 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAME: A Lightweight Spatio-Temporal Network for Model Attribution of Face-Swap Deepfakes
Jun 13, 2025The widespread emergence of face-swap Deepfake videos poses growing risks to digital security, privacy, and media integrity, necessitating effective forensic tools for identifying the source of such manipulations. Although most prior research has focused primarily on binary Deepfake detection, the task of model attribution -- determining which generative model produced a given Deepfake -- remains underexplored. In this paper, we introduce FAME (Fake Attribution via Multilevel Embeddings), a lightweight and efficient spatio-temporal framework designed to capture subtle generative artifacts specific to different face-swap models. FAME integrates spatial and temporal attention mechanisms to improve attribution accuracy while remaining computationally efficient. We evaluate our model on three challenging and diverse datasets: Deepfake Detection and Manipulation (DFDM), FaceForensics++, and FakeAVCeleb. Results show that FAME consistently outperforms existing methods in both accuracy and runtime, highlighting its potential for deployment in real-world forensic and information security applications.
Syn3DTxt: Embedding 3D Cues for Scene Text Generation
May 24, 2025



This study aims to investigate the challenge of insufficient three-dimensional context in synthetic datasets for scene text rendering. Although recent advances in diffusion models and related techniques have improved certain aspects of scene text generation, most existing approaches continue to rely on 2D data, sourcing authentic training examples from movie posters and book covers, which limits their ability to capture the complex interactions among spatial layout and visual effects in real-world scenes. In particular, traditional 2D datasets do not provide the necessary geometric cues for accurately embedding text into diverse backgrounds. To address this limitation, we propose a novel standard for constructing synthetic datasets that incorporates surface normals to enrich three-dimensional scene characteristic. By adding surface normals to conventional 2D data, our approach aims to enhance the representation of spatial relationships and provide a more robust foundation for future scene text rendering methods. Extensive experiments demonstrate that datasets built under this new standard offer improved geometric context, facilitating further advancements in text rendering under complex 3D-spatial conditions.
ATARS: An Aerial Traffic Atomic Activity Recognition and Temporal Segmentation Dataset
Mar 24, 2025Traffic Atomic Activity which describes traffic patterns for topological intersection dynamics is a crucial topic for the advancement of intelligent driving systems. However, existing atomic activity datasets are collected from an egocentric view, which cannot support the scenarios where traffic activities in an entire intersection are required. Moreover, existing datasets only provide video-level atomic activity annotations, which require exhausting efforts to manually trim the videos for recognition and limit their applications to untrimmed videos. To bridge this gap, we introduce the Aerial Traffic Atomic Activity Recognition and Segmentation (ATARS) dataset, the first aerial dataset designed for multi-label atomic activity analysis. We offer atomic activity labels for each frame, which accurately record the intervals for traffic activities. Moreover, we propose a novel task, Multi-label Temporal Atomic Activity Recognition, enabling the study of accurate temporal localization for atomic activity and easing the burden of manual video trimming for recognition. We conduct extensive experiments to evaluate existing state-of-the-art models on both atomic activity recognition and temporal atomic activity segmentation. The results highlight the unique challenges of our ATARS dataset, such as recognizing extremely small objects' activities. We further provide comprehensive discussion analyzing these challenges and offer valuable insights for future direction to improve recognizing atomic activity in aerial view. Our source code and dataset are available at https://github.com/magecliff96/ATARS/
Computational Analysis of Yaredawi YeZema Silt in Ethiopian Orthodox Tewahedo Church Chants
Dec 25, 2024Despite its musicological, cultural, and religious significance, the Ethiopian Orthodox Tewahedo Church (EOTC) chant is relatively underrepresented in music research. Historical records, including manuscripts, research papers, and oral traditions, confirm Saint Yared's establishment of three canonical EOTC chanting modes during the 6th century. This paper attempts to investigate the EOTC chants using music information retrieval (MIR) techniques. Among the research questions regarding the analysis and understanding of EOTC chants, Yaredawi YeZema Silt, namely the mode of chanting adhering to Saint Yared's standards, is of primary importance. Therefore, we consider the task of Yaredawi YeZema Silt classification in EOTC chants by introducing a new dataset and showcasing a series of classification experiments for this task. Results show that using the distribution of stabilized pitch contours as the feature representation on a simple neural network-based classifier becomes an effective solution. The musicological implications and insights of such results are further discussed through a comparative study with the previous ethnomusicology literature on EOTC chants. By making this dataset publicly accessible, we aim to promote future exploration and analysis of EOTC chants and highlight potential directions for further research, thereby fostering a deeper understanding and preservation of this unique spiritual and cultural heritage.
* 6 pages
Zema Dataset: A Comprehensive Study of Yaredawi Zema with a Focus on Horologium Chants
Dec 25, 2024



