 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAST-EQA: Efficient Embodied Question Answering with Global and Local Region Relevancy
Feb 17, 2026Embodied Question Answering (EQA) combines visual scene understanding, goal-directed exploration, spatial and temporal reasoning under partial observability. A central challenge is to confine physical search to question-relevant subspaces while maintaining a compact, actionable memory of observations. Furthermore, for real-world deployment, fast inference time during exploration is crucial. We introduce FAST-EQA, a question-conditioned framework that (i) identifies likely visual targets, (ii) scores global regions of interest to guide navigation, and (iii) employs Chain-of-Thought (CoT) reasoning over visual memory to answer confidently. FAST-EQA maintains a bounded scene memory that stores a fixed-capacity set of region-target hypotheses and updates them online, enabling robust handling of both single and multi-target questions without unbounded growth. To expand coverage efficiently, a global exploration policy treats narrow openings and doors as high-value frontiers, complementing local target seeking with minimal computation. Together, these components focus the agent's attention, improve scene coverage, and improve answer reliability while running substantially faster than prior approaches. On HMEQA and EXPRESS-Bench, FAST-EQA achieves state-of-the-art performance, while performing competitively on OpenEQA and MT-HM3D.
GFlowVLM: Enhancing Multi-step Reasoning in Vision-Language Models with Generative Flow Networks
Mar 09, 2025



Vision-Language Models (VLMs) have recently shown promising advancements in sequential decision-making tasks through task-specific fine-tuning. However, common fine-tuning methods, such as Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) techniques like Proximal Policy Optimization (PPO), present notable limitations: SFT assumes Independent and Identically Distributed (IID) data, while PPO focuses on maximizing cumulative rewards. These limitations often restrict solution diversity and hinder generalization in multi-step reasoning tasks. To address these challenges, we introduce a novel framework, GFlowVLM, a framework that fine-tune VLMs using Generative Flow Networks (GFlowNets) to promote generation of diverse solutions for complex reasoning tasks. GFlowVLM models the environment as a non-Markovian decision process, allowing it to capture long-term dependencies essential for real-world applications. It takes observations and task descriptions as inputs to prompt chain-of-thought (CoT) reasoning which subsequently guides action selection. We use task based rewards to fine-tune VLM with GFlowNets. This approach enables VLMs to outperform prior fine-tuning methods, including SFT and RL. Empirical results demonstrate the effectiveness of GFlowVLM on complex tasks such as card games (NumberLine, BlackJack) and embodied planning tasks (ALFWorld), showing enhanced training efficiency, solution diversity, and stronger generalization capabilities across both in-distribution and out-of-distribution scenarios.
Generalized Mission Planning for Heterogeneous Multi-Robot Teams via LLM-constructed Hierarchical Trees
Jan 27, 2025We present a novel mission-planning strategy for heterogeneous multi-robot teams, taking into account the specific constraints and capabilities of each robot. Our approach employs hierarchical trees to systematically break down complex missions into manageable sub-tasks. We develop specialized APIs and tools, which are utilized by Large Language Models (LLMs) to efficiently construct these hierarchical trees. Once the hierarchical tree is generated, it is further decomposed to create optimized schedules for each robot, ensuring adherence to their individual constraints and capabilities. We demonstrate the effectiveness of our framework through detailed examples covering a wide range of missions, showcasing its flexibility and scalability.
