 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Hand Latent Representation for Vision-Language-Action Models
Mar 10, 2026Dexterous manipulation is essential for real-world robot autonomy, mirroring the central role of human hand coordination in daily activity. Humans rely on rich multimodal perception--vision, sound, and language-guided intent--to perform dexterous actions, motivating vision-based, language-conditioned manipulation systems for robots. However, training reliable vision-language-action (VLA) models for dexterous manipulation requires large-scale demonstrations across many robotic hands. In addition, as new dexterous embodiments appear rapidly, collecting data for each becomes costly and impractical, creating a need for scalable cross-embodiment learning. We introduce XL-VLA, a vision-language-action framework integrated with a unified latent action space shared across diverse dexterous hands. This embodiment-invariant latent space is directly pluggable into standard VLA architectures, enabling seamless cross-embodiment training and efficient reuse of both existing and newly collected data. Experimental results demonstrate that XL-VLA consistently outperforms baseline VLA models operating in raw joint spaces, establishing it as an effective solution for scalable cross-embodiment dexterous manipulation.
Contact-Aware Neural Dynamics
Jan 19, 2026High-fidelity physics simulation is essential for scalable robotic learning, but the sim-to-real gap persists, especially for tasks involving complex, dynamic, and discontinuous interactions like physical contacts. Explicit system identification, which tunes explicit simulator parameters, is often insufficient to align the intricate, high-dimensional, and state-dependent dynamics of the real world. To overcome this, we propose an implicit sim-to-real alignment framework that learns to directly align the simulator's dynamics with contact information. Our method treats the off-the-shelf simulator as a base prior and learns a contact-aware neural dynamics model to refine simulated states using real-world observations. We show that using tactile contact information from robotic hands can effectively model the non-smooth discontinuities inherent in contact-rich tasks, resulting in a neural dynamics model grounded by real-world data. We demonstrate that this learned forward dynamics model improves state prediction accuracy and can be effectively used to predict policy performance and refine policies trained purely in standard simulators, offering a scalable, data-driven approach to sim-to-real alignment.
From Power to Precision: Learning Fine-grained Dexterity for Multi-fingered Robotic Hands
Nov 17, 2025



Human grasps can be roughly categorized into two types: power grasps and precision grasps. Precision grasping enables tool use and is believed to have influenced human evolution. Today's multi-fingered robotic hands are effective in power grasps, but for tasks requiring precision, parallel grippers are still more widely adopted. This contrast highlights a key limitation in current robotic hand design: the difficulty of achieving both stable power grasps and precise, fine-grained manipulation within a single, versatile system. In this work, we bridge this gap by jointly optimizing the control and hardware design of a multi-fingered dexterous hand, enabling both power and precision manipulation. Rather than redesigning the entire