 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADEPT: Adaptive Dynamic Early-Exit Process for Transformers
Jan 07, 2026The inference of large language models imposes significant computational workloads, often requiring the processing of billions of parameters. Although early-exit strategies have proven effective in reducing computational demands by halting inference earlier, they apply either to only the first token in the generation phase or at the prompt level in the prefill phase. Thus, the Key-Value (KV) cache for skipped layers remains a bottleneck for subsequent token generation, limiting the benefits of early exit. We introduce ADEPT (Adaptive Dynamic Early-exit Process for Transformers), a novel approach designed to overcome this issue and enable dynamic early exit in both the prefill and generation phases. The proposed adaptive token-level early-exit mechanism adjusts computation dynamically based on token complexity, optimizing efficiency without compromising performance. ADEPT further enhances KV generation procedure by decoupling sequential dependencies in skipped layers, making token-level early exit more practical. Experimental results demonstrate that ADEPT improves efficiency by up to 25% in language generation tasks and achieves a 4x speed-up in downstream classification tasks, with up to a 45% improvement in performance.
COPAL: Continual Pruning in Large Language Generative Models
May 02, 2024Adapting pre-trained large language models to different domains in natural language processing requires two key considerations: high computational demands and model's inability to continual adaptation. To simultaneously address both issues, this paper presents COPAL (COntinual Pruning in Adaptive Language settings), an algorithm developed for pruning large language generative models under a continual model adaptation setting. While avoiding resource-heavy finetuning or retraining, our pruning process is guided by the proposed sensitivity analysis. The sensitivity effectively measures model's ability to withstand perturbations introduced by the new dataset and finds model's weights that are relevant for all encountered datasets. As a result, COPAL allows seamless model adaptation to new domains while enhancing the resource efficiency. Our empirical evaluation on a various size of LLMs show that COPAL outperforms baseline models, demonstrating its efficacy in efficiency and adaptability.
CLR-GAM: Contrastive Point Cloud Learning with Guided Augmentation and Feature Mapping
Feb 28, 2023

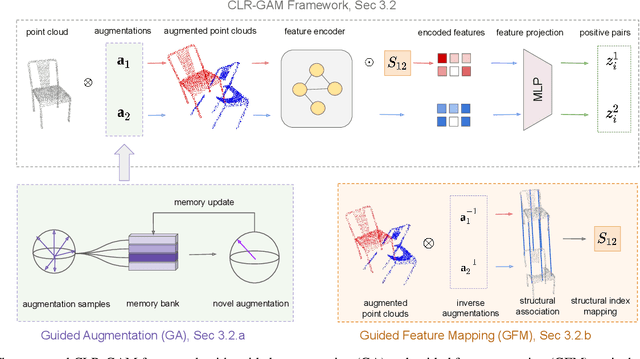

Point cloud data plays an essential role in robotics and self-driving applications. Yet, annotating point cloud data is time-consuming and nontrivial while they enable learning discriminative 3D representations that empower downstream tasks, such as classification and segmentation. Recently, contrastive learning-based frameworks have shown promising results for learning 3D representations in a self-supervised manner. However, existing contrastive learning methods cannot precisely encode and associate structural features and search the higher dimensional augmentation space efficiently. In this paper, we present CLR-GAM, a novel contrastive learning-based framework with Guided Augmentation (GA) for efficient dynamic exploration strategy and Guided Feature Mapping (GFM) for similar structural feature association between augmented point clouds. We empirically demonstrate that the proposed approach achieves state-of-the-art performance on both simulated and real-world 3D point cloud datasets for three different downstream tasks, i.e., 3D point cloud classification, few-shot learning, and object part segmentation.
