 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Aware Weakly-Supervised Action Segmentation
Apr 08, 2025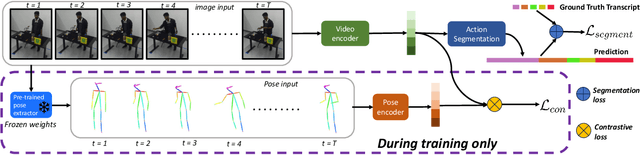
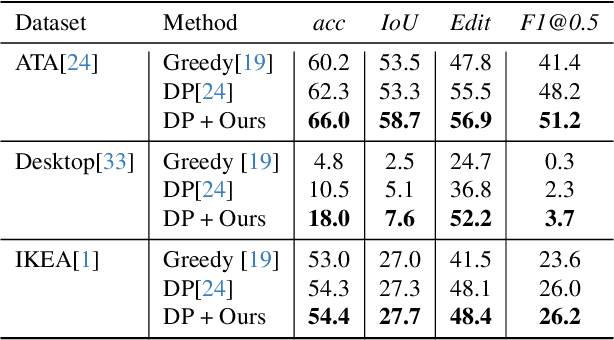
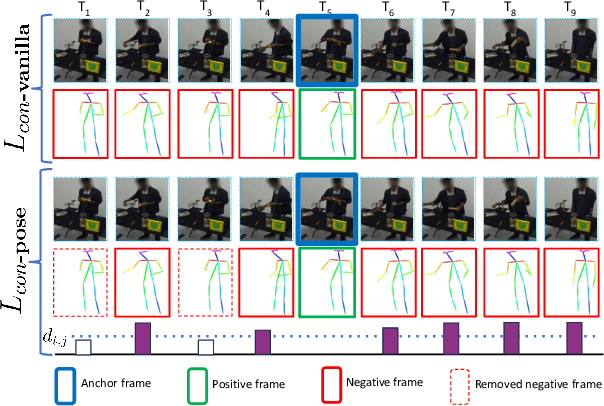
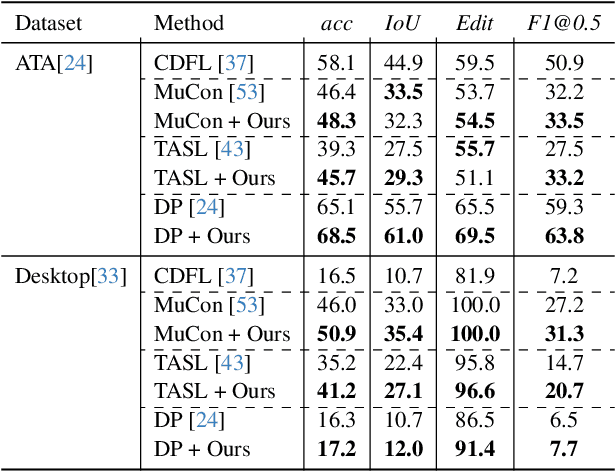
Understanding human behavior is an important problem in the pursuit of visual intelligence. A challenge in this endeavor is the extensive and costly effort required to accurately label action segments. To address this issue, we consider learning methods that demand minimal supervision for segmentation of human actions in long instructional videos. Specifically, we introduce a weakly-supervised framework that uniquely incorporates pose knowledge during training while omitting its use during inference, thereby distilling pose knowledge pertinent to each action component. We propose a pose-inspired contrastive loss as a part of the whole weakly-supervised framework which is trained to distinguish action boundaries more effectively. Our approach, validated through extensive experiments on representative datasets, outperforms previous state-of-the-art (SOTA) in segmenting long instructional videos under both online and offline settings. Additionally, we demonstrate the framework's adaptability to various segmentation backbones and pose extractors across different datasets.
