 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADEPT: Adaptive Dynamic Early-Exit Process for Transformers
Jan 07, 2026The inference of large language models imposes significant computational workloads, often requiring the processing of billions of parameters. Although early-exit strategies have proven effective in reducing computational demands by halting inference earlier, they apply either to only the first token in the generation phase or at the prompt level in the prefill phase. Thus, the Key-Value (KV) cache for skipped layers remains a bottleneck for subsequent token generation, limiting the benefits of early exit. We introduce ADEPT (Adaptive Dynamic Early-exit Process for Transformers), a novel approach designed to overcome this issue and enable dynamic early exit in both the prefill and generation phases. The proposed adaptive token-level early-exit mechanism adjusts computation dynamically based on token complexity, optimizing efficiency without compromising performance. ADEPT further enhances KV generation procedure by decoupling sequential dependencies in skipped layers, making token-level early exit more practical. Experimental results demonstrate that ADEPT improves efficiency by up to 25% in language generation tasks and achieves a 4x speed-up in downstream classification tasks, with up to a 45% improvement in performance.
COPAL: Continual Pruning in Large Language Generative Models
May 02, 2024Adapting pre-trained large language models to different domains in natural language processing requires two key considerations: high computational demands and model's inability to continual adaptation. To simultaneously address both issues, this paper presents COPAL (COntinual Pruning in Adaptive Language settings), an algorithm developed for pruning large language generative models under a continual model adaptation setting. While avoiding resource-heavy finetuning or retraining, our pruning process is guided by the proposed sensitivity analysis. The sensitivity effectively measures model's ability to withstand perturbations introduced by the new dataset and finds model's weights that are relevant for all encountered datasets. As a result, COPAL allows seamless model adaptation to new domains while enhancing the resource efficiency. Our empirical evaluation on a various size of LLMs show that COPAL outperforms baseline models, demonstrating its efficacy in efficiency and adaptability.
DRAMA: Joint Risk Localization and Captioning in Driving
Oct 05, 2022
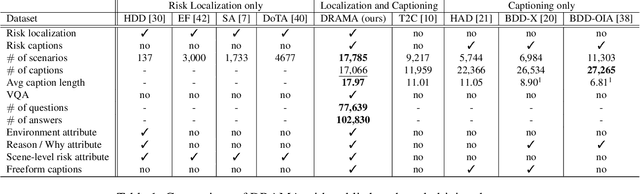

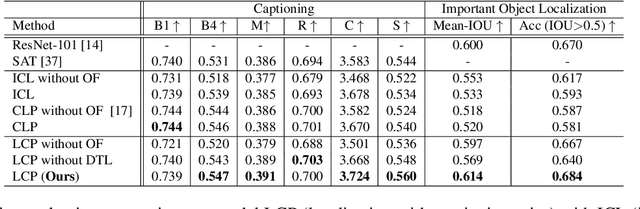
Considering the functionality of situational awareness in safety-critical automation systems, the perception of risk in driving scenes and its explainability is of particular importance for autonomous and cooperative driving. Toward this goal, this paper proposes a new research direction of joint risk localization in driving scenes and its risk explanation as a natural language description. Due to the lack of standard benchmarks, we collected a large-scale dataset, DRAMA (Driving Risk Assessment Mechanism with A captioning module), which consists of 17,785 interactive driving scenarios collected in Tokyo, Japan. Our DRAMA dataset accommodates video- and object-level questions on driving risks with associated important objects to achieve the goal of visual captioning as a free-form language description utilizing closed and open-ended responses for multi-level questions, which can be used to evaluate a range of visual captioning capabilities in driving scenarios. We make this data available to the community for further research. Using DRAMA, we explore multiple facets of joint risk localization and captioning in interactive driving scenarios. In particular, we benchmark various multi-task prediction architectures and provide a detailed analysis of joint risk localization and risk captioning. The data set is available at https://usa.honda-ri.com/drama
Shared Cross-Modal Trajectory Prediction for Autonomous Driving
Nov 15, 2020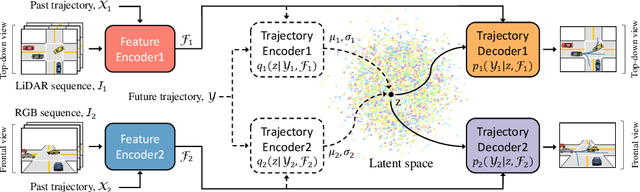
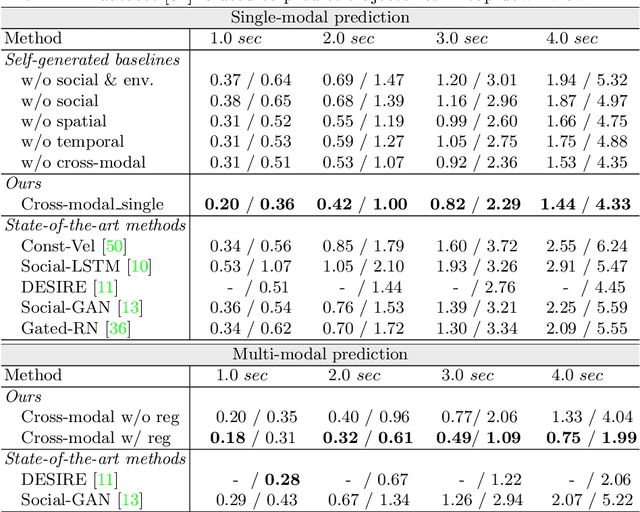
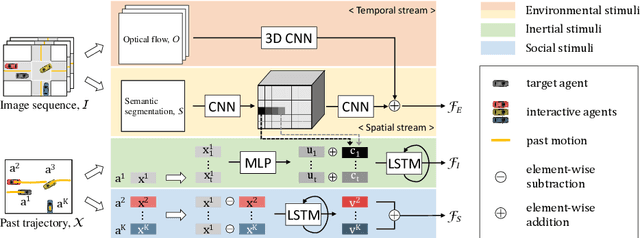
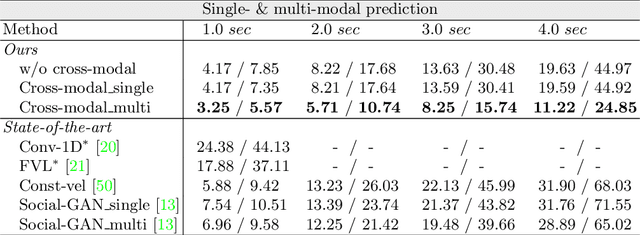
Predicting future trajectories of traffic agents in highly interactive environments is an essential and challenging problem for the safe operation of autonomous driving systems. On the basis of the fact that self-driving vehicles are equipped with various types of sensors (e.g., LiDAR scanner, RGB camera, radar, etc.), we propose a Cross-Modal Embedding framework that aims to benefit from the use of multiple input modalities. At training time, our model learns to embed a set of complementary features in a shared latent space by jointly optimizing the objective functions across different types of input data. At test time, a single input modality (e.g., LiDAR data) is required to generate predictions from the input perspective (i.e., in the LiDAR space), while taking advantages from the model trained with multiple sensor modalities. An extensive evaluation is conducted to show the efficacy of the proposed framework using two benchmark driving datasets.
Optimal Combination of Image Denoisers
May 30, 2018
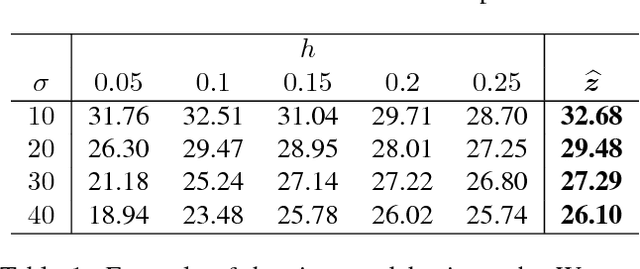
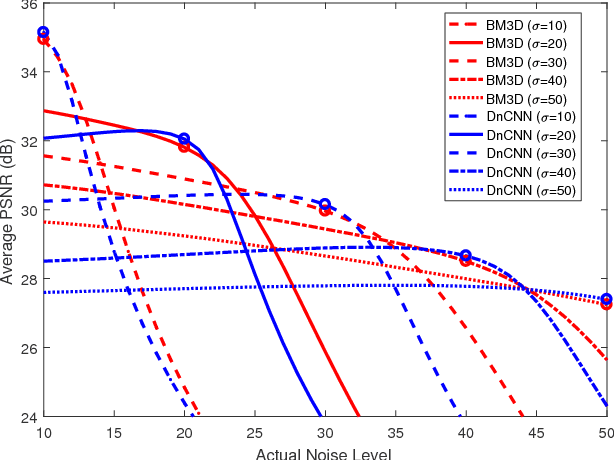