Optimal Driver Warning Generation in Dynamic Driving Environment
Nov 09, 2024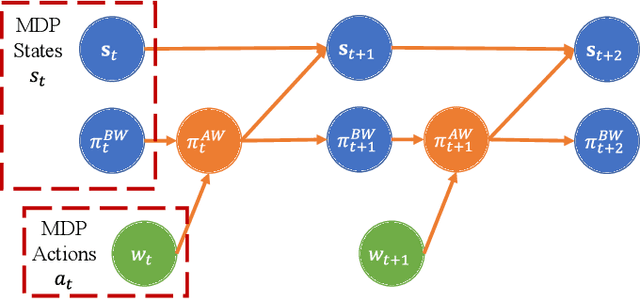
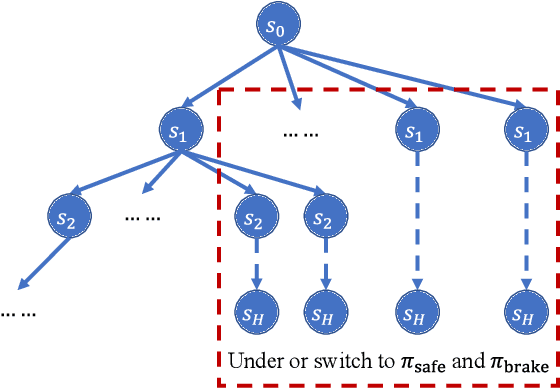
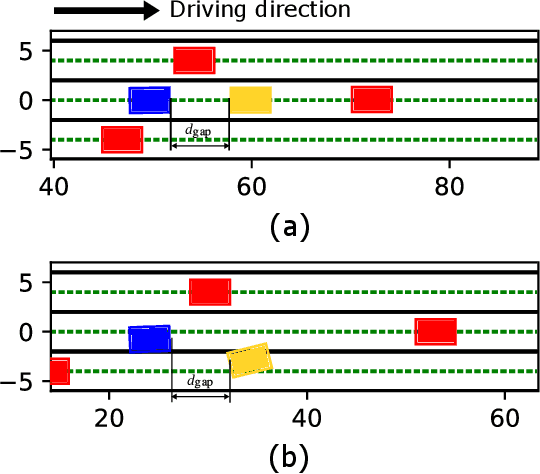
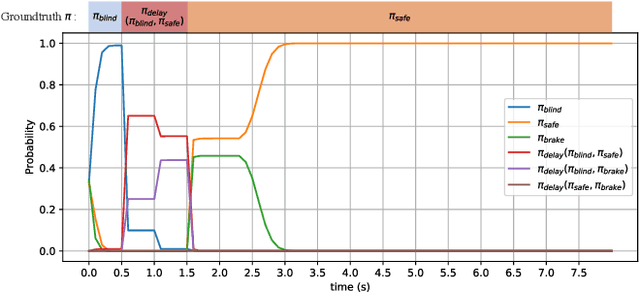
The driver warning system that alerts the human driver about potential risks during driving is a key feature of an advanced driver assistance system. Existing driver warning technologies, mainly the forward collision warning and unsafe lane change warning, can reduce the risk of collision caused by human errors. However, the current design methods have several major limitations. Firstly, the warnings are mainly generated in a one-shot manner without modeling the ego driver's reactions and surrounding objects, which reduces the flexibility and generality of the system over different scenarios. Additionally, the triggering conditions of warning are mostly rule-based threshold-checking given the current state, which lacks the prediction of the potential risk in a sufficiently long future horizon. In this work, we study the problem of optimally generating driver warnings by considering the interactions among the generated warning, the driver behavior, and the states of ego and surrounding vehicles on a long horizon. The warning generation problem is formulated as a partially observed Markov decision process (POMDP). An optimal warning generation framework is proposed as a solution to the proposed POMDP. The simulation experiments demonstrate the superiority of the proposed solution to the existing warning generation methods.
Estimating Ego-Body Pose from Doubly Sparse Egocentric Video Data
Nov 05, 2024



We study the problem of estimating the body movements of a camera wearer from egocentric videos. Current methods for ego-body pose estimation rely on temporally dense sensor data, such as IMU measurements from spatially sparse body parts like the head and hands. However, we propose that even temporally sparse observations, such as hand poses captured intermittently from egocentric videos during natural or periodic hand movements, can effectively constrain overall body motion. Naively applying diffusion models to generate full-body pose from head pose and sparse hand pose leads to suboptimal results. To overcome this, we develop a two-stage approach that decomposes the problem into temporal completion and spatial completion. First, our method employs masked autoencoders to impute hand trajectories by leveraging the spatiotemporal correlations between the head pose sequence and intermittent hand poses, providing uncertainty estimates. Subsequently, we employ conditional diffusion models to generate plausible full-body motions based on these temporally dense trajectories of the head and hands, guided by the uncertainty estimates from the imputation. The effectiveness of our method was rigorously tested and validated through comprehensive experiments conducted on various HMD setup with AMASS and Ego-Exo4D datasets.
