 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRITS: A Spillage-Aware Guided Diffusion Policy for Robot Food Scooping Tasks
Oct 01, 2025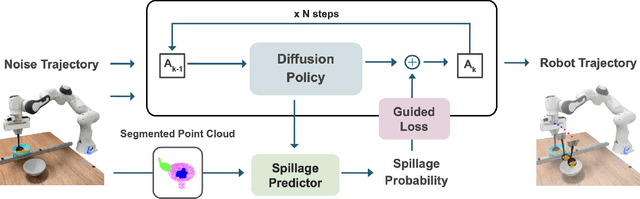
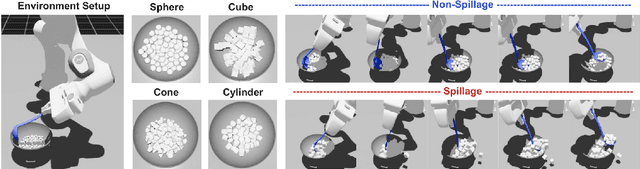


Robotic food scooping is a critical manipulation skill for food preparation and service robots. However, existing robot learning algorithms, especially learn-from-demonstration methods, still struggle to handle diverse and dynamic food states, which often results in spillage and reduced reliability. In this work, we introduce GRITS: A Spillage-Aware Guided Diffusion Policy for Robot Food Scooping Tasks. This framework leverages guided diffusion policy to minimize food spillage during scooping and to ensure reliable transfer of food items from the initial to the target location. Specifically, we design a spillage predictor that estimates the probability of spillage given current observation and action rollout. The predictor is trained on a simulated dataset with food spillage scenarios, constructed from four primitive shapes (spheres, cubes, cones, and cylinders) with varied physical properties such as mass, friction, and particle size. At inference time, the predictor serves as a differentiable guidance signal, steering the diffusion sampling process toward safer trajectories while preserving task success. We validate GRITS on a real-world robotic food scooping platform. GRITS is trained on six food categories and evaluated on ten unseen categories with different shapes and quantities. GRITS achieves an 82% task success rate and a 4% spillage rate, reducing spillage by over 40% compared to baselines without guidance, thereby demonstrating its effectiveness.
Mitigating Cross-Modal Distraction and Ensuring Geometric Feasibility via Affordance-Guided, Self-Consistent MLLMs for Food Preparation Task Planning
Mar 17, 2025We study Multimodal Large Language Models (MLLMs) with in-context learning for food preparation task planning. In this context, we identify two key challenges: cross-modal distraction and geometric feasibility. Cross-modal distraction occurs when the inclusion of visual input degrades the reasoning performance of a MLLM. Geometric feasibility refers to the ability of MLLMs to ensure that the selected skills are physically executable in the environment. To address these issues, we adapt Chain of Thought (CoT) with Self-Consistency to mitigate reasoning loss from cross-modal distractions and use affordance predictor as skill preconditions to guide MLLM on geometric feasibility. We construct a dataset to evaluate the ability of MLLMs on quantity estimation, reachability analysis, relative positioning and collision avoidance. We conducted a detailed evaluation to identify issues among different baselines and analyze the reasons for improvement, providing insights into each approach. Our method reaches a success rate of 76.7% on the entire dataset, showing a substantial improvement over the CoT baseline at 36.7%.