 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
Feb 29, 2024



Today's deep learning methods focus on how to design the most appropriate objective functions so that the prediction results of the model can be closest to the ground truth. Meanwhile, an appropriate architecture that can facilitate acquisition of enough information for prediction has to be designed. Existing methods ignore a fact that when input data undergoes layer-by-layer feature extraction and spatial transformation, large amount of information will be lost. This paper will delve into the important issues of data loss when data is transmitted through deep networks, namely information bottleneck and reversible functions. We proposed the concept of programmable gradient information (PGI) to cope with the various changes required by deep networks to achieve multiple objectives. PGI can provide complete input information for the target task to calculate objective function, so that reliable gradient information can be obtained to update network weights. In addition, a new lightweight network architecture -- Generalized Efficient Layer Aggregation Network (GELAN), based on gradient path planning is designed. GELAN's architecture confirms that PGI has gained superior results on lightweight models. We verified the proposed GELAN and PGI on MS COCO dataset based object detection. The results show that GELAN only uses conventional convolution operators to achieve better parameter utilization than the state-of-the-art methods developed based on depth-wise convolution. PGI can be used for variety of models from lightweight to large. It can be used to obtain complete information, so that train-from-scratch models can achieve better results than state-of-the-art models pre-trained using large datasets, the comparison results are shown in Figure 1. The source codes are at: https://github.com/WongKinYiu/yolov9.
Designing Network Design Strategies Through Gradient Path Analysis
Nov 09, 2022Designing a high-efficiency and high-quality expressive network architecture has always been the most important research topic in the field of deep learning. Most of today's network design strategies focus on how to integrate features extracted from different layers, and how to design computing units to effectively extract these features, thereby enhancing the expressiveness of the network. This paper proposes a new network design strategy, i.e., to design the network architecture based on gradient path analysis. On the whole, most of today's mainstream network design strategies are based on feed forward path, that is, the network architecture is designed based on the data path. In this paper, we hope to enhance the expressive ability of the trained model by improving the network learning ability. Due to the mechanism driving the network parameter learning is the backward propagation algorithm, we design network design strategies based on back propagation path. We propose the gradient path design strategies for the layer-level, the stage-level, and the network-level, and the design strategies are proved to be superior and feasible from theoretical analysis and experiments.
You Only Learn One Representation: Unified Network for Multiple Tasks
May 10, 2021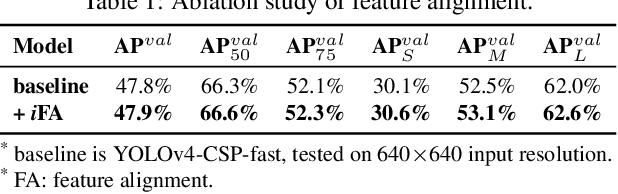
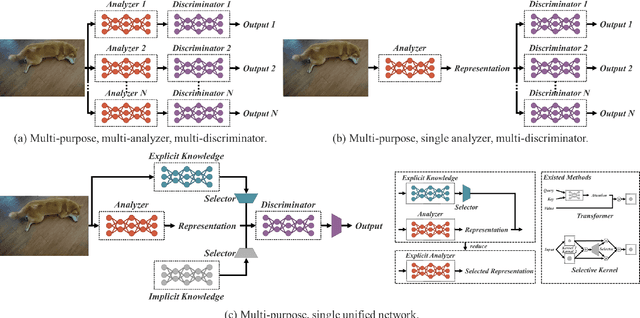
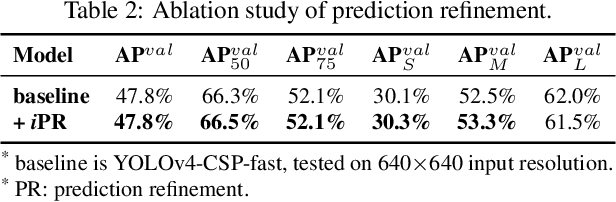
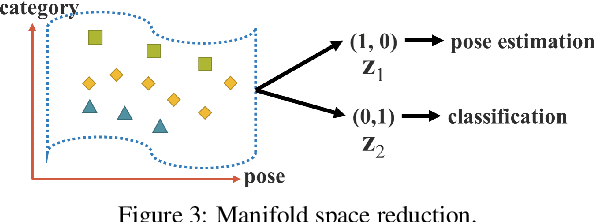
People ``understand'' the world via vision, hearing, tactile, and also the past experience. Human experience can be learned through normal learning (we call it explicit knowledge), or subconsciously (we call it implicit knowledge). These experiences learned through normal learning or subconsciously will be encoded and stored in the brain. Using these abundant experience as a huge database, human beings can effectively process data, even they were unseen beforehand. In this paper, we propose a unified network to encode implicit knowledge and explicit knowledge together, just like the human brain can learn knowledge from normal learning as well as subconsciousness learning. The unified network can generate a unified representation to simultaneously serve various tasks. We can perform kernel space alignment, prediction refinement, and multi-task learning in a convolutional neural network. The results demonstrate that when implicit knowledge is introduced into the neural network, it benefits the performance of all tasks. We further analyze the implicit representation learnt from the proposed unified network, and it shows great capability on catching the physical meaning of different tasks. The source code of this work is at : https://github.com/WongKinYiu/yolor.