Disentangled Neural Relational Inference for Interpretable Motion Prediction
Jan 07, 2024Effective interaction modeling and behavior prediction of dynamic agents play a significant role in interactive motion planning for autonomous robots. Although existing methods have improved prediction accuracy, few research efforts have been devoted to enhancing prediction model interpretability and out-of-distribution (OOD) generalizability. This work addresses these two challenging aspects by designing a variational auto-encoder framework that integrates graph-based representations and time-sequence models to efficiently capture spatio-temporal relations between interactive agents and predict their dynamics. Our model infers dynamic interaction graphs in a latent space augmented with interpretable edge features that characterize the interactions. Moreover, we aim to enhance model interpretability and performance in OOD scenarios by disentangling the latent space of edge features, thereby strengthening model versatility and robustness. We validate our approach through extensive experiments on both simulated and real-world datasets. The results show superior performance compared to existing methods in modeling spatio-temporal relations, motion prediction, and identifying time-invariant latent features.
Rank2Tell: A Multimodal Driving Dataset for Joint Importance Ranking and Reasoning
Sep 12, 2023The widespread adoption of commercial autonomous vehicles (AVs) and advanced driver assistance systems (ADAS) may largely depend on their acceptance by society, for which their perceived trustworthiness and interpretability to riders are crucial. In general, this task is challenging because modern autonomous systems software relies heavily on black-box artificial intelligence models. Towards this goal, this paper introduces a novel dataset, Rank2Tell, a multi-modal ego-centric dataset for Ranking the importance level and Telling the reason for the importance. Using various close and open-ended visual question answering, the dataset provides dense annotations of various semantic, spatial, temporal, and relational attributes of various important objects in complex traffic scenarios. The dense annotations and unique attributes of the dataset make it a valuable resource for researchers working on visual scene understanding and related fields. Further, we introduce a joint model for joint importance level ranking and natural language captions generation to benchmark our dataset and demonstrate performance with quantitative evaluations.
DIDER: Discovering Interpretable Dynamically Evolving Relations
Aug 22, 2022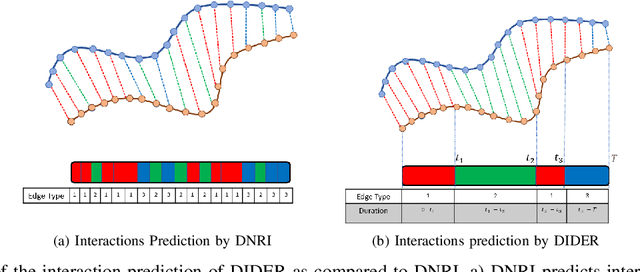
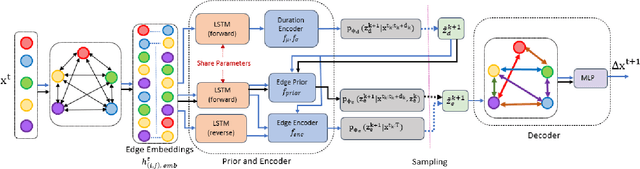
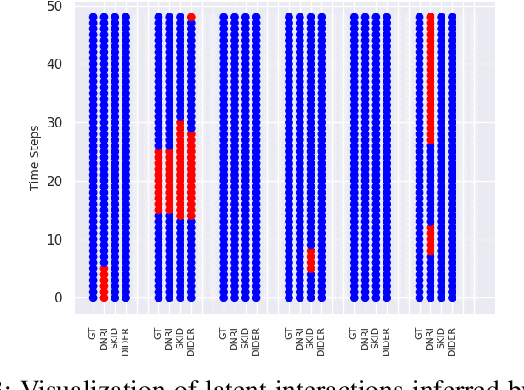
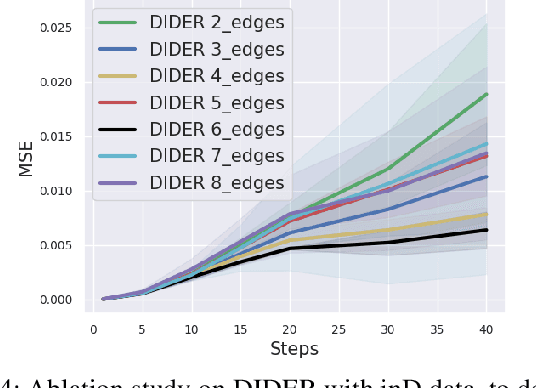