hand, we introduce a lightweight fingertip geometry modification, represent it as a contact plane, and jointly optimize its parameters along with the corresponding control. Our control strategy dynamically switches between power and precision manipulation and simplifies precision control into parallel thumb-index motions, which proves robust for sim-to-real transfer. On the design side, we leverage large-scale simulation to optimize the fingertip geometry using a differentiable neural-physics surrogate model. We validate our approach through extensive experiments in both sim-to-real and real-to-real settings. Our method achieves an 82.5% zero-shot success rate on unseen objects in sim-to-real precision grasping, and a 93.3% success rate in challenging real-world tasks involving bread pinching. These results demonstrate that our co-design framework can significantly enhance the fine-grained manipulation ability of multi-fingered hands without reducing their ability for power grasps. Our project page is at https://jianglongye.com/power-to-precision
Real Deep Research for AI, Robotics and Beyond
Oct 23, 2025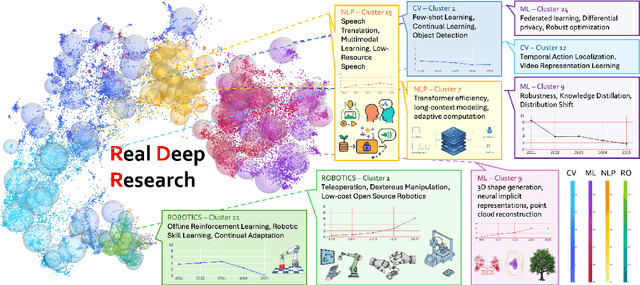
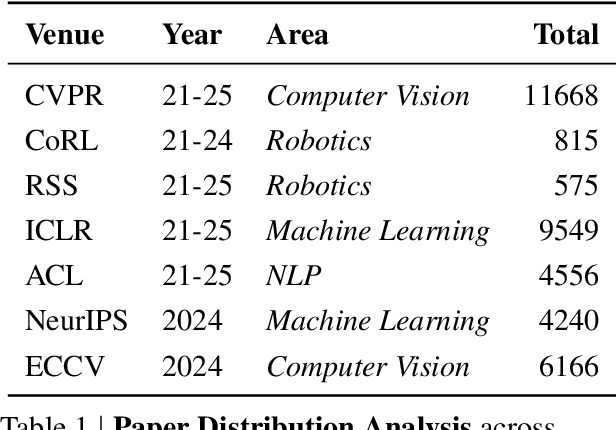
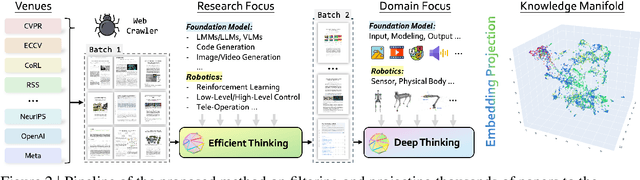
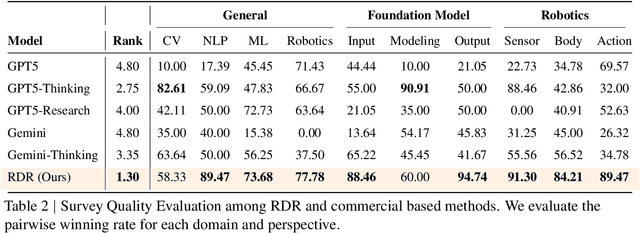
With the rapid growth of research in AI and robotics now producing over 10,000 papers annually it has become increasingly difficult for researchers to stay up to date. Fast evolving trends, the rise of interdisciplinary work, and the need to explore domains beyond one's expertise all contribute to this challenge. To address these issues, we propose a generalizable pipeline capable of systematically analyzing any research area: identifying emerging trends, uncovering cross domain opportunities, and offering concrete starting points for new inquiry. In this work, we present Real Deep Research (RDR) a comprehensive framework applied to the domains of AI and robotics, with a particular focus on foundation models and robotics advancements. We also briefly extend our analysis to other areas of science. The main paper details the construction of the RDR pipeline, while the appendix provides extensive results across each analyzed topic. We hope this work sheds light for researchers working in the field of AI and beyond.
Co-Design of Soft Gripper with Neural Physics
May 26, 2025



For robot manipulation, both the controller and end-effector design are crucial. Soft grippers are generalizable by deforming to different geometries, but designing such a gripper and finding its grasp pose remains challenging. In this paper, we propose a co-design framework that generates an optimized soft gripper's block-wise stiffness distribution and its grasping pose, using a neural physics model trained in simulation. We derived a uniform-pressure tendon model for a flexure-based soft finger, then generated a diverse dataset by randomizing both gripper pose and design parameters. A neural network is trained to approximate this forward simulation, yielding a fast, differentiable surrogate. We embed that surrogate in an end-to-end optimization loop to optimize the ideal stiffness configuration and best grasp pose. Finally, we 3D-print the optimized grippers of various stiffness by changing the structural parameters. We demonstrate that our co-designed grippers significantly outperform baseline designs in both simulation and hardware experiments.
