 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAVe: Self-Supervised Audio-visual Deepfake Detection Exploiting Visual Artifacts and Audio-visual Misalignment
Mar 26, 2026Multimodal deepfakes can exhibit subtle visual artifacts and cross-modal inconsistencies, which remain challenging to detect, especially when detectors are trained primarily on curated synthetic forgeries. Such synthetic dependence can introduce dataset and generator bias, limiting scalability and robustness to unseen manipulations. We propose SAVe, a self-supervised audio-visual deepfake detection framework that learns entirely on authentic videos. SAVe generates on-the-fly, identity-preserving, region-aware self-blended pseudo-manipulations to emulate tampering artifacts, enabling the model to learn complementary visual cues across multiple facial granularities. To capture cross-modal evidence, SAVe also models lip-speech synchronization via an audio-visual alignment component that detects temporal misalignment patterns characteristic of audio-visual forgeries. Experiments on FakeAVCeleb and AV-LipSync-TIMIT demonstrate competitive in-domain performance and strong cross-dataset generalization, highlighting self-supervised learning as a scalable paradigm for multimodal deepfake detection.
How Good is ChatGPT at Audiovisual Deepfake Detection: A Comparative Study of ChatGPT, AI Models and Human Perception
Nov 14, 2024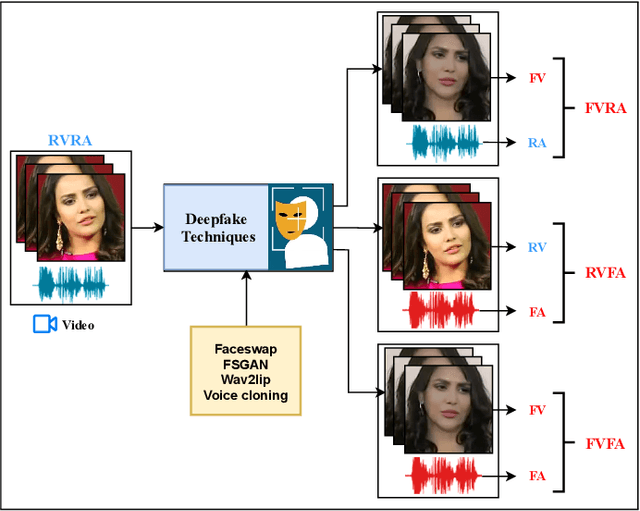
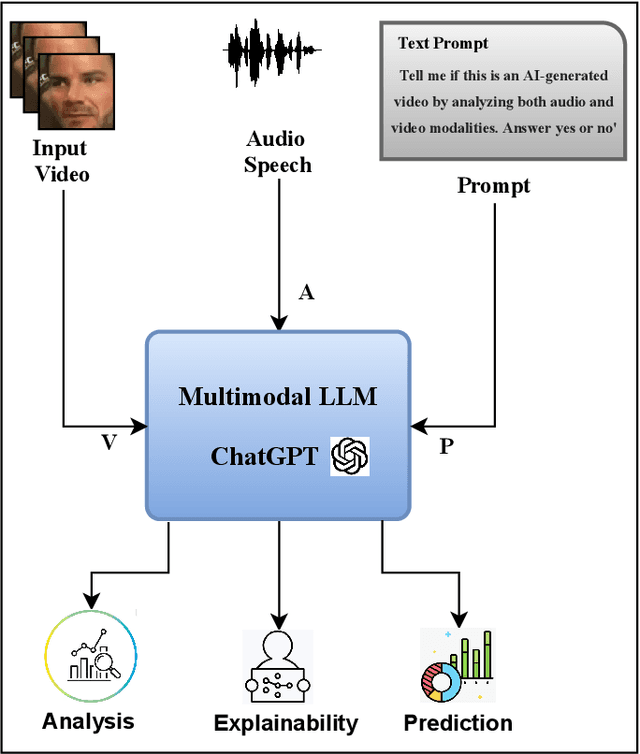
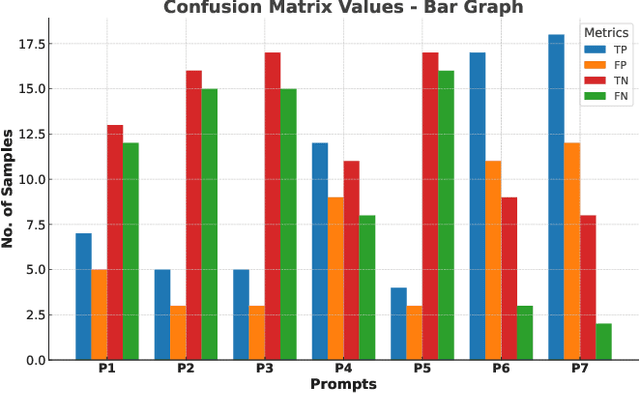

Multimodal deepfakes involving audiovisual manipulations are a growing threat because they are difficult to detect with the naked eye or using unimodal deep learningbased forgery detection methods. Audiovisual forensic models, while more capable than unimodal models, require large training datasets and are computationally expensive for training and inference. Furthermore, these models lack interpretability and often do not generalize well to unseen manipulations. In this study, we examine the detection capabilities of a large language model (LLM) (i.e., ChatGPT) to identify and account for any possible visual and auditory artifacts and