 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Human-Like RL Agents Through Trajectory Optimization With Action Quantization
Nov 19, 2025Human-like agents have long been one of the goals in pursuing artificial intelligence. Although reinforcement learning (RL) has achieved superhuman performance in many domains, relatively little attention has been focused on designing human-like RL agents. As a result, many reward-driven RL agents often exhibit unnatural behaviors compared to humans, raising concerns for both interpretability and trustworthiness. To achieve human-like behavior in RL, this paper first formulates human-likeness as trajectory optimization, where the objective is to find an action sequence that closely aligns with human behavior while also maximizing rewards, and adapts the classic receding-horizon control to human-like learning as a tractable and efficient implementation. To achieve this, we introduce Macro Action Quantization (MAQ), a human-like RL framework that distills human demonstrations into macro actions via Vector-Quantized VAE. Experiments on D4RL Adroit benchmarks show that MAQ significantly improves human-likeness, increasing trajectory similarity scores, and achieving the highest human-likeness rankings among all RL agents in the human evaluation study. Our results also demonstrate that MAQ can be easily integrated into various off-the-shelf RL algorithms, opening a promising direction for learning human-like RL agents. Our code is available at https://rlg.iis.sinica.edu.tw/papers/MAQ.
Action-Constrained Imitation Learning
Aug 20, 2025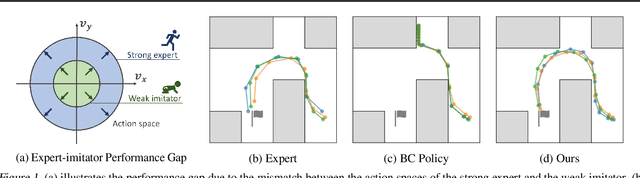
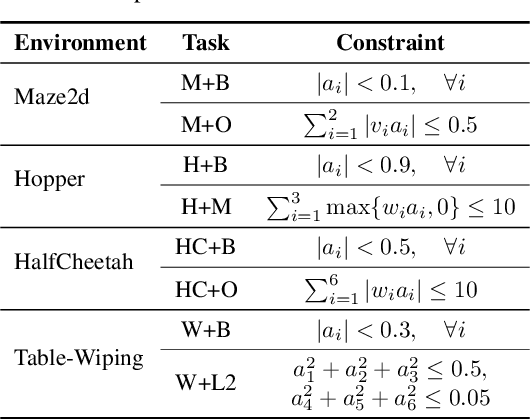
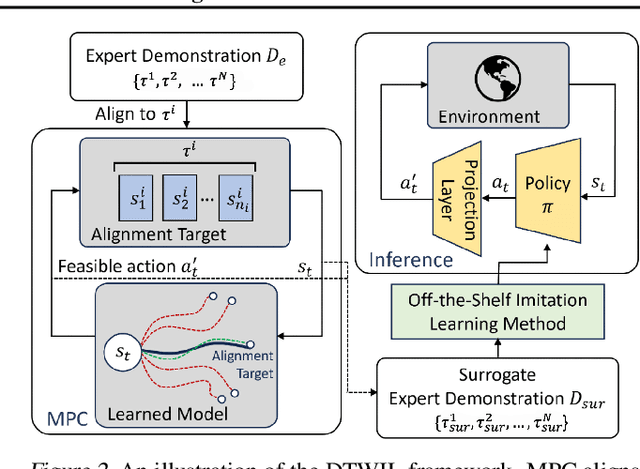
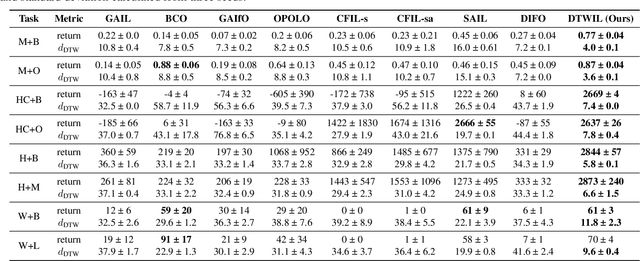
Policy learning under action constraints plays a central role in ensuring safe behaviors in various robot control and resource allocation applications. In this paper, we study a new problem setting termed Action-Constrained Imitation Learning (ACIL), where an action-constrained imitator aims to learn from a demonstrative expert with larger action space. The fundamental challenge of ACIL lies in the unavoidable mismatch of occupancy measure between the expert and the imitator caused by the action constraints. We tackle this mismatch through \textit{trajectory alignment} and propose DTWIL, which replaces the original expert demonstrations with a surrogate dataset that follows similar state trajectories while adhering to the action constraints. Specifically, we recast trajectory alignment as a planning problem and solve it via Model Predictive Control, which aligns the surrogate trajectories with the expert trajectories based on the Dynamic Time Warping (DTW) distance. Through extensive experiments, we demonstrate that learning from the dataset generated by DTWIL significantly enhances performance across multiple robot control tasks and outperforms various benchmark imitation learning algorithms in terms of sample efficiency. Our code is publicly available at https://github.com/NYCU-RL-Bandits-Lab/ACRL-Baselines.