Computational music research plays a critical role in advancing music production, distribution, and understanding across various musical styles worldwide. Despite the immense cultural and religious significance, the Ethiopian Orthodox Tewahedo Church (EOTC) chants are relatively underrepresented in computational music research. This paper contributes to this field by introducing a new dataset specifically tailored for analyzing EOTC chants, also known as Yaredawi Zema. This work provides a comprehensive overview of a 10-hour dataset, 369 instances, creation, and curation process, including rigorous quality assurance measures. Our dataset has a detailed word-level temporal boundary and reading tone annotation along with the corresponding chanting mode label of audios. Moreover, we have also identified the chanting options associated with multiple chanting notations in the manuscript by annotating them accordingly. Our goal in making this dataset available to the public 1 is to encourage more research and study of EOTC chants, including lyrics transcription, lyric-to-audio alignment, and music generation tasks. Such research work will advance knowledge and efforts to preserve this distinctive liturgical music, a priceless cultural artifact for the Ethiopian people.
* 6 pages
How Good is ChatGPT at Audiovisual Deepfake Detection: A Comparative Study of ChatGPT, AI Models and Human Perception
Nov 14, 2024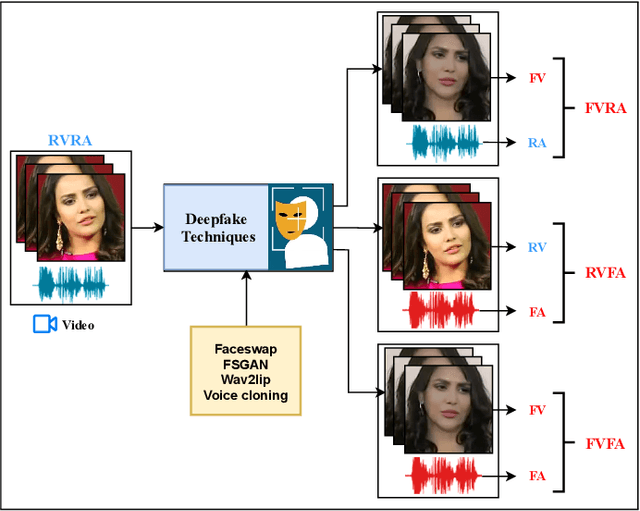
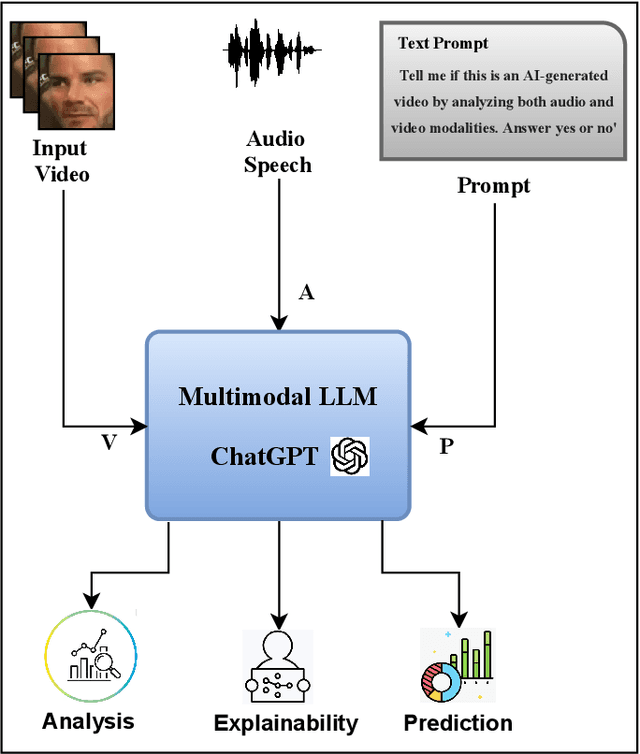
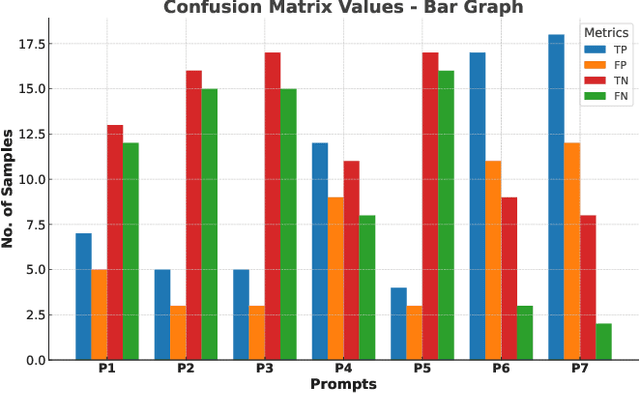