manipulations in audiovisual deepfake content. Extensive experiments are conducted on videos from a benchmark multimodal deepfake dataset to evaluate the detection performance of ChatGPT and compare it with the detection capabilities of state-of-the-art multimodal forensic models and humans. Experimental results demonstrate the importance of domain knowledge and prompt engineering for video forgery detection tasks using LLMs. Unlike approaches based on end-to-end learning, ChatGPT can account for spatial and spatiotemporal artifacts and inconsistencies that may exist within or across modalities. Additionally, we discuss the limitations of ChatGPT for multimedia forensic tasks.
Understanding Audiovisual Deepfake Detection: Techniques, Challenges, Human Factors and Perceptual Insights
Nov 12, 2024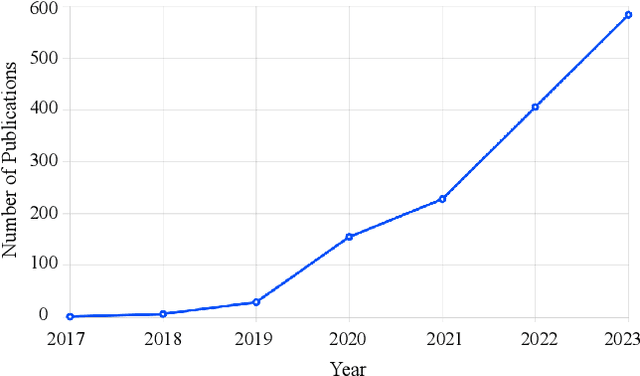

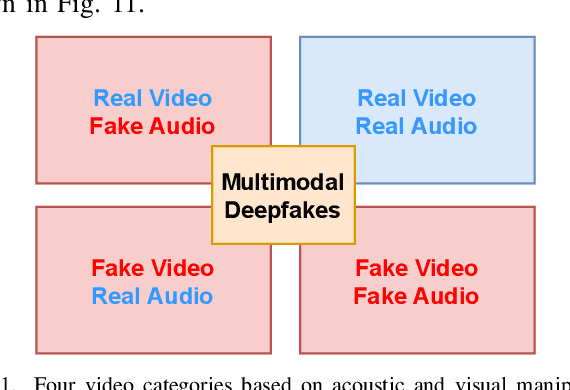
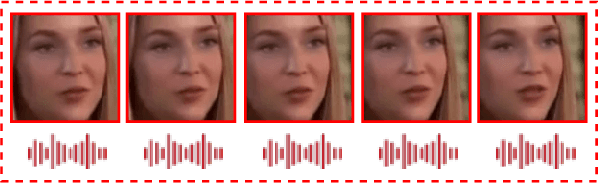
Deep Learning has been successfully applied in diverse fields, and its impact on deepfake detection is no exception. Deepfakes are fake yet realistic synthetic content that can be used deceitfully for political impersonation, phishing, slandering, or spreading misinformation. Despite extensive research on unimodal deepfake detection, identifying complex deepfakes through joint analysis of audio and visual streams remains relatively unexplored. To fill this gap, this survey first provides an overview of audiovisual deepfake generation techniques, applications, and their consequences, and then provides a comprehensive review of state-of-the-art methods that combine audio and visual modalities to enhance detection accuracy, summarizing and critically analyzing their strengths and limitations. Furthermore, we discuss existing open source datasets for a deeper understanding, which can contribute to the research community and provide necessary information to beginners who want to analyze deep learning-based audiovisual methods for video forensics. By bridging the gap between unimodal and multimodal approaches, this paper aims to improve the effectiveness of deepfake detection strategies and guide future research in cybersecurity and media integrity.