Towards Zero-Shot Anomaly Detection and Reasoning with Multimodal Large Language Models
Feb 11, 2025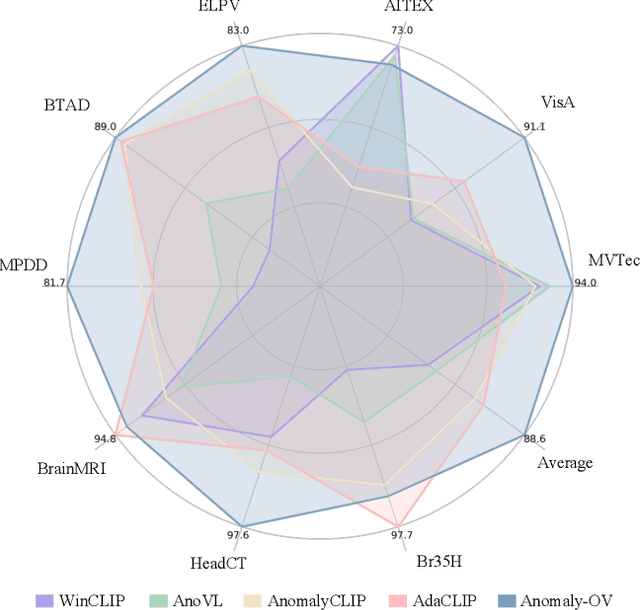
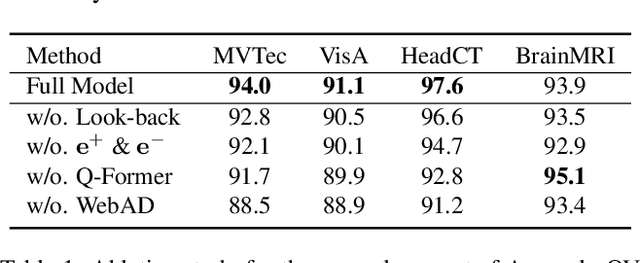

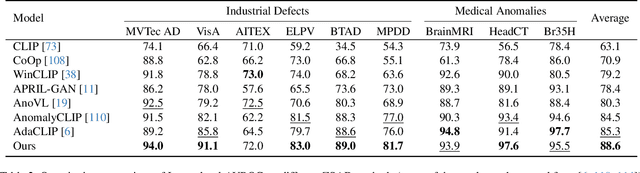
Zero-Shot Anomaly Detection (ZSAD) is an emerging AD paradigm. Unlike the traditional unsupervised AD setting that requires a large number of normal samples to train a model, ZSAD is more practical for handling data-restricted real-world scenarios. Recently, Multimodal Large Language Models (MLLMs) have shown revolutionary reasoning capabilities in various vision tasks. However, the reasoning of image abnormalities remains underexplored due to the lack of corresponding datasets and benchmarks. To facilitate research in AD & reasoning, we establish the first visual instruction tuning dataset, Anomaly-Instruct-125k, and the evaluation benchmark, VisA-D&R. Through investigation with our benchmark, we reveal that current MLLMs like GPT-4o cannot accurately detect and describe fine-grained anomalous details in images. To address this, we propose Anomaly-OneVision (Anomaly-OV), the first specialist visual assistant for ZSAD and reasoning. Inspired by human behavior in visual inspection, Anomaly-OV leverages a Look-Twice Feature Matching (LTFM) mechanism to adaptively select and emphasize abnormal visual tokens. Extensive experiments demonstrate that Anomaly-OV achieves significant improvements over advanced generalist models in both detection and reasoning. Extensions to medical and 3D AD are provided for future study. The link to our project page: https://xujiacong.github.io/Anomaly-OV/
ACE: Action Concept Enhancement of Video-Language Models in Procedural Videos
Nov 23, 2024
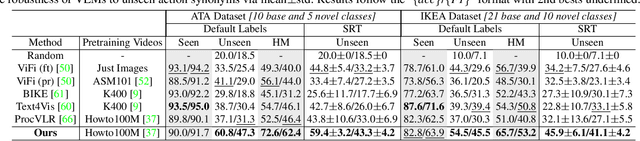
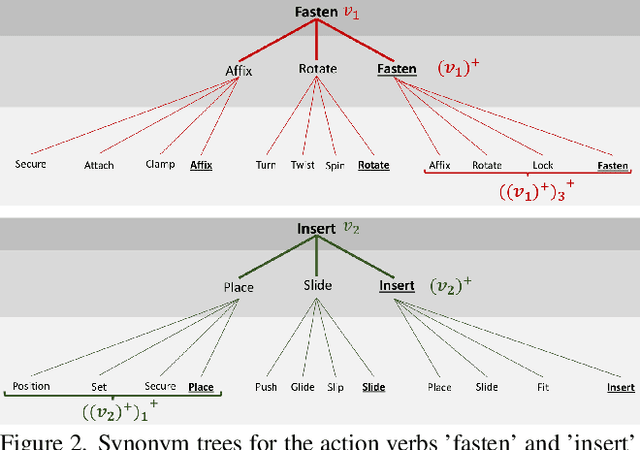
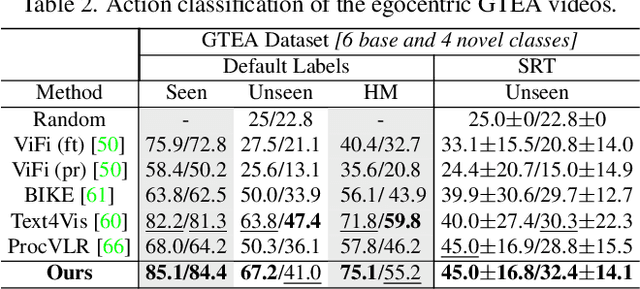