DRAMA: Joint Risk Localization and Captioning in Driving
Oct 05, 2022
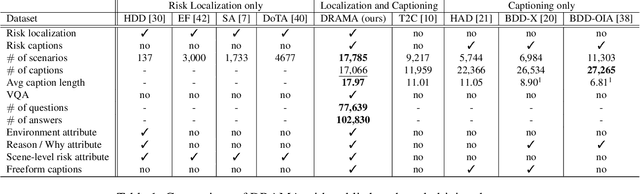

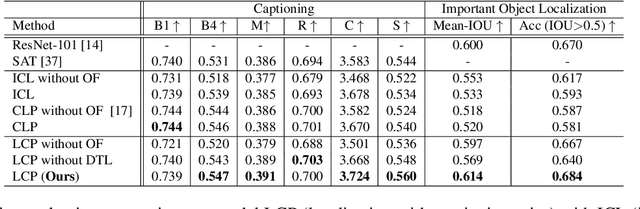
Considering the functionality of situational awareness in safety-critical automation systems, the perception of risk in driving scenes and its explainability is of particular importance for autonomous and cooperative driving. Toward this goal, this paper proposes a new research direction of joint risk localization in driving scenes and its risk explanation as a natural language description. Due to the lack of standard benchmarks, we collected a large-scale dataset, DRAMA (Driving Risk Assessment Mechanism with A captioning module), which consists of 17,785 interactive driving scenarios collected in Tokyo, Japan. Our DRAMA dataset accommodates video- and object-level questions on driving risks with associated important objects to achieve the goal of visual captioning as a free-form language description utilizing closed and open-ended responses for multi-level questions, which can be used to evaluate a range of visual captioning capabilities in driving scenarios. We make this data available to the community for further research. Using DRAMA, we explore multiple facets of joint risk localization and captioning in interactive driving scenarios. In particular, we benchmark various multi-task prediction architectures and provide a detailed analysis of joint risk localization and risk captioning. The data set is available at https://usa.honda-ri.com/drama
LOKI: Long Term and Key Intentions for Trajectory Prediction
Aug 18, 2021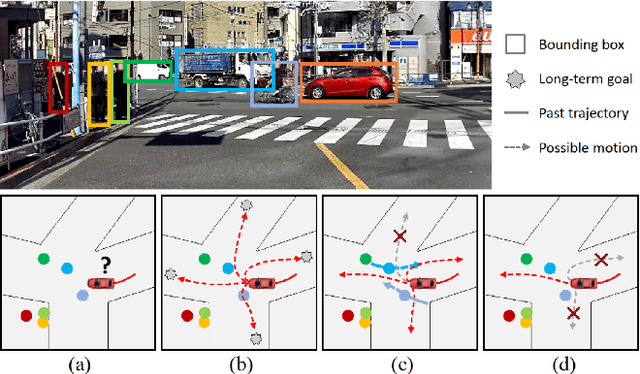
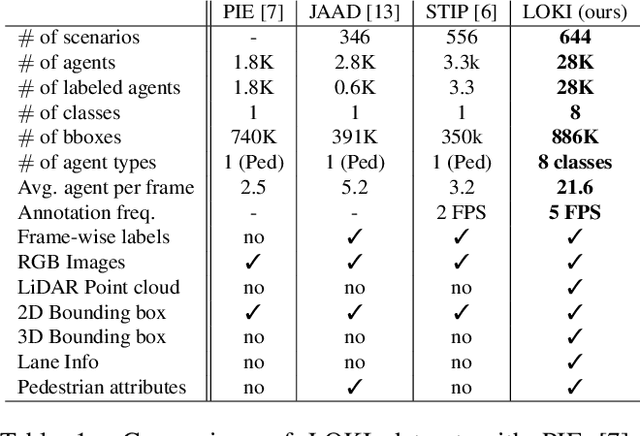
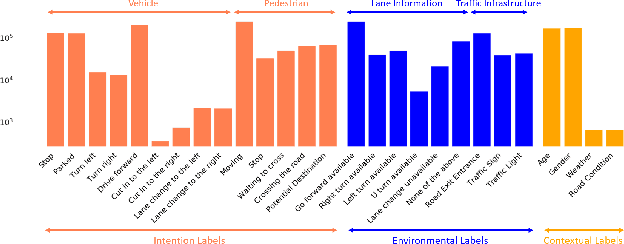

Recent advances in trajectory prediction have shown that explicit reasoning about agents' intent is important to accurately forecast their motion. However, the current research activities are not directly applicable to intelligent and safety critical systems. This is mainly because very few public datasets are available, and they only consider pedestrian-specific intents for a short temporal horizon from a restricted egocentric view. To this end, we propose LOKI (LOng term and Key Intentions), a novel large-scale dataset that is designed to tackle joint trajectory and intention prediction for heterogeneous traffic agents (pedestrians and vehicles) in an autonomous driving setting. The LOKI dataset is created to discover several factors that may affect intention, including i) agent's own will, ii) social interactions, iii) environmental constraints, and iv) contextual information. We also propose a model that jointly performs trajectory and intention prediction, showing that recurrently reasoning about intention can assist with trajectory prediction. We show our method outperforms state-of-the-art trajectory prediction methods by upto $27\%$ and also provide a baseline for frame-wise intention estimation.
