 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Knowledge Driven Pseudo Labels for Interpretable Goal-Conditioned Interactive Trajectory Prediction
Paper and Code
Apr 05, 2022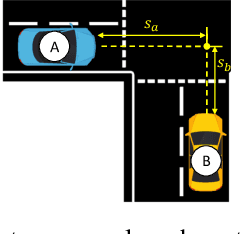
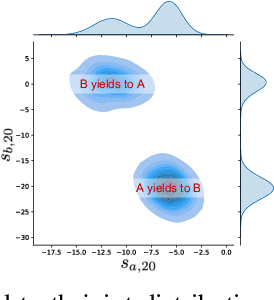
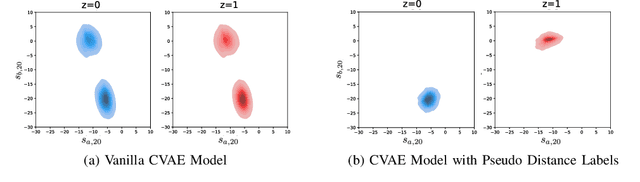
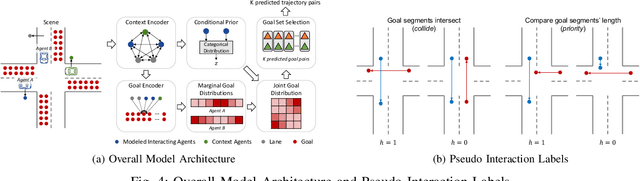
Motion forecasting in highly interactive scenarios is a challenging problem in autonomous driving. In such scenarios, we need to accurately predict the joint behavior of interacting agents to ensure the safe and efficient navigation of autonomous vehicles. Recently, goal-conditioned methods have gained increasing attention due to their advantage in performance and their ability to capture the multimodality in trajectory distribution. In this work, we study the joint trajectory prediction problem with the goal-conditioned framework. In particular, we introduce a conditional-variational-autoencoder-based (CVAE) model to explicitly encode different interaction modes into the latent space. However, we discover that the vanilla model suffers from posterior collapse and cannot induce an informative latent space as desired. To address these issues, we propose a novel approach to avoid KL vanishing and induce an interpretable interactive latent space with pseudo labels. The pseudo labels allow us to incorporate arbitrary domain knowledge on interaction. We motivate the proposed method using an illustrative toy example. In addition, we validate our framework on the Waymo Open Motion Dataset with both quantitative and qualitative evaluations.