 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADEPT: Adaptive Dynamic Early-Exit Process for Transformers
Jan 07, 2026The inference of large language models imposes significant computational workloads, often requiring the processing of billions of parameters. Although early-exit strategies have proven effective in reducing computational demands by halting inference earlier, they apply either to only the first token in the generation phase or at the prompt level in the prefill phase. Thus, the Key-Value (KV) cache for skipped layers remains a bottleneck for subsequent token generation, limiting the benefits of early exit. We introduce ADEPT (Adaptive Dynamic Early-exit Process for Transformers), a novel approach designed to overcome this issue and enable dynamic early exit in both the prefill and generation phases. The proposed adaptive token-level early-exit mechanism adjusts computation dynamically based on token complexity, optimizing efficiency without compromising performance. ADEPT further enhances KV generation procedure by decoupling sequential dependencies in skipped layers, making token-level early exit more practical. Experimental results demonstrate that ADEPT improves efficiency by up to 25% in language generation tasks and achieves a 4x speed-up in downstream classification tasks, with up to a 45% improvement in performance.
COPAL: Continual Pruning in Large Language Generative Models
May 02, 2024Adapting pre-trained large language models to different domains in natural language processing requires two key considerations: high computational demands and model's inability to continual adaptation. To simultaneously address both issues, this paper presents COPAL (COntinual Pruning in Adaptive Language settings), an algorithm developed for pruning large language generative models under a continual model adaptation setting. While avoiding resource-heavy finetuning or retraining, our pruning process is guided by the proposed sensitivity analysis. The sensitivity effectively measures model's ability to withstand perturbations introduced by the new dataset and finds model's weights that are relevant for all encountered datasets. As a result, COPAL allows seamless model adaptation to new domains while enhancing the resource efficiency. Our empirical evaluation on a various size of LLMs show that COPAL outperforms baseline models, demonstrating its efficacy in efficiency and adaptability.
Object-centric Video Representation for Long-term Action Anticipation
Oct 31, 2023



This paper focuses on building object-centric representations for long-term action anticipation in videos. Our key motivation is that objects provide important cues to recognize and predict human-object interactions, especially when the predictions are longer term, as an observed "background" object could be used by the human actor in the future. We observe that existing object-based video recognition frameworks either assume the existence of in-domain supervised object detectors or follow a fully weakly-supervised pipeline to infer object locations from action labels. We propose to build object-centric video representations by leveraging visual-language pretrained models. This is achieved by "object prompts", an approach to extract task-specific object-centric representations from general-purpose pretrained models without finetuning. To recognize and predict human-object interactions, we use a Transformer-based neural architecture which allows the "retrieval" of relevant objects for action anticipation at various time scales. We conduct extensive evaluations on the Ego4D, 50Salads, and EGTEA Gaze+ benchmarks. Both quantitative and qualitative results confirm the effectiveness of our proposed method.
Rank2Tell: A Multimodal Driving Dataset for Joint Importance Ranking and Reasoning
Sep 12, 2023The widespread adoption of commercial autonomous vehicles (AVs) and advanced driver assistance systems (ADAS) may largely depend on their acceptance by society, for which their perceived trustworthiness and interpretability to riders are crucial. In general, this task is challenging because modern autonomous systems software relies heavily on black-box artificial intelligence models. Towards this goal, this paper introduces a novel dataset, Rank2Tell, a multi-modal ego-centric dataset for Ranking the importance level and Telling the reason for the importance. Using various close and open-ended visual question answering, the dataset provides dense annotations of various semantic, spatial, temporal, and relational attributes of various important objects in complex traffic scenarios. The dense annotations and unique attributes of the dataset make it a valuable resource for researchers working on visual scene understanding and related fields. Further, we introduce a joint model for joint importance level ranking and natural language captions generation to benchmark our dataset and demonstrate performance with quantitative evaluations.