RAIN: Reinforced Hybrid Attention Inference Network for Motion Forecasting
Aug 03, 2021

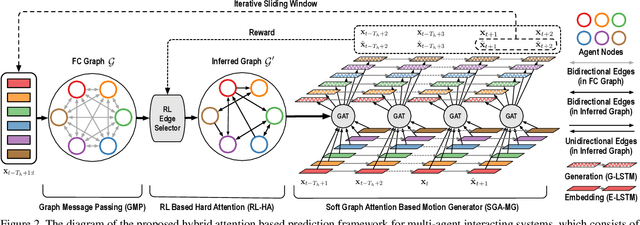
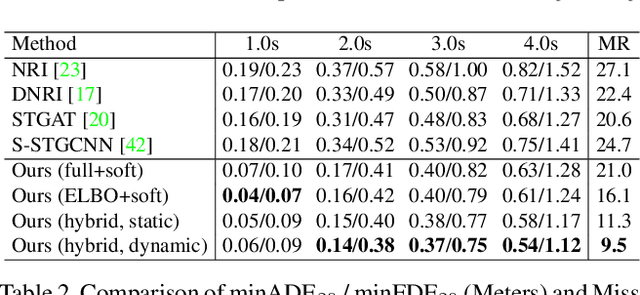
Motion forecasting plays a significant role in various domains (e.g., autonomous driving, human-robot interaction), which aims to predict future motion sequences given a set of historical observations. However, the observed elements may be of different levels of importance. Some information may be irrelevant or even distracting to the forecasting in certain situations. To address this issue, we propose a generic motion forecasting framework (named RAIN) with dynamic key information selection and ranking based on a hybrid attention mechanism. The general framework is instantiated to handle multi-agent trajectory prediction and human motion forecasting tasks, respectively. In the former task, the model learns to recognize the relations between agents with a graph representation and to determine their relative significance. In the latter task, the model learns to capture the temporal proximity and dependency in long-term human motions. We also propose an effective double-stage training pipeline with an alternating training strategy to optimize the parameters in different modules of the framework. We validate the framework on both synthetic simulations and motion forecasting benchmarks in different domains, demonstrating that our method not only achieves state-of-the-art forecasting performance, but also provides interpretable and reasonable hybrid attention weights.