BOFormer: Learning to Solve Multi-Objective Bayesian Optimization via Non-Markovian RL
May 29, 2025Bayesian optimization (BO) offers an efficient pipeline for optimizing black-box functions with the help of a Gaussian process prior and an acquisition function (AF). Recently, in the context of single-objective BO, learning-based AFs witnessed promising empirical results given its favorable non-myopic nature. Despite this, the direct extension of these approaches to multi-objective Bayesian optimization (MOBO) suffer from the \textit{hypervolume identifiability issue}, which results from the non-Markovian nature of MOBO problems. To tackle this, inspired by the non-Markovian RL literature and the success of Transformers in language modeling, we present a generalized deep Q-learning framework and propose \textit{BOFormer}, which substantiates this framework for MOBO via sequence modeling. Through extensive evaluation, we demonstrate that BOFormer constantly outperforms the benchmark rule-based and learning-based algorithms in various synthetic MOBO and real-world multi-objective hyperparameter optimization problems. We have made the source code publicly available to encourage further research in this direction.
Efficient Action-Constrained Reinforcement Learning via Acceptance-Rejection Method and Augmented MDPs
Mar 17, 2025Action-constrained reinforcement learning (ACRL) is a generic framework for learning control policies with zero action constraint violation, which is required by various safety-critical and resource-constrained applications. The existing ACRL methods can typically achieve favorable constraint satisfaction but at the cost of either high computational burden incurred by the quadratic programs (QP) or increased architectural complexity due to the use of sophisticated generative models. In this paper, we propose a generic and computationally efficient framework that can adapt a standard unconstrained RL method to ACRL through two modifications: (i) To enforce the action constraints, we leverage the classic acceptance-rejection method, where we treat the unconstrained policy as the proposal distribution and derive a modified policy with feasible actions. (ii) To improve the acceptance rate of the proposal distribution, we construct an augmented two-objective Markov decision process (MDP), which include additional self-loop state transitions and a penalty signal for the rejected actions. This augmented MDP incentives the learned policy to stay close to the feasible action sets. Through extensive experiments in both robot control and resource allocation domains, we demonstrate that the proposed framework enjoys faster training progress, better constraint satisfaction, and a lower action inference time simultaneously than the state-of-the-art ACRL methods. We have made the source code publicly available to encourage further research in this direction.
Imitation Learning of Correlated Policies in Stackelberg Games
Mar 11, 2025Stackelberg games, widely applied in domains like economics and security, involve asymmetric interactions where a leader's strategy drives follower responses. Accurately modeling these dynamics allows domain experts to optimize strategies in interactive scenarios, such as turn-based sports like badminton. In multi-agent systems, agent behaviors are interdependent, and traditional Multi-Agent Imitation Learning (MAIL) methods often fail to capture these complex interactions. Correlated policies, which account for opponents' strategies, are essential for accurately modeling such dynamics. However, even methods designed for learning correlated policies, like CoDAIL, struggle in Stackelberg games due to their asymmetric decision-making, where leaders and followers cannot simultaneously account for each other's actions, often leading to non-correlated policies. Furthermore, existing MAIL methods that match occupancy measures or use adversarial techniques like GAIL or Inverse RL face scalability challenges, particularly in high-dimensional environments, and suffer from unstable training. To address these challenges, we propose a correlated policy occupancy measure specifically designed for Stackelberg games and introduce the Latent Stackelberg Differential Network (LSDN) to match it. LSDN models two-agent interactions as shared latent state trajectories and uses multi-output Geometric Brownian Motion (MO-GBM) to effectively capture joint policies. By leveraging MO-GBM, LSDN disentangles environmental influences from agent-driven transitions in latent space, enabling the simultaneous learning of interdependent policies. This design eliminates the need for adversarial training and simplifies the learning process. Extensive experiments on Iterative Matrix Games and multi-agent particle environments demonstrate that LSDN can better reproduce complex interaction dynamics than existing MAIL methods.
Plan2Align: Predictive Planning Based Test-Time Preference Alignment in Paragraph-Level Machine Translation
Feb 28, 2025Machine Translation (MT) has been predominantly designed for sentence-level translation using transformer-based architectures. While next-token prediction based Large Language Models (LLMs) demonstrate strong capabilities in long-text translation, non-extensive language models often suffer from omissions and semantic inconsistencies when processing paragraphs. Existing preference alignment methods improve sentence-level translation but fail to ensure coherence over extended contexts due to the myopic nature of next-token generation. We introduce Plan2Align, a test-time alignment framework that treats translation as a predictive planning problem, adapting Model Predictive Control to iteratively refine translation outputs. Experiments on WMT24 Discourse-Level Literary Translation show that Plan2Align significantly improves paragraph-level translation, achieving performance surpassing or on par with the existing training-time and test-time alignment methods on LLaMA-3.1 8B.