Effective understanding of dynamically evolving multiagent interactions is crucial to capturing the underlying behavior of agents in social systems. It is usually challenging to observe these interactions directly, and therefore modeling the latent interactions is essential for realizing the complex behaviors. Recent work on Dynamic Neural Relational Inference (DNRI) captures explicit inter-agent interactions at every step. However, prediction at every step results in noisy interactions and lacks intrinsic interpretability without post-hoc inspection. Moreover, it requires access to ground truth annotations to analyze the predicted interactions, which are hard to obtain. This paper introduces DIDER, Discovering Interpretable Dynamically Evolving Relations, a generic end-to-end interaction modeling framework with intrinsic interpretability. DIDER discovers an interpretable sequence of inter-agent interactions by disentangling the task of latent interaction prediction into sub-interaction prediction and duration estimation. By imposing the consistency of a sub-interaction type over an extended time duration, the proposed framework achieves intrinsic interpretability without requiring any post-hoc inspection. We evaluate DIDER on both synthetic and real-world datasets. The experimental results demonstrate that modeling disentangled and interpretable dynamic relations improves performance on trajectory forecasting tasks.
Domain Knowledge Driven Pseudo Labels for Interpretable Goal-Conditioned Interactive Trajectory Prediction
Apr 05, 2022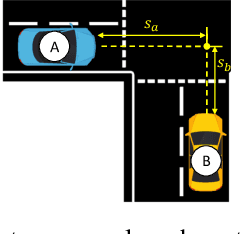
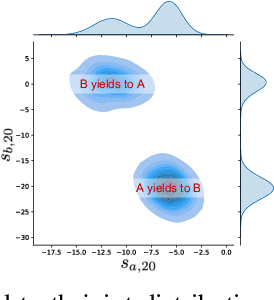
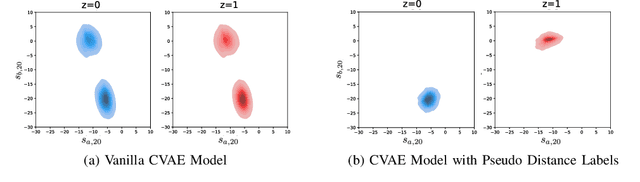
Motion forecasting in highly interactive scenarios is a challenging problem in autonomous driving. In such scenarios, we need to accurately predict the joint behavior of interacting agents to ensure the safe and efficient navigation of autonomous vehicles. Recently, goal-conditioned methods have gained increasing attention due to their advantage in performance and their ability to capture the multimodality in trajectory distribution. In this work, we study the joint trajectory prediction problem with the goal-conditioned framework. In particular, we introduce a conditional-variational-autoencoder-based (CVAE) model to explicitly encode different interaction modes into the latent space. However, we discover that the vanilla model suffers from posterior collapse and cannot induce an informative latent space as desired. To address these issues, we propose a novel approach to avoid KL vanishing and induce an interpretable interactive latent space with pseudo labels. The pseudo labels allow us to incorporate arbitrary domain knowledge on interaction. We motivate the proposed method using an illustrative toy example. In addition, we validate our framework on the Waymo Open Motion Dataset with both quantitative and qualitative evaluations.
