 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee Less, Specify More: Visual Evidence Budgets for Generalizable VLAs
Jun 01, 2026Generalization remains a central bottleneck for vision-language-action (VLA) models: under distractors, appearance shifts, and semantically similar tasks, the policy must often infer local execution details from coarse instructions while also deciding which parts of the image matter for control. We present S2 (See Less, Specify More), a framework for improving VLA generalization by training the executor under a cleaner interface. Specify More preserves the original instruction as a stable high-level goal while relabeling each trajectory into refined trajectory- and subtask-level language that disambiguates the current execution mode. Unlike native attention, See Less imposes an explicit visual evidence budget, training the executor to act from task-sufficient evidence rather than unconstrained visual context, without any region or mask annotation. This interface lets the executor follow detailed guidance without relying on distracting visual patches or resolving avoidable ambiguity on its own, and it remains compatible with off-the-shelf VLM planners through in-context learning. Across our main evaluation settings, S2 improves overall generalization metrics by changing the executor's learning problem: coarse instructions induce avoidable supervision aliasing, goal-preserving local guidance outperforms instruction replacement in our main ablations, and explicit evidence budgeting reduces dependence on broad visual context beyond efficiency considerations. Across eight real-robot tasks on TX-G2 (an AgiBot G2-compatible variant) and HSR, S2 raises mean subtask success from 54.2% to 79.0% over pi0.5. Together, these results suggest that VLA generalization improves when the executor is trained to act from informative local guidance and task-sufficient visual evidence, rather than recovering both from weak supervision.
Continuous Reasoning for Vision-Language-Action
May 29, 2026Natural language is a powerful reasoning medium for language and vision-language models, but it is mismatched to the granularity of continuous control. Text and explicit subgoals operate at task-level granularity, whereas vision-language-action (VLA) policies must choose actions at a much finer temporal scale; a single reasoning step can therefore span many action chunks while remaining only weakly coupled to the action needed now. This suggests a different question for VLA: what should play the role of language? We argue that a useful VLA reasoning medium must be shareable across model instances, verifiable through downstream action improvement, and aligned with temporally extended control structure. Based on this view, we propose Continuous Reasoning for Vision-Language-Action. Our model first predicts continuous reasoning in the form of a structured set of continuous thoughts, then reuses them as shared context for chunk-structured action generation. Better action prediction alone does not certify good reasoning: if the same internal medium cannot be shared across model instances and independently verified through improved downstream control, the added latent may simply become a model-private shortcut that helps on seen behaviors without supporting generalizable control. We therefore instantiate continuous reasoning as a shared Gaussian latent interface and train it with a self-verification objective in which an exponential-moving-average teacher must successfully consume the student's reasoning when predicting target actions. Empirically, Continuous Reasoning improves LIBERO-PRO robustness and performs strongly on real robots, raising mean subtask success over π0.5 by 40.4% on TX-G2, an AgiBot G2-compatible variant, and 26.3% on HSR. This suggests that reasoning in VLA is less about extra tokens than about a shareable, verifiable internal language for action.
Learning Skills from Action-Free Videos
Dec 23, 2025Learning from videos offers a promising path toward generalist robots by providing rich visual and temporal priors beyond what real robot datasets contain. While existing video generative models produce impressive visual predictions, they are difficult to translate into low-level actions. Conversely, latent-action models better align videos with actions, but they typically operate at the single-step level and lack high-level planning capabilities. We bridge this gap by introducing Skill Abstraction from Optical Flow (SOF), a framework that learns latent skills from large collections of action-free videos. Our key idea is to learn a latent skill space through an intermediate representation based on optical flow that captures motion information aligned with both video dynamics and robot actions. By learning skills in this flow-based latent space, SOF enables high-level planning over video-derived skills and allows for easier translation of these skills into actions. Experiments show that our approach consistently improves performance in both multitask and long-horizon settings, demonstrating the ability to acquire and compose skills directly from raw visual data.
Unified Reinforcement and Imitation Learning for Vision-Language Models
Oct 22, 2025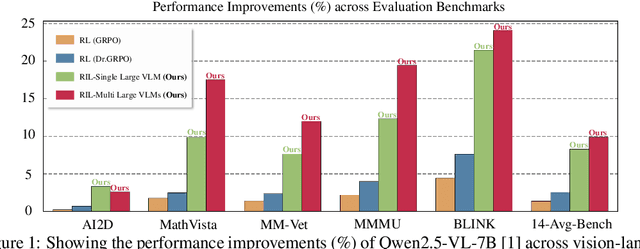



Vision-Language Models (VLMs) have achieved remarkable progress, yet their large scale often renders them impractical for resource-constrained environments. This paper introduces Unified Reinforcement and Imitation Learning (RIL), a novel and efficient training algorithm designed to create powerful, lightweight VLMs. RIL distinctively combines the strengths of reinforcement learning with adversarial imitation learning. This enables smaller student VLMs not only to mimic the sophisticated text generation of large teacher models but also to systematically improve their generative capabilities through reinforcement signals. Key to our imitation framework is an LLM-based discriminator that adeptly distinguishes between student and teacher outputs, complemented by guidance from multiple large teacher VLMs to ensure diverse learning. This unified learning strategy, leveraging both reinforcement and imitation, empowers student models to achieve significant performance gains, making them competitive with leading closed-source VLMs. Extensive experiments on diverse vision-language benchmarks demonstrate that RIL significantly narrows the performance gap with state-of-the-art open- and closed-source VLMs and, in several instances, surpasses them.
ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning
Jul 22, 2025