Uncovering the Missing Pattern: Unified Framework Towards Trajectory Imputation and Prediction
Mar 28, 2023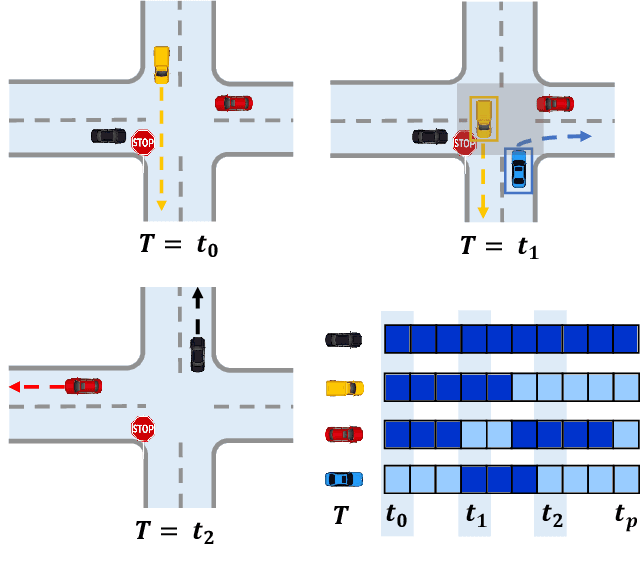
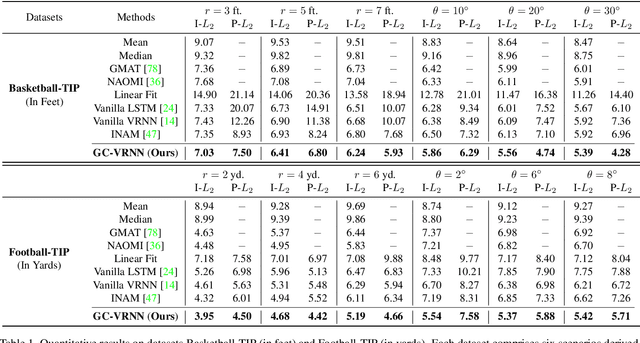
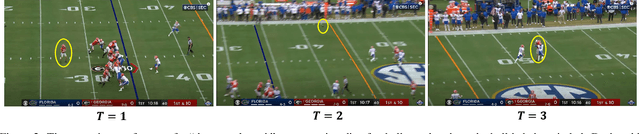

Trajectory prediction is a crucial undertaking in understanding entity movement or human behavior from observed sequences. However, current methods often assume that the observed sequences are complete while ignoring the potential for missing values caused by object occlusion, scope limitation, sensor failure, etc. This limitation inevitably hinders the accuracy of trajectory prediction. To address this issue, our paper presents a unified framework, the Graph-based Conditional Variational Recurrent Neural Network (GC-VRNN), which can perform trajectory imputation and prediction simultaneously. Specifically, we introduce a novel Multi-Space Graph Neural Network (MS-GNN) that can extract spatial features from incomplete observations and leverage missing patterns. Additionally, we employ a Conditional VRNN with a specifically designed Temporal Decay (TD) module to capture temporal dependencies and temporal missing patterns in incomplete trajectories. The inclusion of the TD module allows for valuable information to be conveyed through the temporal flow. We also curate and benchmark three practical datasets for the joint problem of trajectory imputation and prediction. Extensive experiments verify the exceptional performance of our proposed method. As far as we know, this is the first work to address the lack of benchmarks and techniques for trajectory imputation and prediction in a unified manner.
