 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVTENet: Audio-Visual Transformer-based Ensemble Network Exploiting Multiple Experts for Video Deepfake Detection
Paper and Code
Oct 19, 2023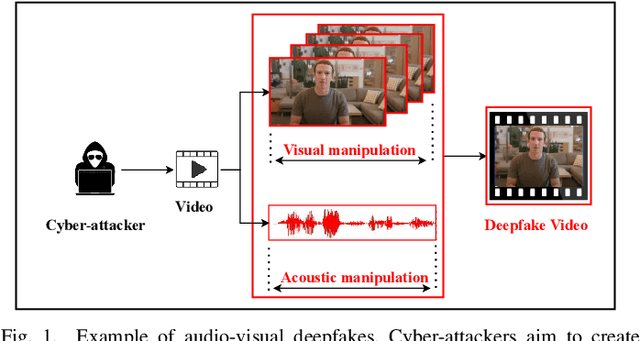
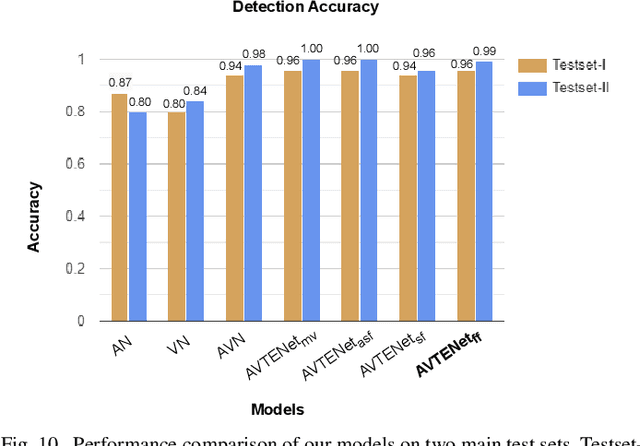
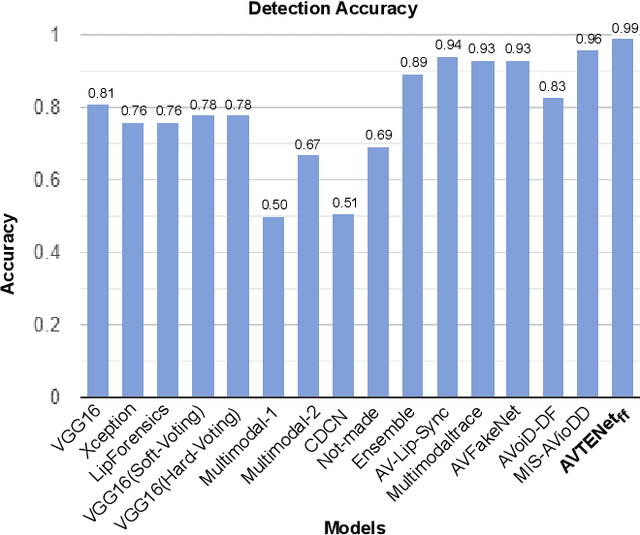
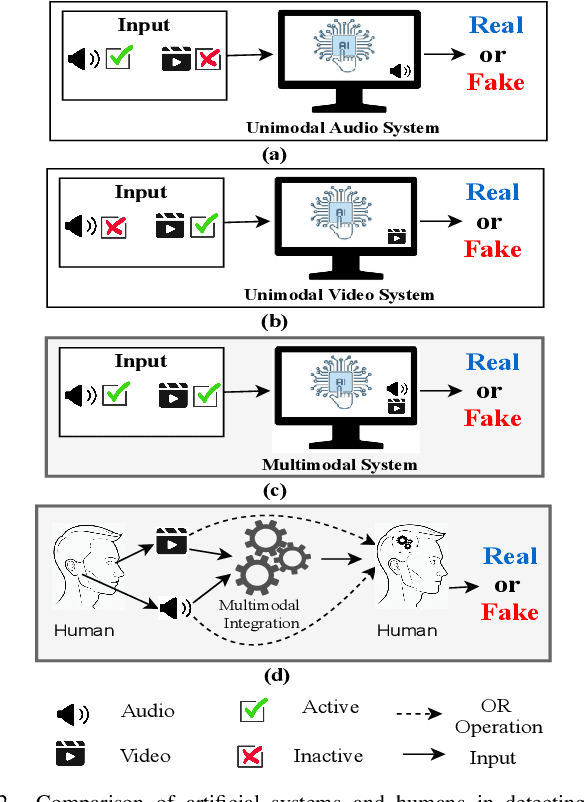
Forged content shared widely on social media platforms is a major social problem that requires increased regulation and poses new challenges to the research community. The recent proliferation of hyper-realistic deepfake videos has drawn attention to the threat of audio and visual forgeries. Most previous work on detecting AI-generated fake videos only utilizes visual modality or audio modality. While there are some methods in the literature that exploit audio and visual modalities to detect forged videos, they have not been comprehensively evaluated on multi-modal datasets of deepfake videos involving acoustic and visual manipulations. Moreover, these existing methods are mostly based on CNN and suffer from low detection accuracy. Inspired by the recent success of Transformer in various fields, to address the challenges posed by deepfake technology, in this paper, we propose an Audio-Visual Transformer-based Ensemble Network (AVTENet) framework that considers both acoustic manipulation and visual manipulation to achieve effective video forgery detection. Specifically, the proposed model integrates several purely transformer-based variants that capture video, audio, and audio-visual salient cues to reach a consensus in prediction. For evaluation, we use the recently released benchmark multi-modal audio-video FakeAVCeleb dataset. For a detailed analysis, we evaluate AVTENet, its variants, and several existing methods on multiple test sets of the FakeAVCeleb dataset. Experimental results show that our best model outperforms all existing methods and achieves state-of-the-art performance on Testset-I and Testset-II of the FakeAVCeleb dataset.