M3: 3D-Spatial MultiModal Memory
Mar 20, 2025We present 3D Spatial MultiModal Memory (M3), a multimodal memory system designed to retain information about medium-sized static scenes through video sources for visual perception. By integrating 3D Gaussian Splatting techniques with foundation models, M3 builds a multimodal memory capable of rendering feature representations across granularities, encompassing a wide range of knowledge. In our exploration, we identify two key challenges in previous works on feature splatting: (1) computational constraints in storing high-dimensional features for each Gaussian primitive, and (2) misalignment or information loss between distilled features and foundation model features. To address these challenges, we propose M3 with key components of principal scene components and Gaussian memory attention, enabling efficient training and inference. To validate M3, we conduct comprehensive quantitative evaluations of feature similarity and downstream tasks, as well as qualitative visualizations to highlight the pixel trace of Gaussian memory attention. Our approach encompasses a diverse range of foundation models, including vision-language models (VLMs), perception models, and large multimodal and language models (LMMs/LLMs). Furthermore, to demonstrate real-world applicability, we deploy M3's feature field in indoor scenes on a quadruped robot. Notably, we claim that M3 is the first work to address the core compression challenges in 3D feature distillation.
Learning Generalizable Feature Fields for Mobile Manipulation
Mar 12, 2024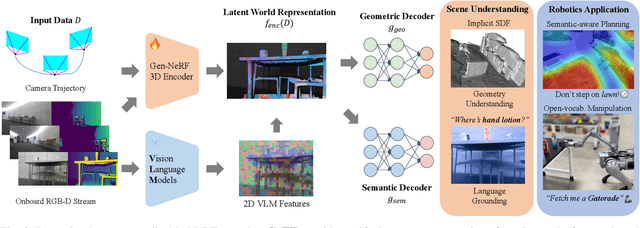


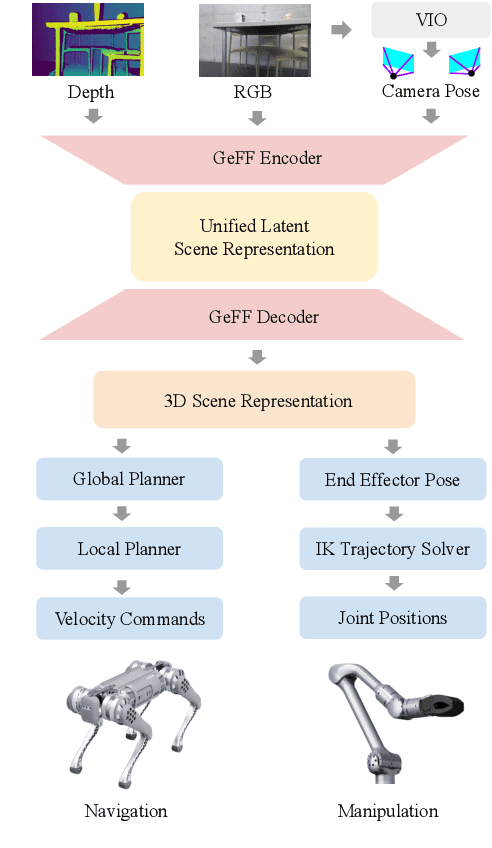
An open problem in mobile manipulation is how to represent objects and scenes in a unified manner, so that robots can use it both for navigating in the environment and manipulating objects. The latter requires capturing intricate geometry while understanding fine-grained semantics, whereas the former involves capturing the complexity inherit to an expansive physical scale. In this work, we present GeFF (Generalizable Feature Fields), a scene-level generalizable neural feature field that acts as a unified representation for both navigation and manipulation that performs in real-time. To do so, we treat generative novel view synthesis as a pre-training task, and then align the resulting rich scene priors with natural language via CLIP feature distillation. We demonstrate the effectiveness of this approach by deploying GeFF on a quadrupedal robot equipped with a manipulator. We evaluate GeFF's ability to generalize to open-set objects as well as running time, when performing open-vocabulary mobile manipulation in dynamic scenes.