Shared Cross-Modal Trajectory Prediction for Autonomous Driving
Nov 15, 2020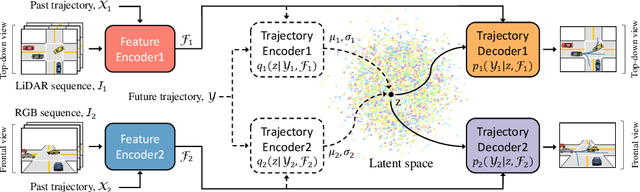
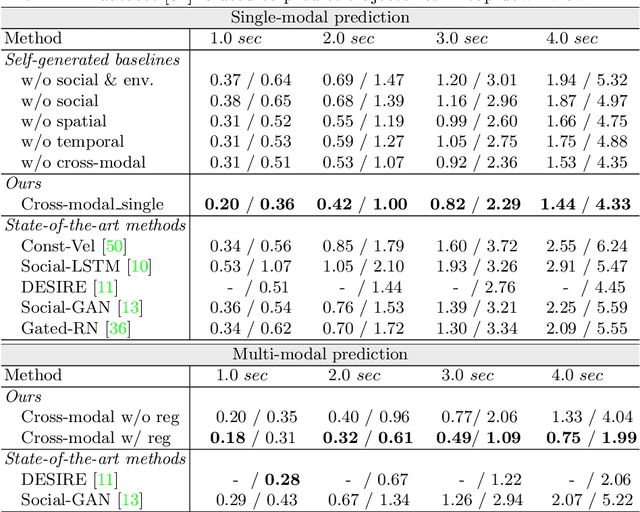
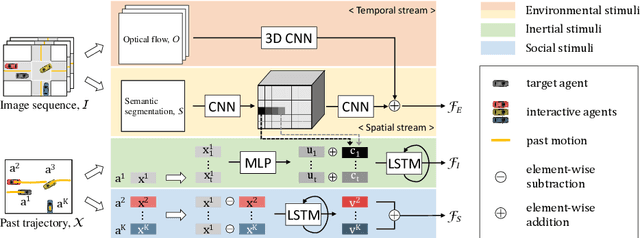
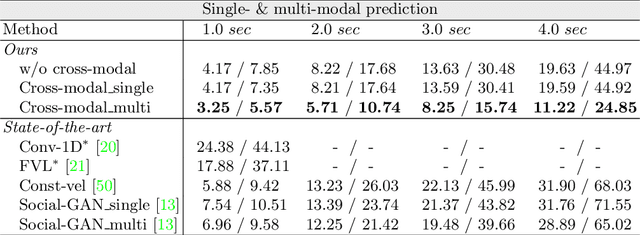
Predicting future trajectories of traffic agents in highly interactive environments is an essential and challenging problem for the safe operation of autonomous driving systems. On the basis of the fact that self-driving vehicles are equipped with various types of sensors (e.g., LiDAR scanner, RGB camera, radar, etc.), we propose a Cross-Modal Embedding framework that aims to benefit from the use of multiple input modalities. At training time, our model learns to embed a set of complementary features in a shared latent space by jointly optimizing the objective functions across different types of input data. At test time, a single input modality (e.g., LiDAR data) is required to generate predictions from the input perspective (i.e., in the LiDAR space), while taking advantages from the model trained with multiple sensor modalities. An extensive evaluation is conducted to show the efficacy of the proposed framework using two benchmark driving datasets.
Social-STAGE: Spatio-Temporal Multi-Modal Future Trajectory Forecast
Nov 10, 2020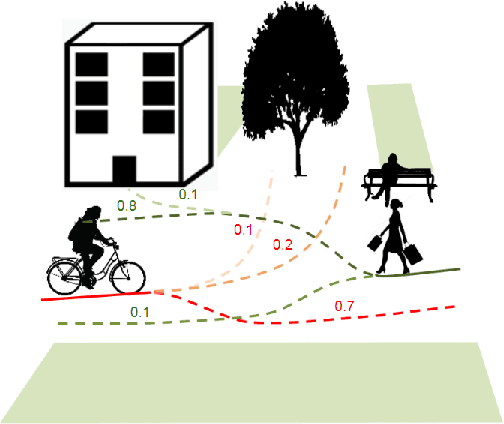
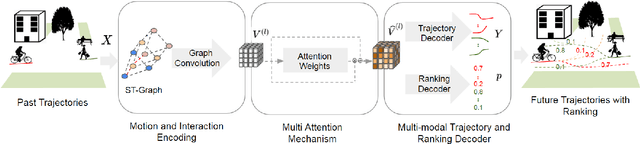
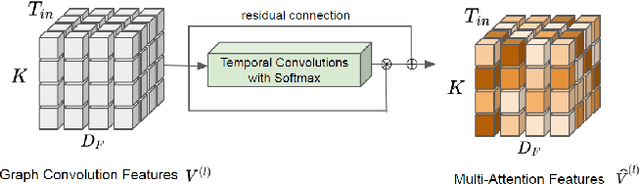
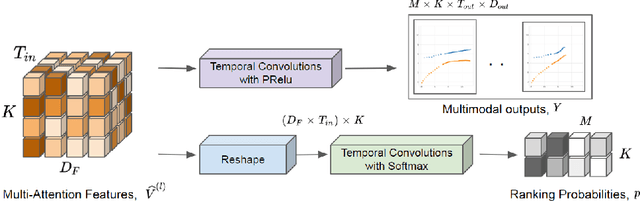
This paper considers the problem of multi-modal future trajectory forecast with ranking. Here, multi-modality and ranking refer to the multiple plausible path predictions and the confidence in those predictions, respectively. We propose Social-STAGE, Social interaction-aware Spatio-Temporal multi-Attention Graph convolution network with novel Evaluation for multi-modality. Our main contributions include analysis and formulation of multi-modality with ranking using interaction and multi-attention, and introduction of new metrics to evaluate the diversity and associated confidence of multi-modal predictions. We evaluate our approach on existing public datasets ETH and UCY and show that the proposed algorithm outperforms the state of the arts on these datasets.
