 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHetroD: A High-Fidelity Drone Dataset and Benchmark for Autonomous Driving in Heterogeneous Traffic
Feb 03, 2026We present HetroD, a dataset and benchmark for developing autonomous driving systems in heterogeneous environments. HetroD targets the critical challenge of navi- gating real-world heterogeneous traffic dominated by vulner- able road users (VRUs), including pedestrians, cyclists, and motorcyclists that interact with vehicles. These mixed agent types exhibit complex behaviors such as hook turns, lane splitting, and informal right-of-way negotiation. Such behaviors pose significant challenges for autonomous vehicles but remain underrepresented in existing datasets focused on structured, lane-disciplined traffic. To bridge the gap, we collect a large- scale drone-based dataset to provide a holistic observation of traffic scenes with centimeter-accurate annotations, HD maps, and traffic signal states. We further develop a modular toolkit for extracting per-agent scenarios to support downstream task development. In total, the dataset comprises over 65.4k high- fidelity agent trajectories, 70% of which are from VRUs. HetroD supports modeling of VRU behaviors in dense, het- erogeneous traffic and provides standardized benchmarks for forecasting, planning, and simulation tasks. Evaluation results reveal that state-of-the-art prediction and planning models struggle with the challenges presented by our dataset: they fail to predict lateral VRU movements, cannot handle unstructured maneuvers, and exhibit limited performance in dense and multi-agent scenarios, highlighting the need for more robust approaches to heterogeneous traffic. See our project page for more examples: https://hetroddata.github.io/HetroD/
Affordance-Guided Coarse-to-Fine Exploration for Base Placement in Open-Vocabulary Mobile Manipulation
Nov 09, 2025



In open-vocabulary mobile manipulation (OVMM), task success often hinges on the selection of an appropriate base placement for the robot. Existing approaches typically navigate to proximity-based regions without considering affordances, resulting in frequent manipulation failures. We propose Affordance-Guided Coarse-to-Fine Exploration, a zero-shot framework for base placement that integrates semantic understanding from vision-language models (VLMs) with geometric feasibility through an iterative optimization process. Our method constructs cross-modal representations, namely Affordance RGB and Obstacle Map+, to align semantics with spatial context. This enables reasoning that extends beyond the egocentric limitations of RGB perception. To ensure interaction is guided by task-relevant affordances, we leverage coarse semantic priors from VLMs to guide the search toward task-relevant regions and refine placements with geometric constraints, thereby reducing the risk of convergence to local optima. Evaluated on five diverse open-vocabulary mobile manipulation tasks, our system achieves an 85% success rate, significantly outperforming classical geometric planners and VLM-based methods. This demonstrates the promise of affordance-aware and multimodal reasoning for generalizable, instruction-conditioned planning in OVMM.
GRITS: A Spillage-Aware Guided Diffusion Policy for Robot Food Scooping Tasks
Oct 01, 2025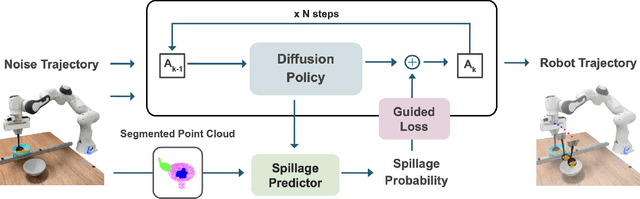
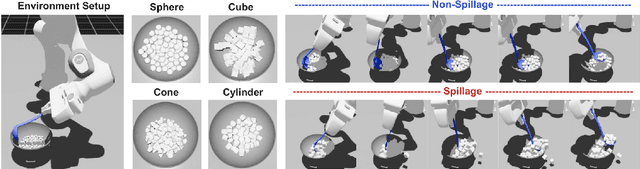


Robotic food scooping is a critical manipulation skill for food preparation and service robots. However, existing robot learning algorithms, especially learn-from-demonstration methods, still struggle to handle diverse and dynamic food states, which often results in spillage and reduced reliability. In this work, we introduce GRITS: A Spillage-Aware Guided Diffusion Policy for Robot Food Scooping Tasks. This framework leverages guided diffusion policy to minimize food spillage during scooping and to ensure reliable transfer of food items from the initial to the target location. Specifically, we design a spillage predictor that estimates the probability of spillage given current observation and action rollout. The predictor is trained on a simulated dataset with food spillage scenarios, constructed from four primitive shapes (spheres, cubes, cones, and cylinders) with varied physical properties such as mass, friction, and particle size. At inference time, the predictor serves as a differentiable guidance signal, steering the diffusion sampling process toward safer trajectories while preserving task success. We validate GRITS on a real-world robotic food scooping platform. GRITS is trained on six food categories and evaluated on ten unseen categories with different shapes and quantities. GRITS achieves an 82% task success rate and a 4% spillage rate, reducing spillage by over 40% compared to baselines without guidance, thereby demonstrating its effectiveness.