Unmasking Illusions: Understanding Human Perception of Audiovisual Deepfakes
May 07, 2024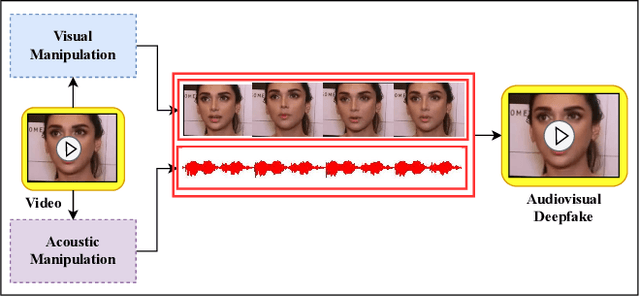
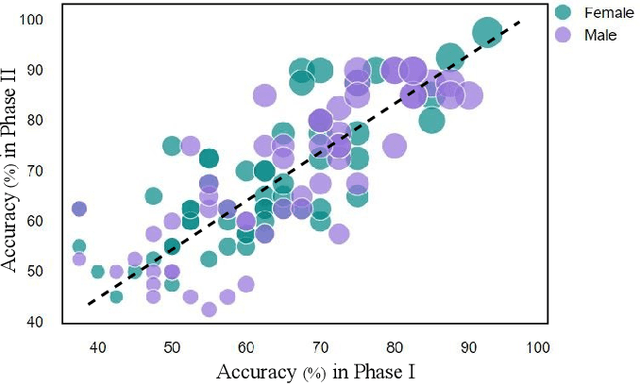
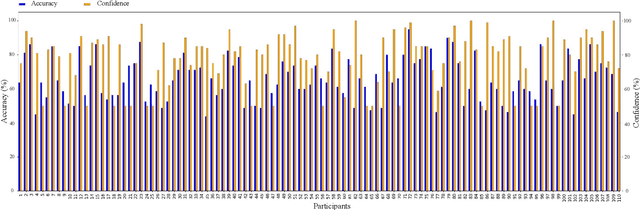
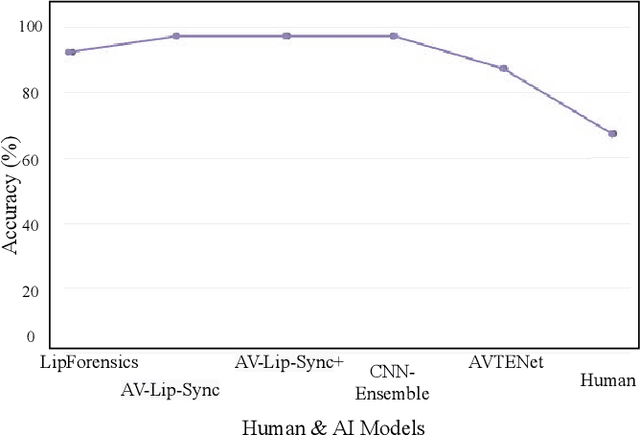
The emergence of contemporary deepfakes has attracted significant attention in machine learning research, as artificial intelligence (AI) generated synthetic media increases the incidence of misinterpretation and is difficult to distinguish from genuine content. Currently, machine learning techniques have been extensively studied for automatically detecting deepfakes. However, human perception has been less explored. Malicious deepfakes could ultimately cause public and social problems. Can we humans correctly perceive the authenticity of the content of the videos we watch? The answer is obviously uncertain; therefore, this paper aims to evaluate the human ability to discern deepfake videos through a subjective study. We present our findings by comparing human observers to five state-ofthe-art audiovisual deepfake detection models. To this end, we used gamification concepts to provide 110 participants (55 native English speakers and 55 non-native English speakers) with a webbased platform where they could access a series of 40 videos (20 real and 20 fake) to determine their authenticity. Each participant performed the experiment twice with the same 40 videos in different random orders. The videos are manually selected from the FakeAVCeleb dataset. We found that all AI models performed better than humans when evaluated on the same 40 videos. The study also reveals that while deception is not impossible, humans tend to overestimate their detection capabilities. Our experimental results may help benchmark human versus machine performance, advance forensics analysis, and enable adaptive countermeasures.