DRAMA: Joint Risk Localization and Captioning in Driving
Oct 05, 2022
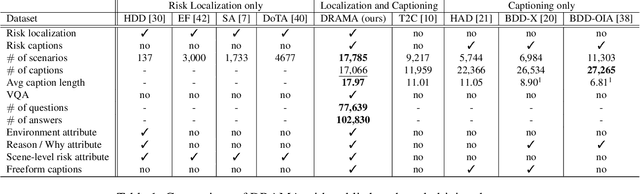

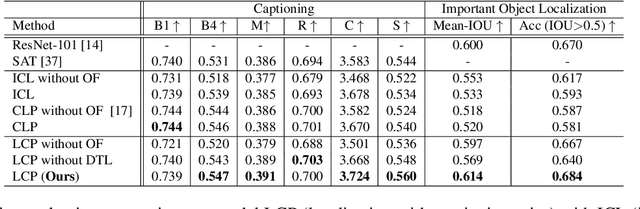
Considering the functionality of situational awareness in safety-critical automation systems, the perception of risk in driving scenes and its explainability is of particular importance for autonomous and cooperative driving. Toward this goal, this paper proposes a new research direction of joint risk localization in driving scenes and its risk explanation as a natural language description. Due to the lack of standard benchmarks, we collected a large-scale dataset, DRAMA (Driving Risk Assessment Mechanism with A captioning module), which consists of 17,785 interactive driving scenarios collected in Tokyo, Japan. Our DRAMA dataset accommodates video- and object-level questions on driving risks with associated important objects to achieve the goal of visual captioning as a free-form language description utilizing closed and open-ended responses for multi-level questions, which can be used to evaluate a range of visual captioning capabilities in driving scenarios. We make this data available to the community for further research. Using DRAMA, we explore multiple facets of joint risk localization and captioning in interactive driving scenarios. In particular, we benchmark various multi-task prediction architectures and provide a detailed analysis of joint risk localization and risk captioning. The data set is available at https://usa.honda-ri.com/drama
DIDER: Discovering Interpretable Dynamically Evolving Relations
Aug 22, 2022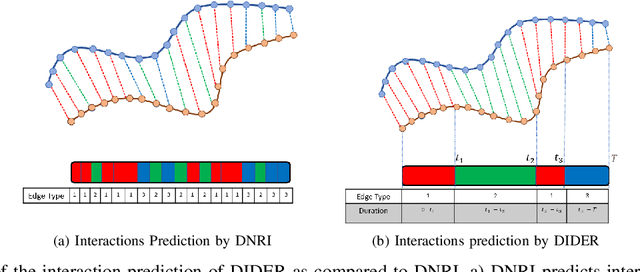
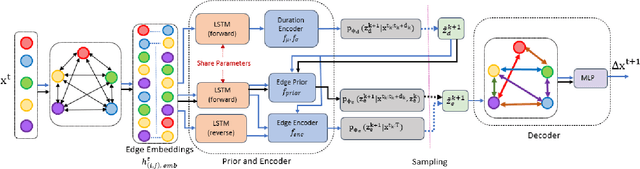
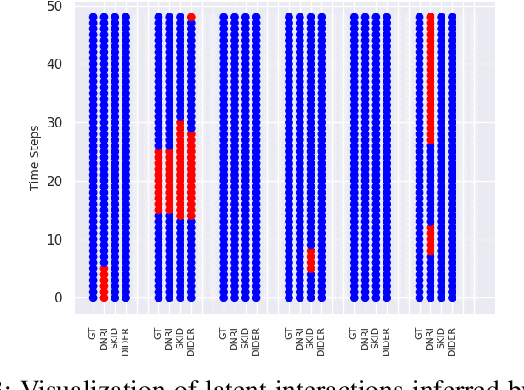
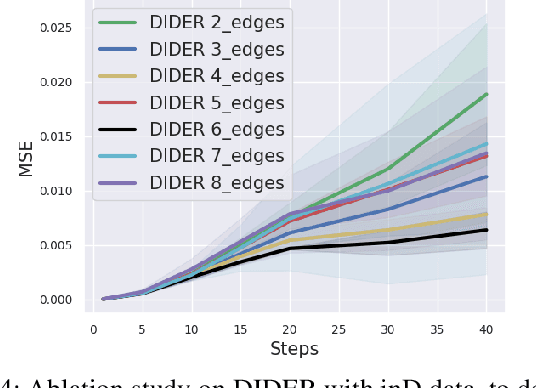
Effective understanding of dynamically evolving multiagent interactions is crucial to capturing the underlying behavior of agents in social systems. It is usually challenging to observe these interactions directly, and therefore modeling the latent interactions is essential for realizing the complex behaviors. Recent work on Dynamic Neural Relational Inference (DNRI) captures explicit inter-agent interactions at every step. However, prediction at every step results in noisy interactions and lacks intrinsic interpretability without post-hoc inspection. Moreover, it requires access to ground truth