 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNAct: Diffusion Guided Multi-Task 3D Policy Learning
Paper and Code

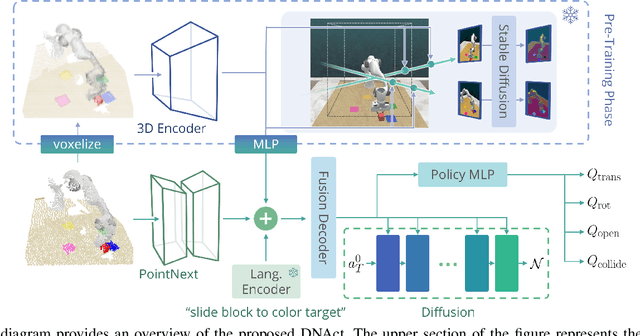


This paper presents DNAct, a language-conditioned multi-task policy framework that integrates neural rendering pre-training and diffusion training to enforce multi-modality learning in action sequence spaces. To learn a generalizable multi-task policy with few demonstrations, the pre-training phase of DNAct leverages neural rendering to distill 2D semantic features from foundation models such as Stable Diffusion to a 3D space, which provides a comprehensive semantic understanding regarding the scene. Consequently, it allows various applications to challenging robotic tasks requiring rich 3D semantics and accurate geometry. Furthermore, we introduce a novel approach utilizing diffusion training to learn a vision and language feature that encapsulates the inherent multi-modality in the multi-task demonstrations. By reconstructing the action sequences from different tasks via the diffusion process, the model is capable of distinguishing different modalities and thus improving the robustness and the generalizability of the learned representation. DNAct significantly surpasses SOTA NeRF-based multi-task manipulation approaches with over 30% improvement in success rate. Project website: dnact.github.io.