 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Changed and What Could Have Changed? State-Change Counterfactuals for Procedure-Aware Video Representation Learning
Mar 27, 2025



Understanding a procedural activity requires modeling both how action steps transform the scene, and how evolving scene transformations can influence the sequence of action steps, even those that are accidental or erroneous. Existing work has studied procedure-aware video representations by proposing novel approaches such as modeling the temporal order of actions and has not explicitly learned the state changes (scene transformations). In this work, we study procedure-aware video representation learning by incorporating state-change descriptions generated by Large Language Models (LLMs) as supervision signals for video encoders. Moreover, we generate state-change counterfactuals that simulate hypothesized failure outcomes, allowing models to learn by imagining the unseen ``What if'' scenarios. This counterfactual reasoning facilitates the model's ability to understand the cause and effect of each step in an activity. To verify the procedure awareness of our model, we conduct extensive experiments on procedure-aware tasks, including temporal action segmentation and error detection. Our results demonstrate the effectiveness of the proposed state-change descriptions and their counterfactuals and achieve significant improvements on multiple tasks. We will make our source code and data publicly available soon.
ATARS: An Aerial Traffic Atomic Activity Recognition and Temporal Segmentation Dataset
Mar 24, 2025Traffic Atomic Activity which describes traffic patterns for topological intersection dynamics is a crucial topic for the advancement of intelligent driving systems. However, existing atomic activity datasets are collected from an egocentric view, which cannot support the scenarios where traffic activities in an entire intersection are required. Moreover, existing datasets only provide video-level atomic activity annotations, which require exhausting efforts to manually trim the videos for recognition and limit their applications to untrimmed videos. To bridge this gap, we introduce the Aerial Traffic Atomic Activity Recognition and Segmentation (ATARS) dataset, the first aerial dataset designed for multi-label atomic activity analysis. We offer atomic activity labels for each frame, which accurately record the intervals for traffic activities. Moreover, we propose a novel task, Multi-label Temporal Atomic Activity Recognition, enabling the study of accurate temporal localization for atomic activity and easing the burden of manual video trimming for recognition. We conduct extensive experiments to evaluate existing state-of-the-art models on both atomic activity recognition and temporal atomic activity segmentation. The results highlight the unique challenges of our ATARS dataset, such as recognizing extremely small objects' activities. We further provide comprehensive discussion analyzing these challenges and offer valuable insights for future direction to improve recognizing atomic activity in aerial view. Our source code and dataset are available at https://github.com/magecliff96/ATARS/
RiskBench: A Scenario-based Benchmark for Risk Identification
Dec 04, 2023Intelligent driving systems aim to achieve a zero-collision mobility experience, requiring interdisciplinary efforts to enhance safety performance. This work focuses on risk identification, the process of identifying and analyzing risks stemming from dynamic traffic participants and unexpected events. While significant advances have been made in the community, the current evaluation of different risk identification algorithms uses independent datasets, leading to difficulty in direct comparison and hindering collective progress toward safety performance enhancement. To address this limitation, we introduce \textbf{RiskBench}, a large-scale scenario-based benchmark for risk identification. We design a scenario taxonomy and augmentation pipeline to enable a systematic collection of ground truth risks under diverse scenarios. We assess the ability of ten algorithms to (1) detect and locate risks, (2) anticipate risks, and (3) facilitate decision-making. We conduct extensive experiments and summarize future research on risk identification. Our aim is to encourage collaborative endeavors in achieving a society with zero collisions. We have made our dataset and benchmark toolkit publicly on the project page: https://hcis-lab.github.io/RiskBench/
Action-slot: Visual Action-centric Representations for Multi-label Atomic Activity Recognition in Traffic Scenes
Nov 29, 2023

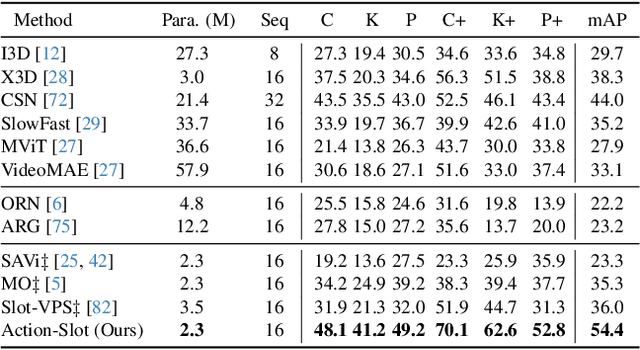

In this paper, we study multi-label atomic activity recognition. Despite the notable progress in action recognition, it is still challenging to recognize atomic activities due to a deficiency in a holistic understanding of both multiple road users' motions and their contextual information. In this paper, we introduce Action-slot, a slot attention-based approach that learns visual action-centric representations, capturing both motion and contextual information. Our key idea is to design action slots that are capable of paying attention to regions where atomic activities occur, without the need for explicit perception guidance. To further enhance slot attention, we introduce a background slot that competes with action slots, aiding the training process in avoiding unnecessary focus on background regions devoid of activities. Yet, the imbalanced class distribution in the existing dataset hampers the assessment of rare activities. To address the limitation, we collect a synthetic dataset called TACO, which is four times larger than OATS and features a balanced distribution of atomic activities. To validate the effectiveness of our method, we conduct comprehensive experiments and ablation studies against various action recognition baselines. We also show that the performance of multi-label atomic activity recognition on real-world datasets can be improved by pretraining representations on TACO. We will release our source code and dataset. See the videos of visualization on the project page: https://hcis-lab.github.io/Action-slot/