annotations to analyze the predicted interactions, which are hard to obtain. This paper introduces DIDER, Discovering Interpretable Dynamically Evolving Relations, a generic end-to-end interaction modeling framework with intrinsic interpretability. DIDER discovers an interpretable sequence of inter-agent interactions by disentangling the task of latent interaction prediction into sub-interaction prediction and duration estimation. By imposing the consistency of a sub-interaction type over an extended time duration, the proposed framework achieves intrinsic interpretability without requiring any post-hoc inspection. We evaluate DIDER on both synthetic and real-world datasets. The experimental results demonstrate that modeling disentangled and interpretable dynamic relations improves performance on trajectory forecasting tasks.
Domain Knowledge Driven Pseudo Labels for Interpretable Goal-Conditioned Interactive Trajectory Prediction
Apr 05, 2022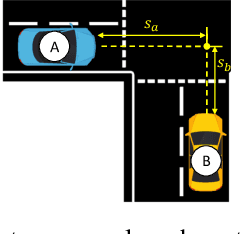
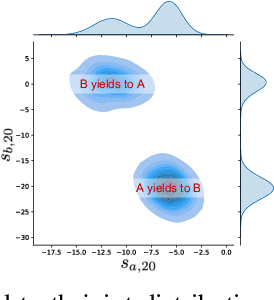
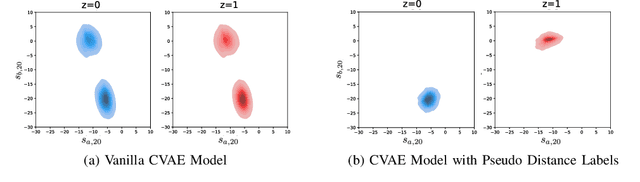
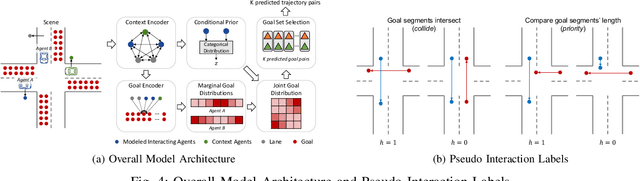
Motion forecasting in highly interactive scenarios is a challenging problem in autonomous driving. In such scenarios, we need to accurately predict the joint behavior of interacting agents to ensure the safe and efficient navigation of autonomous vehicles. Recently, goal-conditioned methods have gained increasing attention due to their advantage in performance and their ability to capture the multimodality in trajectory distribution. In this work, we study the joint trajectory prediction problem with the goal-conditioned framework. In particular, we introduce a conditional-variational-autoencoder-based (CVAE) model to explicitly encode different interaction modes into the latent space. However, we discover that the vanilla model suffers from posterior collapse and cannot induce an informative latent space as desired. To address these issues, we propose a novel approach to avoid KL vanishing and induce an interpretable interactive latent space with pseudo labels. The pseudo labels allow us to incorporate arbitrary domain knowledge on interaction. We motivate the proposed method using an illustrative toy example. In addition, we validate our framework on the Waymo Open Motion Dataset with both quantitative and qualitative evaluations.