Vision-language models (VLMs) are capable of recognizing unseen actions. However, existing VLMs lack intrinsic understanding of procedural action concepts. Hence, they overfit to fixed labels and are not invariant to unseen action synonyms. To address this, we propose a simple fine-tuning technique, Action Concept Enhancement (ACE), to improve the robustness and concept understanding of VLMs in procedural action classification. ACE continually incorporates augmented action synonyms and negatives in an auxiliary classification loss by stochastically replacing fixed labels during training. This creates new combinations of action labels over the course of fine-tuning and prevents overfitting to fixed action representations. We show the enhanced concept understanding of our VLM, by visualizing the alignment of encoded embeddings of unseen action synonyms in the embedding space. Our experiments on the ATA, IKEA and GTEA datasets demonstrate the efficacy of ACE in domains of cooking and assembly leading to significant improvements in zero-shot action classification while maintaining competitive performance on seen actions.
DRAMA: Joint Risk Localization and Captioning in Driving
Oct 05, 2022
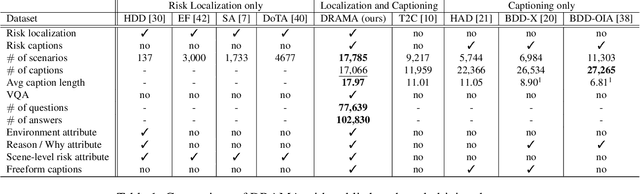

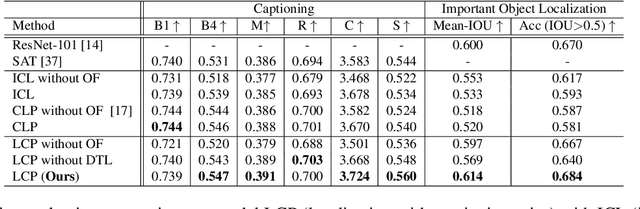
Considering the functionality of situational awareness in safety-critical automation systems, the perception of risk in driving scenes and its explainability is of particular importance for autonomous and cooperative driving. Toward this goal, this paper proposes a new research direction of joint risk localization in driving scenes and its risk explanation as a natural language description. Due to the lack of standard benchmarks, we collected a large-scale dataset, DRAMA (Driving Risk Assessment Mechanism with A captioning module), which consists of 17,785 interactive driving scenarios collected in Tokyo, Japan. Our DRAMA dataset accommodates video- and object-level questions on driving risks with