Bridging Diffusion Models and 3D Representations: A 3D Consistent Super-Resolution Framework
Aug 06, 2025We propose 3D Super Resolution (3DSR), a novel 3D Gaussian-splatting-based super-resolution framework that leverages off-the-shelf diffusion-based 2D super-resolution models. 3DSR encourages 3D consistency across views via the use of an explicit 3D Gaussian-splatting-based scene representation. This makes the proposed 3DSR different from prior work, such as image upsampling or the use of video super-resolution, which either don't consider 3D consistency or aim to incorporate 3D consistency implicitly. Notably, our method enhances visual quality without additional fine-tuning, ensuring spatial coherence within the reconstructed scene. We evaluate 3DSR on MipNeRF360 and LLFF data, demonstrating that it produces high-resolution results that are visually compelling, while maintaining structural consistency in 3D reconstructions. Code will be released.
RC-AutoCalib: An End-to-End Radar-Camera Automatic Calibration Network
May 28, 2025This paper presents a groundbreaking approach - the first online automatic geometric calibration method for radar and camera systems. Given the significant data sparsity and measurement uncertainty in radar height data, achieving automatic calibration during system operation has long been a challenge. To address the sparsity issue, we propose a Dual-Perspective representation that gathers features from both frontal and bird's-eye views. The frontal view contains rich but sensitive height information, whereas the bird's-eye view provides robust features against height uncertainty. We thereby propose a novel Selective Fusion Mechanism to identify and fuse reliable features from both perspectives, reducing the effect of height uncertainty. Moreover, for each view, we incorporate a Multi-Modal Cross-Attention Mechanism to explicitly find location correspondences through cross-modal matching. During the training phase, we also design a Noise-Resistant Matcher to provide better supervision and enhance the robustness of the matching mechanism against sparsity and height uncertainty. Our experimental results, tested on the nuScenes dataset, demonstrate that our method significantly outperforms previous radar-camera auto-calibration methods, as well as existing state-of-the-art LiDAR-camera calibration techniques, establishing a new benchmark for future research. The code is available at https://github.com/nycu-acm/RC-AutoCalib.
Toward Real-world BEV Perception: Depth Uncertainty Estimation via Gaussian Splatting
Apr 03, 2025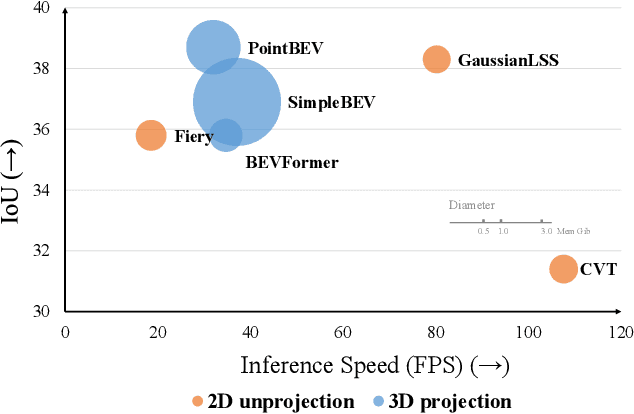



Bird's-eye view (BEV) perception has gained significant attention because it provides a unified representation to fuse multiple view images and enables a wide range of down-stream autonomous driving tasks, such as forecasting and planning. Recent state-of-the-art models utilize projection-based methods which formulate BEV perception as query learning to bypass explicit depth estimation. While we observe promising advancements in this paradigm, they still fall short of real-world applications because of the lack of uncertainty modeling and expensive computational requirement. In this work, we introduce GaussianLSS, a novel uncertainty-aware BEV perception framework that revisits unprojection-based methods, specifically the Lift-Splat-Shoot (LSS) paradigm, and enhances them with depth un-certainty modeling. GaussianLSS represents spatial dispersion by learning a soft depth mean and computing the variance of the depth distribution, which implicitly captures object extents. We then transform the depth distribution into 3D Gaussians and rasterize them to construct uncertainty-aware BEV features. We evaluate GaussianLSS on the nuScenes dataset, achieving state-of-the-art performance compared to unprojection-based methods. In particular, it provides significant advantages in speed, running 2.5x faster, and in memory efficiency, using 0.3x less memory compared to projection-based methods, while achieving competitive performance with only a 0.4% IoU difference.