Weakly-Supervised Online Action Segmentation in Multi-View Instructional Videos
Mar 24, 2022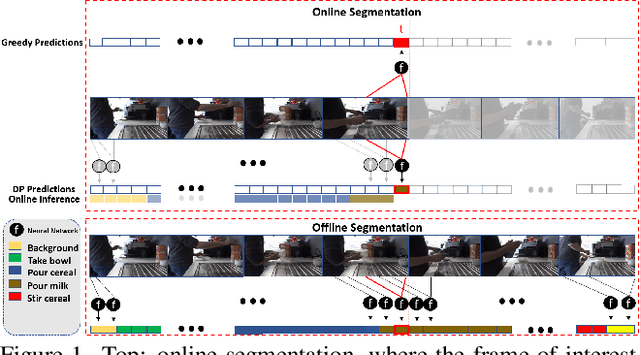
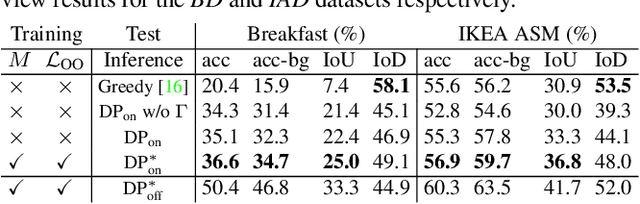
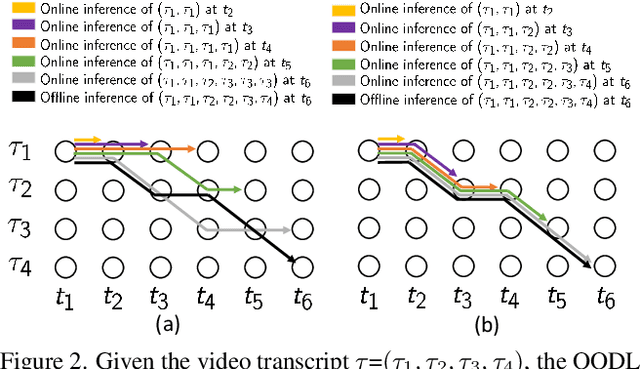
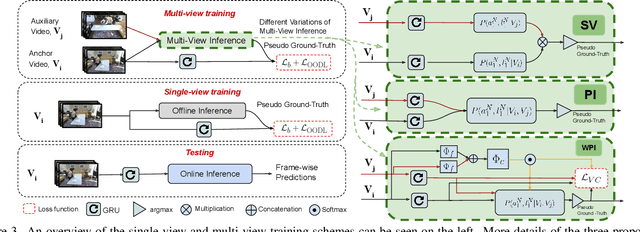
This paper addresses a new problem of weakly-supervised online action segmentation in instructional videos. We present a framework to segment streaming videos online at test time using Dynamic Programming and show its advantages over greedy sliding window approach. We improve our framework by introducing the Online-Offline Discrepancy Loss (OODL) to encourage the segmentation results to have a higher temporal consistency. Furthermore, only during training, we exploit frame-wise correspondence between multiple views as supervision for training weakly-labeled instructional videos. In particular, we investigate three different multi-view inference techniques to generate more accurate frame-wise pseudo ground-truth with no additional annotation cost. We present results and ablation studies on two benchmark multi-view datasets, Breakfast and IKEA ASM. Experimental results show efficacy of the proposed methods both qualitatively and quantitatively in two domains of cooking and assembly.