associated important objects to achieve the goal of visual captioning as a free-form language description utilizing closed and open-ended responses for multi-level questions, which can be used to evaluate a range of visual captioning capabilities in driving scenarios. We make this data available to the community for further research. Using DRAMA, we explore multiple facets of joint risk localization and captioning in interactive driving scenarios. In particular, we benchmark various multi-task prediction architectures and provide a detailed analysis of joint risk localization and risk captioning. The data set is available at https://usa.honda-ri.com/drama
Weakly-Supervised Online Action Segmentation in Multi-View Instructional Videos
Mar 24, 2022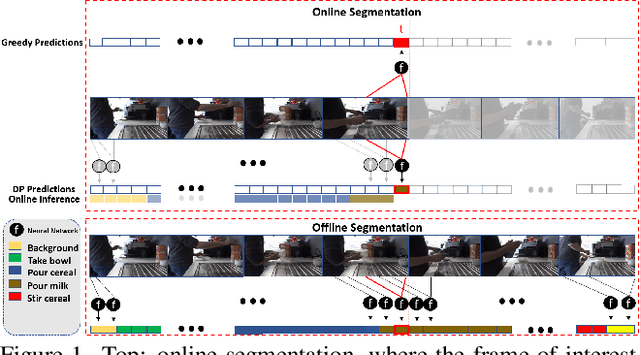
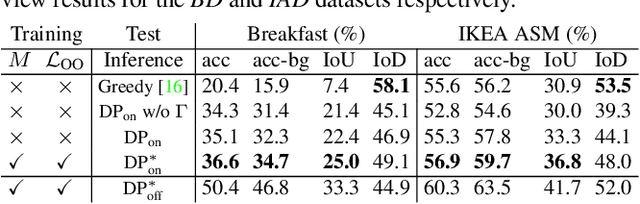
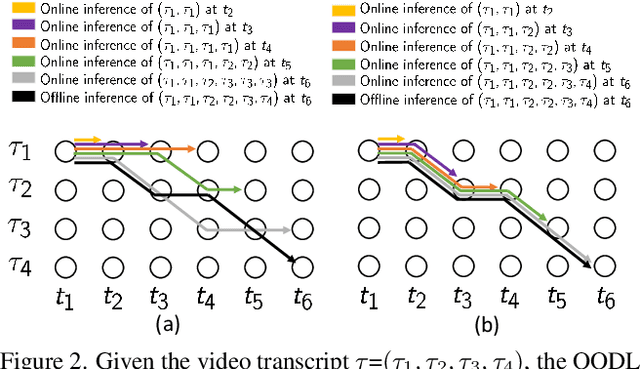
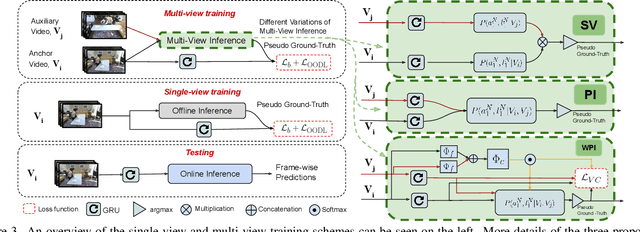
This paper addresses a new problem of weakly-supervised online action segmentation in instructional videos. We present a framework to segment streaming videos online at test time using Dynamic Programming and show its advantages over greedy sliding window approach. We improve our framework by introducing the Online-Offline Discrepancy Loss (OODL) to encourage the segmentation results to have a higher temporal consistency. Furthermore, only during training, we exploit frame-wise correspondence between multiple views as supervision for training weakly-labeled instructional videos. In particular, we investigate three different multi-view inference techniques to generate more accurate frame-wise pseudo ground-truth with no additional annotation cost. We present results and ablation studies on two benchmark multi-view datasets, Breakfast and IKEA ASM. Experimental results show efficacy of the proposed methods both qualitatively and quantitatively in two domains of cooking and assembly.