Enhancing Offline Model-Based RL via Active Model Selection: A Bayesian Optimization Perspective
Feb 17, 2025Offline model-based reinforcement learning (MBRL) serves as a competitive framework that can learn well-performing policies solely from pre-collected data with the help of learned dynamics models. To fully unleash the power of offline MBRL, model selection plays a pivotal role in determining the dynamics model utilized for downstream policy learning. However, offline MBRL conventionally relies on validation or off-policy evaluation, which are rather inaccurate due to the inherent distribution shift in offline RL. To tackle this, we propose BOMS, an active model selection framework that enhances model selection in offline MBRL with only a small online interaction budget, through the lens of Bayesian optimization (BO). Specifically, we recast model selection as BO and enable probabilistic inference in BOMS by proposing a novel model-induced kernel, which is theoretically grounded and computationally efficient. Through extensive experiments, we show that BOMS improves over the baseline methods with a small amount of online interaction comparable to only $1\%$-$2.5\%$ of offline training data on various RL tasks.
Diminishing Exploration: A Minimalist Approach to Piecewise Stationary Multi-Armed Bandits
Oct 08, 2024
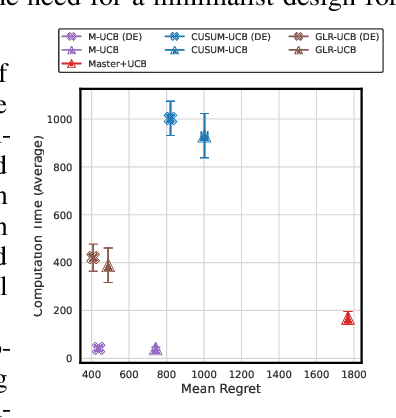
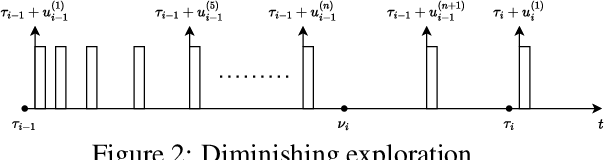

The piecewise-stationary bandit problem is an important variant of the multi-armed bandit problem that further considers abrupt changes in the reward distributions. The main theme of the problem is the trade-off between exploration for detecting environment changes and exploitation of traditional bandit algorithms. While this problem has been extensively investigated, existing works either assume knowledge about the number of change points $M$ or require extremely high computational complexity. In this work, we revisit the piecewise-stationary bandit problem from a minimalist perspective. We propose a novel and generic exploration mechanism, called diminishing exploration, which eliminates the need for knowledge about $M$ and can be used in conjunction with an existing change detection-based algorithm to achieve near-optimal regret scaling. Simulation results show that despite oblivious of $M$, equipping existing algorithms with the proposed diminishing exploration generally achieves better empirical regret than the traditional uniform exploration.
Diffusion-Reward Adversarial Imitation Learning
May 25, 2024



Imitation learning aims to learn a policy from observing expert demonstrations without access to reward signals from environments. Generative adversarial imitation learning (GAIL) formulates imitation learning as adversarial learning, employing a generator policy learning to imitate expert behaviors and discriminator learning to distinguish the expert demonstrations from agent trajectories. Despite its encouraging results, GAIL training is often brittle and unstable. Inspired by the recent dominance of diffusion models in generative modeling, this work proposes Diffusion-Reward Adversarial Imitation Learning (DRAIL), which integrates a diffusion model into GAIL, aiming to yield more precise and smoother rewards for policy learning. Specifically, we propose a diffusion discriminative classifier to construct an enhanced discriminator; then, we design diffusion rewards based on the classifier's output for policy learning. We conduct extensive experiments in navigation, manipulation, and locomotion, verifying DRAIL's effectiveness compared to prior imitation learning methods. Moreover, additional experimental results demonstrate the generalizability and data efficiency of DRAIL. Visualized learned reward functions of GAIL and DRAIL suggest that DRAIL can produce more precise and smoother rewards.
Image Deraining via Self-supervised Reinforcement Learning
Mar 27, 2024



The quality of images captured outdoors is often affected by the weather. One factor that interferes with sight is rain, which can obstruct the view of observers and computer vision applications that rely on those images. The work aims to recover rain images by removing rain streaks via Self-supervised Reinforcement Learning (RL) for image deraining (SRL-Derain). We locate rain streak pixels from the input rain image via dictionary learning and use pixel-wise RL agents to take multiple inpainting actions to remove rain progressively. To our knowledge, this work is the first attempt where self-supervised RL is applied to image deraining. Experimental results on several benchmark image-deraining datasets show that the proposed SRL-Derain performs favorably against state-of-the-art few-shot and self-supervised deraining and denoising methods.