CapST: An Enhanced and Lightweight Method for Deepfake Video Classification
Nov 07, 2023The proliferation of deepfake videos, synthetic media produced through advanced Artificial Intelligence techniques has raised significant concerns across various sectors, encompassing realms such as politics, entertainment, and security. In response, this research introduces an innovative and streamlined model designed to classify deepfake videos generated by five distinct encoders adeptly. Our approach not only achieves state of the art performance but also optimizes computational resources. At its core, our solution employs part of a VGG19bn as a backbone to efficiently extract features, a strategy proven effective in image-related tasks. We integrate a Capsule Network coupled with a Spatial Temporal attention mechanism to bolster the model's classification capabilities while conserving resources. This combination captures intricate hierarchies among features, facilitating robust identification of deepfake attributes. Delving into the intricacies of our innovation, we introduce an existing video level fusion technique that artfully capitalizes on temporal attention mechanisms. This mechanism serves to handle concatenated feature vectors, capitalizing on the intrinsic temporal dependencies embedded within deepfake videos. By aggregating insights across frames, our model gains a holistic comprehension of video content, resulting in more precise predictions. Experimental results on an extensive benchmark dataset of deepfake videos called DFDM showcase the efficacy of our proposed method. Notably, our approach achieves up to a 4 percent improvement in accurately categorizing deepfake videos compared to baseline models, all while demanding fewer computational resources.
AV-Lip-Sync+: Leveraging AV-HuBERT to Exploit Multimodal Inconsistency for Video Deepfake Detection
Nov 05, 2023



Multimodal manipulations (also known as audio-visual deepfakes) make it difficult for unimodal deepfake detectors to detect forgeries in multimedia content. To avoid the spread of false propaganda and fake news, timely detection is crucial. The damage to either modality (i.e., visual or audio) can only be discovered through multi-modal models that can exploit both pieces of information simultaneously. Previous methods mainly adopt uni-modal video forensics and use supervised pre-training for forgery detection. This study proposes a new method based on a multi-modal self-supervised-learning (SSL) feature extractor to exploit inconsistency between audio and visual modalities for multi-modal video forgery detection. We