SSP: Single Shot Future Trajectory Prediction
Apr 13, 2020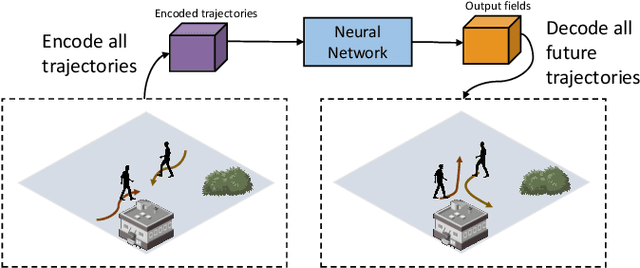
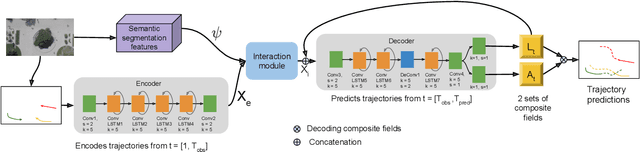
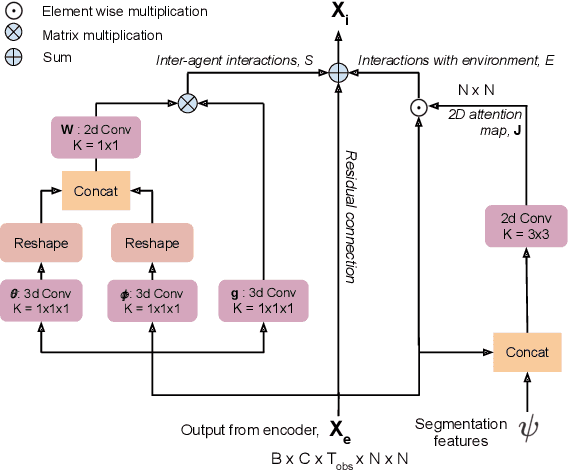
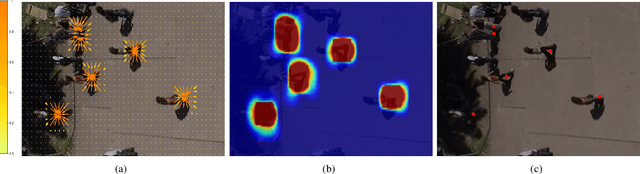
We propose a robust solution to future trajectory forecast, which can be practically applicable to autonomous agents in highly crowded environments. For this, three aspects are particularly addressed in this paper. First, we use composite fields to predict future locations of all road agents in a single-shot, which results in a constant time complexity, regardless of the number of agents in the scene. Second, interactions between agents are modeled as a non-local response, enabling spatial relationships between different locations to be captured temporally as well (i.e., in spatio-temporal interactions). Third, the semantic context of the scene are modeled and take into account the environmental constraints that potentially influence the future motion. To this end, we validate the robustness of the proposed approach using the ETH, UCY, and SDD datasets and highlight its practical functionality compared to the current state-of-the-art methods.
Dynamic Traffic Scene Classification with Space-Time Coherence
May 29, 2019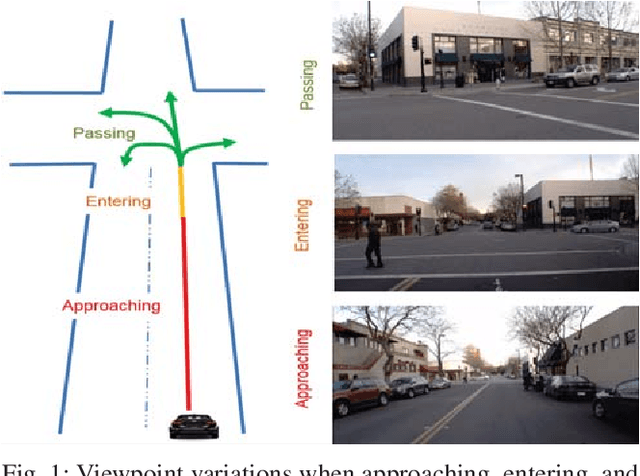

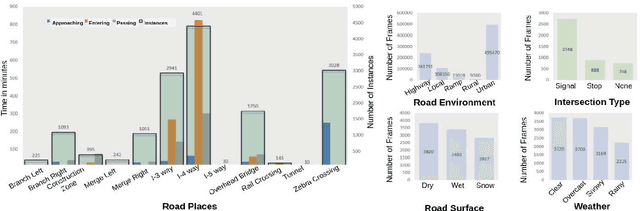

This paper examines the problem of dynamic traffic scene classification under space-time variations in viewpoint that arise from video captured on-board a moving vehicle. Solutions to this problem are important for realization of effective driving assistance technologies required to interpret or predict road user behavior. Currently, dynamic traffic scene classification has not been adequately addressed due to a lack of benchmark datasets that consider spatiotemporal evolution of traffic scenes resulting from a vehicle's ego-motion. This paper has three main contributions. First, an annotated dataset is released to enable dynamic scene classification that includes 80 hours of diverse high quality driving video data clips collected in the San Francisco Bay area. The dataset includes temporal annotations for road places, road types, weather, and road surface conditions. Second, we introduce novel and baseline algorithms that utilize semantic context and temporal nature of the dataset for dynamic classification of road scenes. Finally, we showcase algorithms and experimental results that highlight how extracted features from scene classification serve as strong priors and help with tactical driver behavior understanding. The results show significant improvement from previously reported driving behavior detection baselines in the literature.