Given a set of image denoisers, each having a different denoising capability, is there a provably optimal way of combining these denoisers to produce an overall better result? An answer to this question is fundamental to designing ensembles of weak estimators for complex scenes. In this paper, we present an optimal procedure leveraging deep neural networks and convex optimization. The proposed framework, called the Consensus Neural Network (CsNet), introduces three new concepts in image denoising: (1) A deep neural network to estimate the mean squared error (MSE) of denoised images without needing the ground truths; (2) A provably optimal procedure to combine the denoised outputs via convex optimization; (3) An image boosting procedure using a deep neural network to improve contrast and to recover lost details of the combined images. Experimental results show that CsNet can consistently improve denoising performance for both deterministic and neural network denoisers.
DFacTo: Distributed Factorization of Tensors
Jun 17, 2014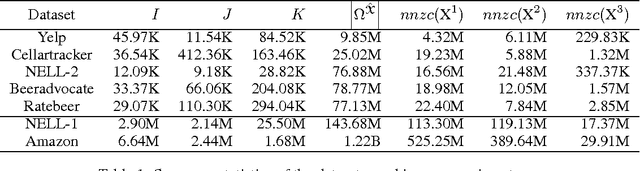
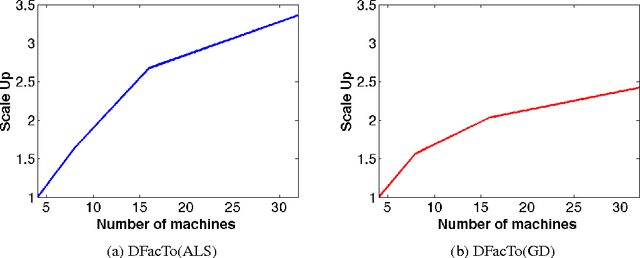


We present a technique for significantly speeding up Alternating Least Squares (ALS) and Gradient Descent (GD), two widely used algorithms for tensor factorization. By exploiting properties of the Khatri-Rao product, we show how to efficiently address a computationally challenging sub-step of both algorithms. Our algorithm, DFacTo, only requires two sparse matrix-vector products and is easy to parallelize. DFacTo is not only scalable but also on average 4 to 10 times faster than competing algorithms on a variety of datasets. For instance, DFacTo only takes 480 seconds on 4 machines to perform one iteration of the ALS algorithm and 1,143 seconds to perform one iteration of the GD algorithm on a 6.5 million x 2.5 million x 1.5 million dimensional tensor with 1.2 billion non-zero entries.