing debris flow warning system in Taiwan, which uses a time-weighted measure of rainfall, leads to alerts when the measure exceeds a predefined threshold. However, this system generates many false alarms and misses a substantial fraction of the actual debris flows. Towards improving this system, we implemented five machine learning models that input historical rainfall data and predict whether a debris flow will occur within a selected time. We found that a random forest model performed the best among the five models and outperformed the existing system in Taiwan. Furthermore, we identified the rainfall trajectories strongly related to debris flow occurrences and explored trade-offs between the risks of missing debris flows versus frequent false alerts. These results suggest the potential for machine learning models trained on hourly rainfall data alone to save lives while reducing false alerts.