Important Object Identification with Semi-Supervised Learning for Autonomous Driving
Mar 05, 2022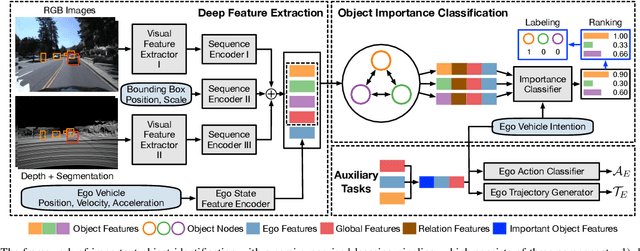
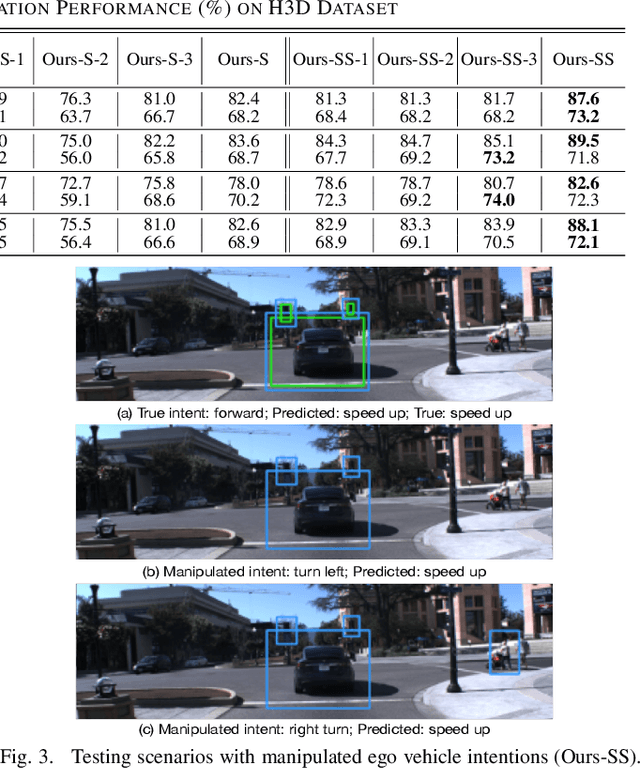
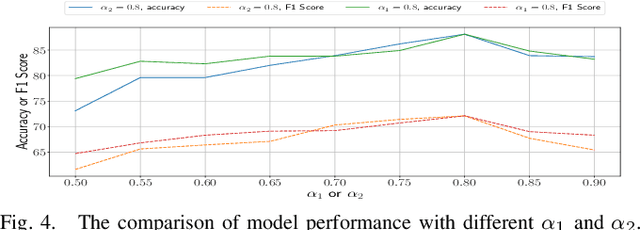
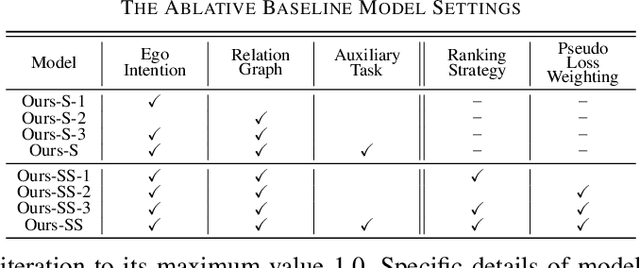
Accurate identification of important objects in the scene is a prerequisite for safe and high-quality decision making and motion planning of intelligent agents (e.g., autonomous vehicles) that navigate in complex and dynamic environments. Most existing approaches attempt to employ attention mechanisms to learn importance weights associated with each object indirectly via various tasks (e.g., trajectory prediction), which do not enforce direct supervision on the importance estimation. In contrast, we tackle this task in an explicit way and formulate it as a binary classification ("important" or "unimportant") problem. We propose a novel approach for important object identification in egocentric driving scenarios with relational reasoning on the objects in the scene. Besides, since human annotations are limited and expensive to obtain, we present a semi-supervised learning pipeline to enable the model to learn from unlimited unlabeled data. Moreover, we propose to leverage the auxiliary tasks of ego vehicle behavior prediction to further improve the accuracy of importance estimation. The proposed approach is evaluated on a public egocentric driving dataset (H3D) collected in complex traffic scenarios. A detailed ablative study is conducted to demonstrate the effectiveness of each model component and the training strategy. Our approach also outperforms rule-based baselines by a large margin.