Novel Compliant omnicrawler-wheel transforming module
Jul 10, 2018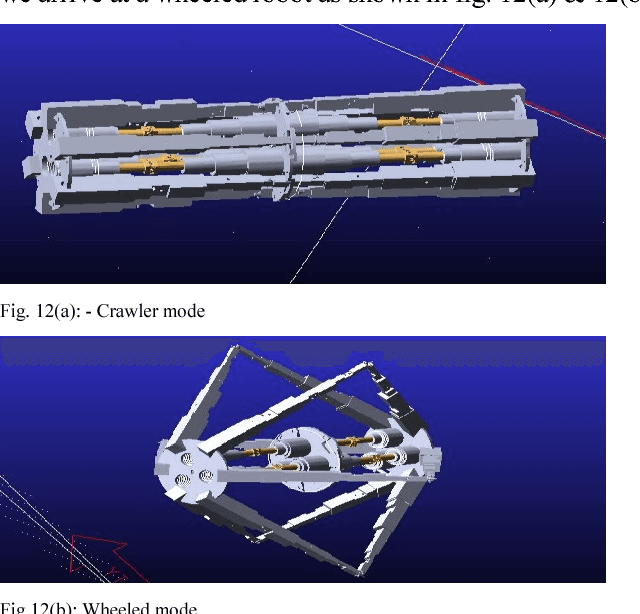
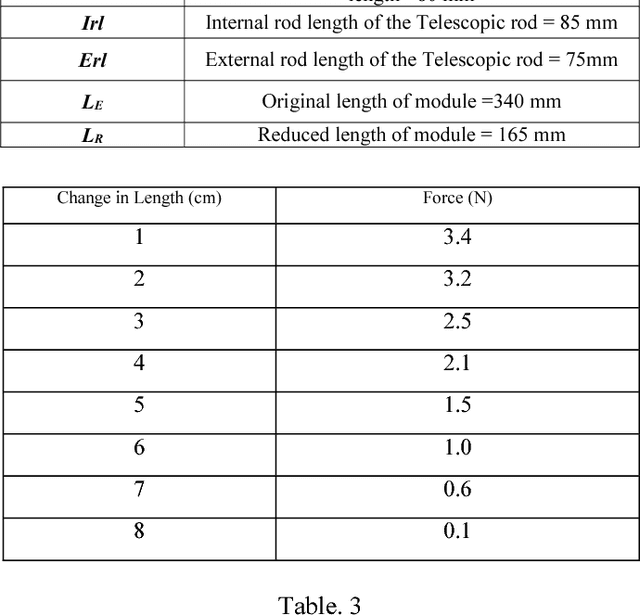
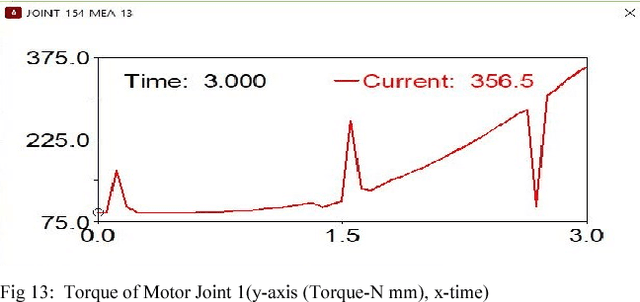

This paper presents a novel design of a crawler robot which is capable of transforming its chassis from an Omni crawler mode to a large-sized wheel mode using a novel mechanism. The transformation occurs without any additional actuators. Interestingly the robot can transform into a large diameter and small width wheel which enhances its maneuverability like small turning radius and fast/efficient locomotion. This paper contributes on improving the locomotion mode of previously developed hybrid compliant omnicrawler robot CObRaSO. In addition to legged and tracked mechanism, CObRaSO can now display large wheel mode which contributes to its locomotion capabilities. Mechanical design of the robot has been explained in a detailed manner in this paper and also the transforming experiment and torque analysis has been shown clearly