SSP: Single Shot Future Trajectory Prediction
Apr 13, 2020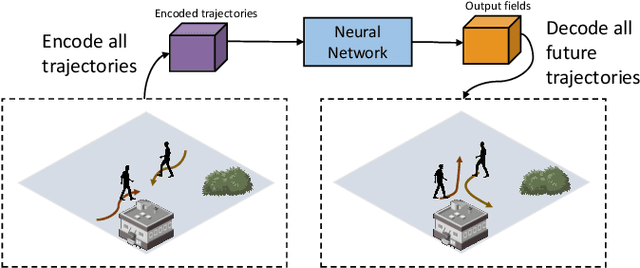
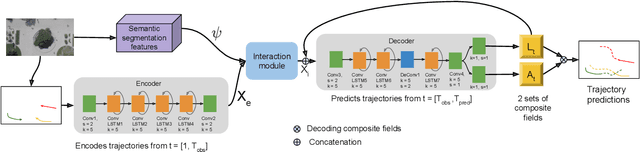
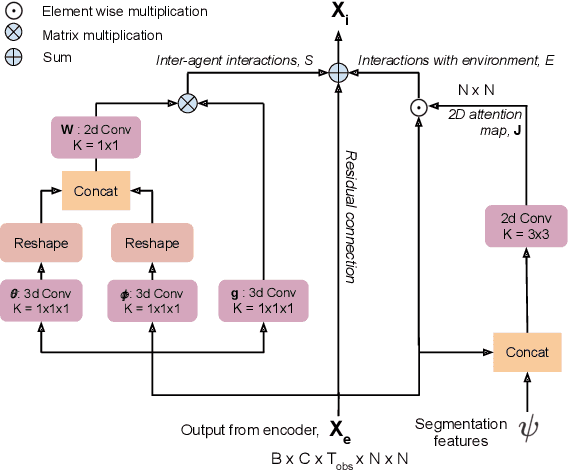
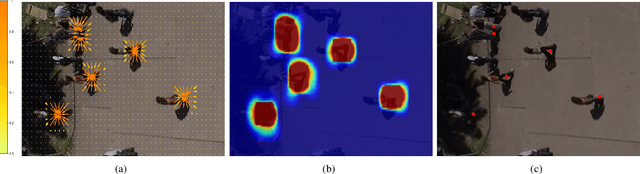
We propose a robust solution to future trajectory forecast, which can be practically applicable to autonomous agents in highly crowded environments. For this, three aspects are particularly addressed in this paper. First, we use composite fields to predict future locations of all road agents in a single-shot, which results in a constant time complexity, regardless of the number of agents in the scene. Second, interactions between agents are modeled as a non-local response, enabling spatial relationships between different locations to be captured temporally as well (i.e., in spatio-temporal interactions). Third, the semantic context of the scene are modeled and take into account the environmental constraints that potentially influence the future motion. To this end, we validate the robustness of the proposed approach using the ETH, UCY, and SDD datasets and highlight its practical functionality compared to the current state-of-the-art methods.