Batch-Augmented Multi-Agent Reinforcement Learning for Efficient Traffic Signal Optimization
May 19, 2020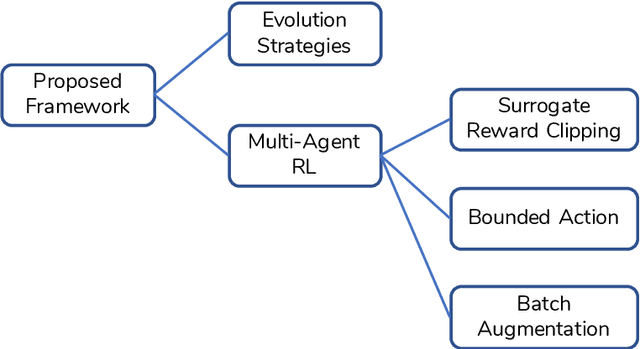
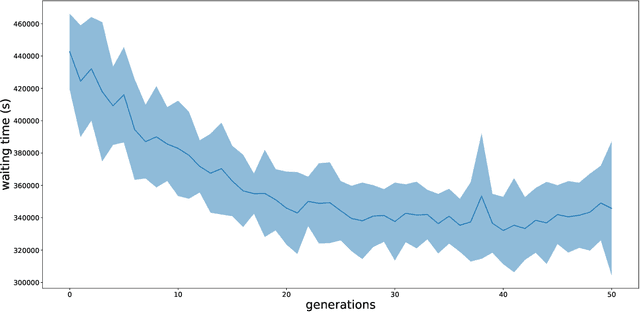
The goal of this work is to provide a viable solution based on reinforcement learning for traffic signal control problems. Although the state-of-the-art reinforcement learning approaches have yielded great success in a variety of domains, directly applying it to alleviate traffic congestion can be challenging, considering the requirement of high sample efficiency and how training data is gathered. In this work, we address several challenges that we encountered when we attempted to mitigate serious traffic congestion occurring in a metropolitan area. Specifically, we are required to provide a solution that is able to (1) handle the traffic signal control when certain surveillance cameras that retrieve information for reinforcement learning are down, (2) learn from batch data without a traffic simulator, and (3) make control decisions without shared information across intersections. We present a two-stage framework to deal with the above-mentioned situations. The framework can be decomposed into an Evolution Strategies approach that gives a fixed-time traffic signal control schedule and a multi-agent off-policy reinforcement learning that is capable of learning from batch data with the aid of three proposed components, bounded action, batch augmentation, and surrogate reward clipping. Our experiments show that the proposed framework reduces traffic congestion by 36% in terms of waiting time compared with the currently used fixed-time traffic signal plan. Furthermore, the framework requires only 600 queries to a simulator to achieve the result.
CSPNet: A New Backbone that can Enhance Learning Capability of CNN
Nov 27, 2019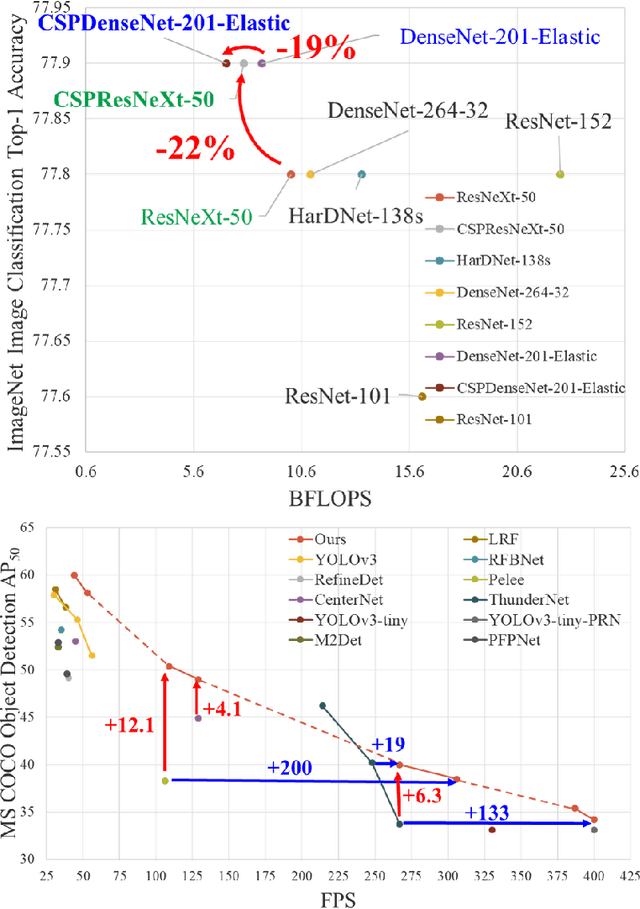


Neural networks have enabled state-of-the-art approaches to achieve incredible results on computer vision tasks such as object detection. However, such success greatly relies on costly computation resources, which hinders people with cheap devices from appreciating the advanced technology. In this paper, we propose Cross Stage Partial Network (CSPNet) to mitigate the problem that previous works require heavy inference computations from the network architecture perspective. We attribute the problem to the duplicate gradient information within network optimization. The proposed networks respect the variability of the gradients by integrating feature maps from the beginning and the end of a network stage, which, in our experiments, reduces computations by 20% with equivalent or even superior accuracy on the ImageNet dataset, and significantly outperforms state-of-the-art approaches in terms of AP50 on the MS COCO object detection dataset. The CSPNet is easy to implement and general enough to cope with architectures based on ResNet, ResNeXt, and DenseNet. Source code is at https://github.com/WongKinYiu/CrossStagePartialNetworks.