High Quality Prediction of Protein Q8 Secondary Structure by Diverse Neural Network Architectures
Nov 17, 2018
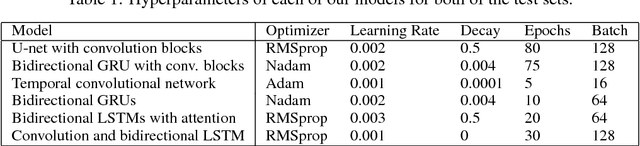
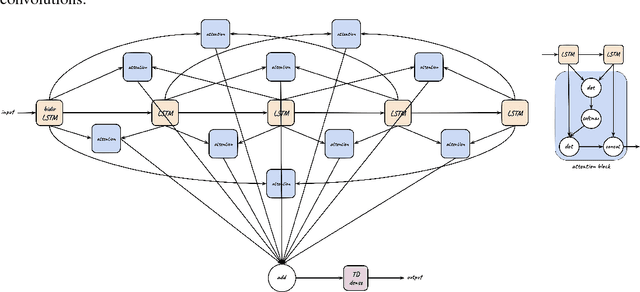
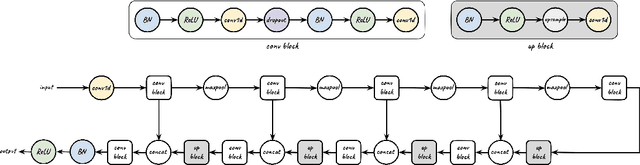
We tackle the problem of protein secondary structure prediction using a common task framework. This lead to the introduction of multiple ideas for neural architectures based on state of the art building blocks, used in this task for the first time. We take a principled machine learning approach, which provides genuine, unbiased performance measures, correcting longstanding errors in the application domain. We focus on the Q8 resolution of secondary structure, an active area for continuously improving methods. We use an ensemble of strong predictors to achieve accuracy of 70.7% (on the CB513 test set using the CB6133filtered training set). These results are statistically indistinguishable from those of the top existing predictors. In the spirit of reproducible research we make our data, models and code available, aiming to set a gold standard for purity of training and testing sets. Such good practices lower entry barriers to this domain and facilitate reproducible, extendable research.
SketchParse : Towards Rich Descriptions for Poorly Drawn Sketches using Multi-Task Hierarchical Deep Networks
Sep 05, 2017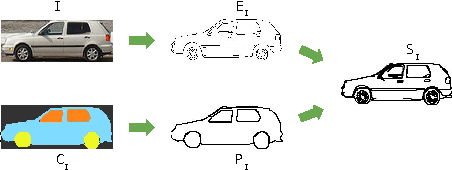

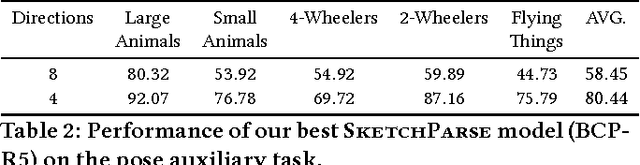

The ability to semantically interpret hand-drawn line sketches, although very challenging, can pave way for novel applications in multimedia. We propose SketchParse, the first deep-network architecture for fully automatic parsing of freehand object sketches. SketchParse is configured as a two-level fully convolutional network. The first level contains shared layers common to all object categories. The second level contains a number of expert sub-networks. Each expert specializes in parsing sketches from object categories which contain structurally similar parts. Effectively, the two-level configuration enables our architecture to scale up efficiently as additional categories are added. We introduce a router layer which (i) relays sketch features from shared layers to the correct expert (ii) eliminates the need to manually specify object category during inference. To bypass laborious part-level annotation, we sketchify photos from semantic object-part image datasets and use them for training. Our architecture also incorporates object pose prediction as a novel auxiliary task which boosts overall performance while providing supplementary information regarding the sketch. We demonstrate SketchParse's abilities (i) on two challenging large-scale sketch datasets (ii) in parsing unseen, semantically related object categories (iii) in improving fine-grained sketch-based image retrieval. As a novel application, we also outline how SketchParse's output can be used to generate caption-style descriptions for hand-drawn sketches.