TITAN: Future Forecast using Action Priors
Apr 01, 2020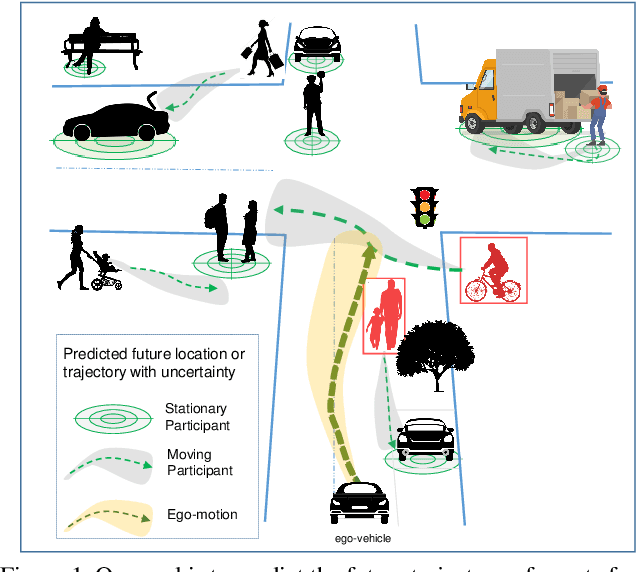
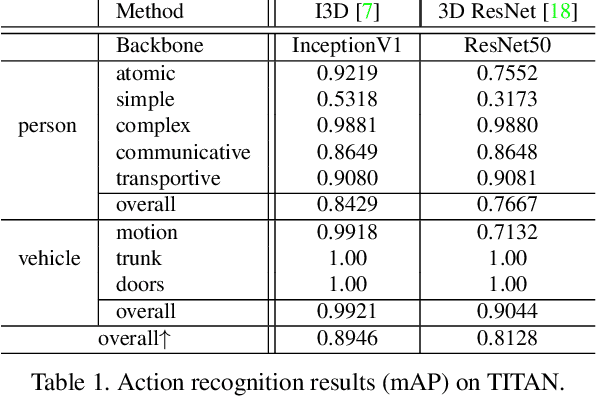
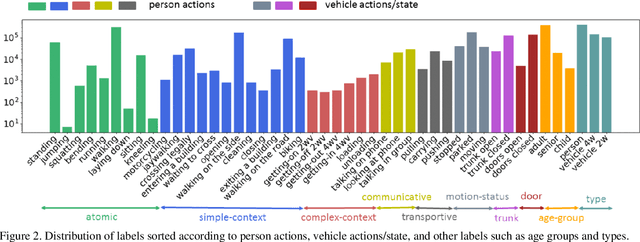
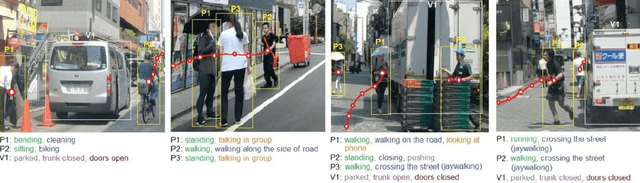
We consider the problem of predicting the future trajectory of scene agents from egocentric views obtained from a moving platform. This problem is important in a variety of domains, particularly for autonomous systems making reactive or strategic decisions in navigation. In an attempt to address this problem, we introduce TITAN (Trajectory Inference using Targeted Action priors Network), a new model that incorporates prior positions, actions, and context to forecast future trajectory of agents and future ego-motion. In the absence of an appropriate dataset for this task, we created the TITAN dataset that consists of 700 labeled video-clips (with odometry) captured from a moving vehicle on highly interactive urban traffic scenes in Tokyo. Our dataset includes 50 labels including vehicle states and actions, pedestrian age groups, and targeted pedestrian action attributes that are organized hierarchically corresponding to atomic, simple/complex-contextual, transportive, and communicative actions. To evaluate our model, we conducted extensive experiments on the TITAN dataset, revealing significant performance improvement against baselines and state-of-the-art algorithms. We also report promising results from our Agent Importance Mechanism (AIM), a module which provides insight into assessment of perceived risk by calculating the relative influence of each agent on the future ego-trajectory. The dataset is available at https://usa.honda-ri.com/titan