Multimodal deepfakes involving audiovisual manipulations are a growing threat because they are difficult to detect with the naked eye or using unimodal deep learningbased forgery detection methods. Audiovisual forensic models, while more capable than unimodal models, require large training datasets and are computationally expensive for training and inference. Furthermore, these models lack interpretability and often do not generalize well to unseen manipulations. In this study, we examine the detection capabilities of a large language model (LLM) (i.e., ChatGPT) to identify and account for any possible visual and auditory artifacts and manipulations in audiovisual deepfake content. Extensive experiments are conducted on videos from a benchmark multimodal deepfake dataset to evaluate the detection performance of ChatGPT and compare it with the detection capabilities of state-of-the-art multimodal forensic models and humans. Experimental results demonstrate the importance of domain knowledge and prompt engineering for video forgery detection tasks using LLMs. Unlike approaches based on end-to-end learning, ChatGPT can account for spatial and spatiotemporal artifacts and inconsistencies that may exist within or across modalities. Additionally, we discuss the limitations of ChatGPT for multimedia forensic tasks.
Domain-adaptive Video Deblurring via Test-time Blurring
Jul 12, 2024



Dynamic scene video deblurring aims to remove undesirable blurry artifacts captured during the exposure process. Although previous video deblurring methods have achieved impressive results, they suffer from significant performance drops due to the domain gap between training and testing videos, especially for those captured in real-world scenarios. To address this issue, we propose a domain adaptation scheme based on a blurring model to achieve test-time fine-tuning for deblurring models in unseen domains. Since blurred and sharp pairs are unavailable for fine-tuning during inference, our scheme can generate domain-adaptive training pairs to calibrate a deblurring model for the target domain. First, a Relative Sharpness Detection Module is proposed to identify relatively sharp regions from the blurry input images and regard them as pseudo-sharp images. Next, we utilize a blurring model to produce blurred images based on the pseudo-sharp images extracted during testing. To synthesize blurred images in compliance with the target data distribution, we propose a Domain-adaptive Blur Condition Generation Module to create domain-specific blur conditions for the blurring model. Finally, the generated pseudo-sharp and blurred pairs are used to fine-tune a deblurring model for better performance. Extensive experimental results demonstrate that our approach can significantly improve state-of-the-art video deblurring methods, providing performance gains of up to 7.54dB on various real-world video deblurring datasets. The source code is available at https://github.com/Jin-Ting-He/DADeblur.
Image Deraining via Self-supervised Reinforcement Learning
Mar 27, 2024



The quality of images captured outdoors is often affected by the weather. One factor that interferes with sight is rain, which can obstruct the view of observers and computer vision applications that rely on those images. The work aims to recover rain images by removing rain streaks via Self-supervised Reinforcement Learning (RL) for image deraining (SRL-Derain). We locate rain streak pixels from the input rain image via dictionary learning and use pixel-wise RL agents to take multiple inpainting actions to remove rain progressively. To our knowledge, this work is the first attempt where self-supervised RL is applied to image deraining. Experimental results on several benchmark image-deraining datasets show that the proposed SRL-Derain performs favorably against state-of-the-art few-shot and self-supervised deraining and denoising methods.
ViStripformer: A Token-Efficient Transformer for Versatile Video Restoration
Dec 22, 2023Video restoration is a low-level vision task that seeks to restore clean, sharp videos from quality-degraded frames. One would use the temporal information from adjacent frames to make video restoration successful. Recently, the success of the Transformer has raised awareness in the computer-vision community. However, its self-attention mechanism requires much memory, which is unsuitable for high-resolution vision tasks like video restoration. In this paper, we propose ViStripformer (Video Stripformer), which utilizes spatio-temporal strip attention to catch long-range data correlations, consisting of intra-frame strip attention (Intra-SA) and inter-frame strip attention (Inter-SA) for extracting spatial and temporal information. It decomposes video frames into strip-shaped features in horizontal and vertical directions for Intra-SA and Inter-SA to address degradation patterns with various orientations and magnitudes. Besides, ViStripformer is an effective and efficient transformer architecture with much lower memory usage than the vanilla transformer. Extensive experiments show that the proposed model achieves superior results with fast inference time on video restoration tasks, including video deblurring, demoireing, and deraining.
ID-Blau: Image Deblurring by Implicit Diffusion-based reBLurring AUgmentation
Dec 18, 2023Image deblurring aims to remove undesired blurs from an image captured in a dynamic scene. Much research has been dedicated to improving deblurring performance through model architectural designs. However, there is little work on data augmentation for image deblurring. Since continuous motion causes blurred artifacts during image exposure, we aspire to develop a groundbreaking blur augmentation method to generate diverse blurred images by simulating motion trajectories in a continuous space. This paper proposes Implicit Diffusion-based reBLurring AUgmentation (ID-Blau), utilizing a sharp image paired with a controllable blur condition map to produce a corresponding blurred image. We parameterize the blur patterns of a blurred image with their orientations and magnitudes as a pixel-wise blur condition map to simulate motion trajectories and implicitly represent them in a continuous space. By sampling diverse blur conditions, ID-Blau can generate various blurred images unseen in the training set. Experimental results demonstrate that ID-Blau can produce realistic blurred images for training and thus significantly improve performance for state-of-the-art deblurring models.