What Changed and What Could Have Changed? State-Change Counterfactuals for Procedure-Aware Video Representation Learning
Mar 27, 2025



Understanding a procedural activity requires modeling both how action steps transform the scene, and how evolving scene transformations can influence the sequence of action steps, even those that are accidental or erroneous. Existing work has studied procedure-aware video representations by proposing novel approaches such as modeling the temporal order of actions and has not explicitly learned the state changes (scene transformations). In this work, we study procedure-aware video representation learning by incorporating state-change descriptions generated by Large Language Models (LLMs) as supervision signals for video encoders. Moreover, we generate state-change counterfactuals that simulate hypothesized failure outcomes, allowing models to learn by imagining the unseen ``What if'' scenarios. This counterfactual reasoning facilitates the model's ability to understand the cause and effect of each step in an activity. To verify the procedure awareness of our model, we conduct extensive experiments on procedure-aware tasks, including temporal action segmentation and error detection. Our results demonstrate the effectiveness of the proposed state-change descriptions and their counterfactuals and achieve significant improvements on multiple tasks. We will make our source code and data publicly available soon.
ATARS: An Aerial Traffic Atomic Activity Recognition and Temporal Segmentation Dataset
Mar 24, 2025Traffic Atomic Activity which describes traffic patterns for topological intersection dynamics is a crucial topic for the advancement of intelligent driving systems. However, existing atomic activity datasets are collected from an egocentric view, which cannot support the scenarios where traffic activities in an entire intersection are required. Moreover, existing datasets only provide video-level atomic activity annotations, which require exhausting efforts to manually trim the videos for recognition and limit their applications to untrimmed videos. To bridge this gap, we introduce the Aerial Traffic Atomic Activity Recognition and Segmentation (ATARS) dataset, the first aerial dataset designed for multi-label atomic activity analysis. We offer atomic activity labels for each frame, which accurately record the intervals for traffic activities. Moreover, we propose a novel task, Multi-label Temporal Atomic Activity Recognition, enabling the study of accurate temporal localization for atomic activity and easing the burden of manual video trimming for recognition. We conduct extensive experiments to evaluate existing state-of-the-art models on both atomic activity recognition and temporal atomic activity segmentation. The results highlight the unique challenges of our ATARS dataset, such as recognizing extremely small objects' activities. We further provide comprehensive discussion analyzing these challenges and offer valuable insights for future direction to improve recognizing atomic activity in aerial view. Our source code and dataset are available at https://github.com/magecliff96/ATARS/
Mitigating Cross-Modal Distraction and Ensuring Geometric Feasibility via Affordance-Guided, Self-Consistent MLLMs for Food Preparation Task Planning
Mar 17, 2025We study Multimodal Large Language Models (MLLMs) with in-context learning for food preparation task planning. In this context, we identify two key challenges: cross-modal distraction and geometric feasibility. Cross-modal distraction occurs when the inclusion of visual input degrades the reasoning performance of a MLLM. Geometric feasibility refers to the ability of MLLMs to ensure that the selected skills are physically executable in the environment. To address these issues, we adapt Chain of Thought (CoT) with Self-Consistency to mitigate reasoning loss from cross-modal distractions and use affordance predictor as skill preconditions to guide MLLM on geometric feasibility. We construct a dataset to evaluate the ability of MLLMs on quantity estimation, reachability analysis, relative positioning and collision avoidance. We conducted a detailed evaluation to identify issues among different baselines and analyze the reasons for improvement, providing insights into each approach. Our method reaches a success rate of 76.7% on the entire dataset, showing a substantial improvement over the CoT baseline at 36.7%.
ArticuBot: Learning Universal Articulated Object Manipulation Policy via Large Scale Simulation
Mar 04, 2025This paper presents ArticuBot, in which a single learned policy enables a robotics system to open diverse categories of unseen articulated objects in the real world. This task has long been challenging for robotics due to the large variations in the geometry, size, and articulation types of such objects. Our system, Articubot, consists of three parts: generating a large number of demonstrations in physics-based simulation, distilling all generated demonstrations into a point cloud-based neural policy via imitation learning, and performing zero-shot sim2real transfer to real robotics systems. Utilizing sampling-based grasping and motion planning, our demonstration generalization pipeline is fast and effective, generating a total of 42.3k demonstrations over 322 training articulated objects. For policy learning, we propose a novel hierarchical policy representation, in which the high-level policy learns the sub-goal for the end-effector, and the low-level policy learns how to move the end-effector conditioned on the predicted goal. We demonstrate that this hierarchical approach achieves much better object-level generalization compared to the non-hierarchical version. We further propose a novel weighted displacement model for the high-level policy that grounds the prediction into the existing 3D structure of the scene, outperforming alternative policy representations. We show that our learned policy can zero-shot transfer to three different real robot settings: a fixed table-top Franka arm across two different labs, and an X-Arm on a mobile base, opening multiple unseen articulated objects across two labs, real lounges, and kitchens. Videos and code can be found on our project website: https://articubot.github.io/.