use the transformer-based SSL pre-trained Audio-Visual HuBERT (AV-HuBERT) model as a visual and acoustic feature extractor and a multi-scale temporal convolutional neural network to capture the temporal correlation between the audio and visual modalities. Since AV-HuBERT only extracts visual features from the lip region, we also adopt another transformer-based video model to exploit facial features and capture spatial and temporal artifacts caused during the deepfake generation process. Experimental results show that our model outperforms all existing models and achieves new state-of-the-art performance on the FakeAVCeleb and DeepfakeTIMIT datasets.
AVTENet: Audio-Visual Transformer-based Ensemble Network Exploiting Multiple Experts for Video Deepfake Detection
Oct 19, 2023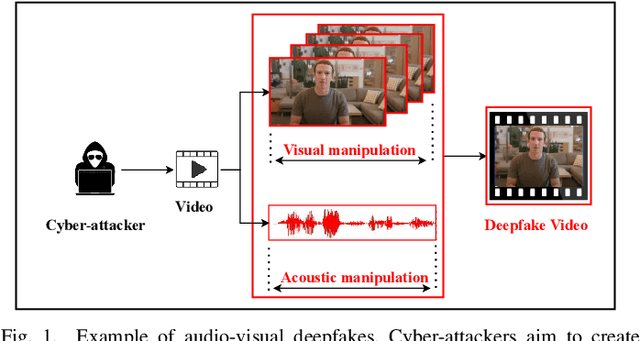
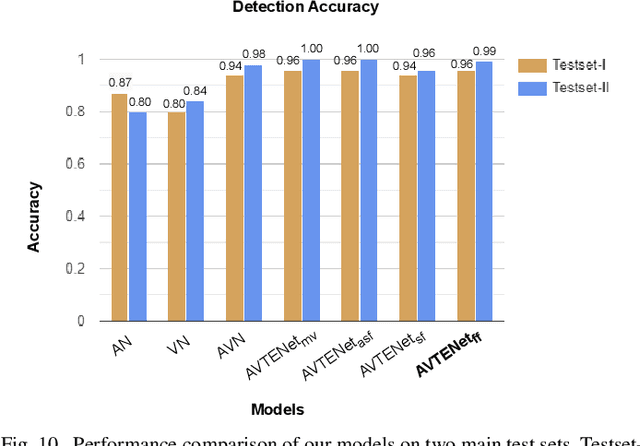
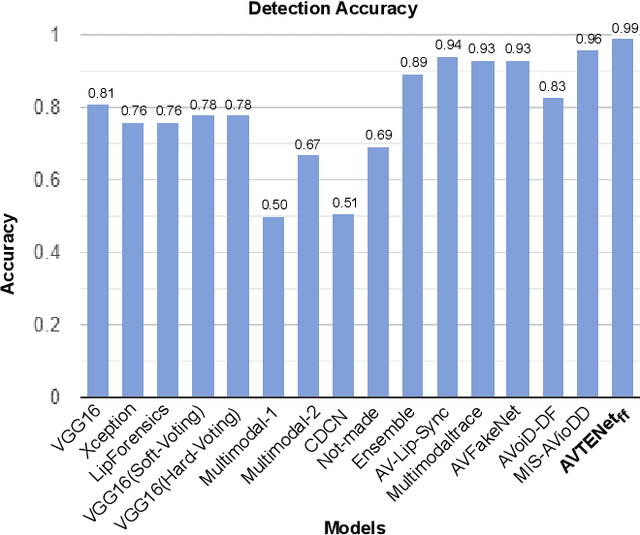
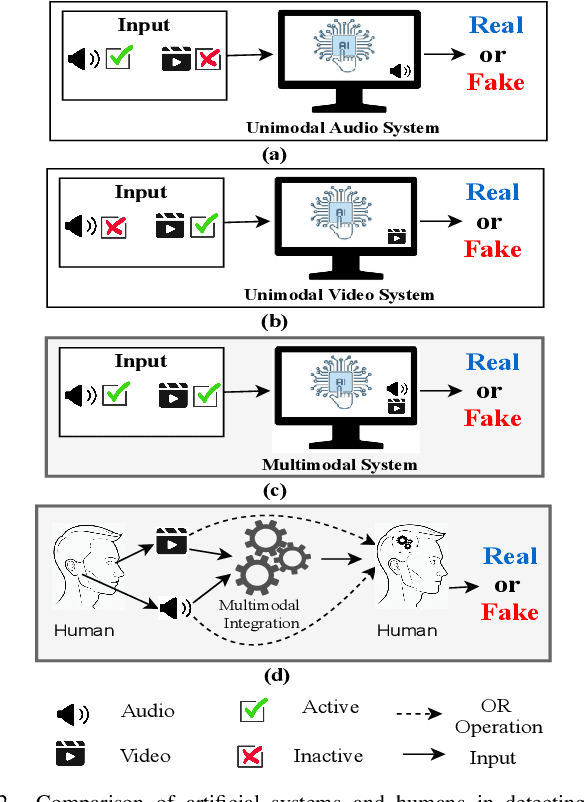
Forged content shared widely on social media platforms is a major social problem that requires increased regulation and poses new challenges to the research community. The recent proliferation of hyper-realistic deepfake videos has drawn attention to the threat of audio and visual forgeries. Most previous work on detecting AI-generated fake videos only utilizes visual modality or audio modality. While there are some methods in the literature that exploit audio and visual modalities to detect forged videos, they have not been comprehensively evaluated on multi-modal datasets of deepfake videos involving acoustic and visual manipulations. Moreover, these existing methods are mostly based on CNN and suffer from low detection accuracy. Inspired by the recent success of Transformer in various fields, to address the challenges posed by deepfake technology, in this paper, we propose an Audio-Visual Transformer-based Ensemble Network (AVTENet) framework that considers both acoustic manipulation and visual manipulation to achieve effective video forgery detection. Specifically, the proposed model integrates several purely transformer-based variants that capture video, audio, and audio-visual salient cues to reach a consensus in prediction. For evaluation, we use the recently released benchmark multi-modal audio-video FakeAVCeleb dataset. For a detailed analysis, we evaluate AVTENet, its variants, and several existing methods on multiple test sets of the FakeAVCeleb dataset. Experimental results show that our best model outperforms all existing methods and achieves state-of-the-art performance on Testset-I and Testset-II of the FakeAVCeleb dataset.