Vision-language-action (VLA) reasoning tasks require agents to interpret multimodal instructions, perform long-horizon planning, and act adaptively in dynamic environments. Existing approaches typically train VLA models in an end-to-end fashion, directly mapping inputs to actions without explicit reasoning, which hinders their ability to plan over multiple steps or adapt to complex task variations. In this paper, we propose ThinkAct, a dual-system framework that bridges high-level reasoning with low-level action execution via reinforced visual latent planning. ThinkAct trains a multimodal LLM to generate embodied reasoning plans guided by reinforcing action-aligned visual rewards based on goal completion and trajectory consistency. These reasoning plans are compressed into a visual plan latent that conditions a downstream action model for robust action execution on target environments. Extensive experiments on embodied reasoning and robot manipulation benchmarks demonstrate that ThinkAct enables few-shot adaptation, long-horizon planning, and self-correction behaviors in complex embodied AI tasks.
GenRecal: Generation after Recalibration from Large to Small Vision-Language Models
Jun 18, 2025Recent advancements in vision-language models (VLMs) have leveraged large language models (LLMs) to achieve performance on par with closed-source systems like GPT-4V. However, deploying these models in real-world scenarios, particularly on resource-constrained devices, remains challenging due to their substantial computational demands. This has spurred interest in distilling knowledge from large VLMs into smaller, more efficient counterparts. A key challenge arises here from the diversity of VLM architectures, which are built on different LLMs and employ varying token types-differing in vocabulary size, token splits, and token index ordering. To address this challenge of limitation to a specific VLM type, we present Generation after Recalibration (GenRecal), a novel, general-purpose distillation framework for VLMs. GenRecal incorporates a Recalibrator that aligns and adapts feature representations between heterogeneous VLMs, enabling effective knowledge transfer across different types of VLMs. Through extensive experiments on multiple challenging benchmarks, we demonstrate that GenRecal significantly improves baseline performances, eventually outperforming large-scale open- and closed-source VLMs.
Plan2Align: Predictive Planning Based Test-Time Preference Alignment in Paragraph-Level Machine Translation
Feb 28, 2025Machine Translation (MT) has been predominantly designed for sentence-level translation using transformer-based architectures. While next-token prediction based Large Language Models (LLMs) demonstrate strong capabilities in long-text translation, non-extensive language models often suffer from omissions and semantic inconsistencies when processing paragraphs. Existing preference alignment methods improve sentence-level translation but fail to ensure coherence over extended contexts due to the myopic nature of next-token generation. We introduce Plan2Align, a test-time alignment framework that treats translation as a predictive planning problem, adapting Model Predictive Control to iteratively refine translation outputs. Experiments on WMT24 Discourse-Level Literary Translation show that Plan2Align significantly improves paragraph-level translation, achieving performance surpassing or on par with the existing training-time and test-time alignment methods on LLaMA-3.1 8B.
VLsI: Verbalized Layers-to-Interactions from Large to Small Vision Language Models
Dec 02, 2024



The recent surge in high-quality visual instruction tuning samples from closed-source vision-language models (VLMs) such as GPT-4V has accelerated the release of open-source VLMs across various model sizes. However, scaling VLMs to improve performance using larger models brings significant computational challenges, especially for deployment on resource-constrained devices like mobile platforms and robots. To address this, we propose VLsI: Verbalized Layers-to-Interactions, a new VLM family in 2B and 7B model sizes, which prioritizes efficiency without compromising accuracy. VLsI leverages a unique, layer-wise distillation process, introducing intermediate "verbalizers" that map features from each layer to natural language space, allowing smaller VLMs to flexibly align with the reasoning processes of larger VLMs. This approach mitigates the training instability often encountered in output imitation and goes beyond typical final-layer tuning by aligning the small VLMs' layer-wise progression with that of the large ones. We validate VLsI across ten challenging vision-language benchmarks, achieving notable performance gains (11.0% for 2B and 17.4% for 7B) over GPT-4V without the need for model scaling, merging, or architectural changes.
DNAct: Diffusion Guided Multi-Task 3D Policy Learning
Mar 08, 2024
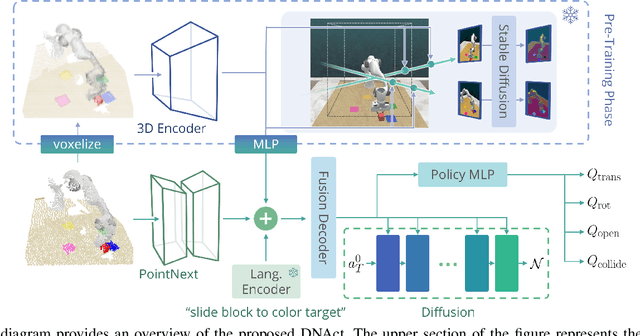


This paper presents DNAct, a language-conditioned multi-task policy framework that integrates neural rendering pre-training and diffusion training to enforce multi-modality learning in action sequence spaces. To learn a generalizable multi-task policy with few demonstrations, the pre-training phase of DNAct leverages neural rendering to distill 2D semantic features from foundation models such as Stable Diffusion to a 3D space, which provides a comprehensive semantic understanding regarding the scene. Consequently, it allows various applications to challenging robotic tasks requiring rich 3D semantics and accurate geometry. Furthermore, we introduce a novel approach utilizing diffusion training to learn a vision and language feature that encapsulates the inherent multi-modality in the multi-task demonstrations. By reconstructing the action sequences from different tasks via the diffusion process, the model is capable of distinguishing different modalities and thus improving the robustness and the generalizability of the learned representation. DNAct significantly surpasses SOTA NeRF-based multi-task manipulation approaches with over 30% improvement in success rate. Project website: dnact.github.io.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.