Consistent-1-to-3: Consistent Image to 3D View Synthesis via Geometry-aware Diffusion Models
Oct 04, 2023
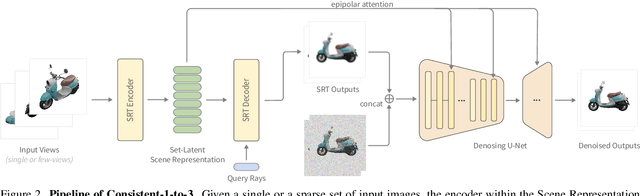


Zero-shot novel view synthesis (NVS) from a single image is an essential problem in 3D object understanding. While recent approaches that leverage pre-trained generative models can synthesize high-quality novel views from in-the-wild inputs, they still struggle to maintain 3D consistency across different views. In this paper, we present Consistent-1-to-3, which is a generative framework that significantly mitigate this issue. Specifically, we decompose the NVS task into two stages: (i) transforming observed regions to a novel view, and (ii) hallucinating unseen regions. We design a scene representation transformer and view-conditioned diffusion model for performing these two stages respectively. Inside the models, to enforce 3D consistency, we propose to employ epipolor-guided attention to incorporate geometry constraints, and multi-view attention to better aggregate multi-view information. Finally, we design a hierarchy generation paradigm to generate long sequences of consistent views, allowing a full 360 observation of the provided object image. Qualitative and quantitative evaluation over multiple datasets demonstrate the effectiveness of the proposed mechanisms against state-of-the-art approaches. Our project page is at https://jianglongye.com/consistent123/
GNFactor: Multi-Task Real Robot Learning with Generalizable Neural Feature Fields
Sep 01, 2023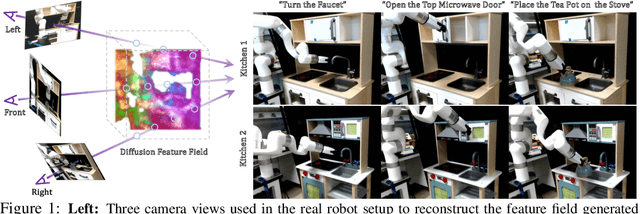



It is a long-standing problem in robotics to develop agents capable of executing diverse manipulation tasks from visual observations in unstructured real-world environments. To achieve this goal, the robot needs to have a comprehensive understanding of the 3D structure and semantics of the scene. In this work, we present $\textbf{GNFactor}$, a visual behavior cloning agent for multi-task robotic manipulation with $\textbf{G}$eneralizable $\textbf{N}$eural feature $\textbf{F}$ields. GNFactor jointly optimizes a generalizable neural field (GNF) as a reconstruction module and a Perceiver Transformer as a decision-making module, leveraging a shared deep 3D voxel representation. To incorporate semantics in 3D, the reconstruction module utilizes a vision-language foundation model ($\textit{e.g.}$, Stable Diffusion) to distill rich semantic information into the deep 3D voxel. We evaluate GNFactor on 3 real robot tasks and perform detailed ablations on 10 RLBench tasks with a limited number of demonstrations. We observe a substantial improvement of GNFactor over current state-of-the-art methods in seen and unseen tasks, demonstrating the strong generalization ability of GNFactor. Our project website is https://yanjieze.com/GNFactor/ .
MVDream: Multi-view Diffusion for 3D Generation
Aug 31, 2023



We propose MVDream, a multi-view diffusion model that is able to generate geometrically consistent multi-view images from a given text prompt. By leveraging image diffusion models pre-trained on large-scale web datasets and a multi-view dataset rendered from 3D assets, the resulting multi-view diffusion model can achieve both the generalizability of 2D diffusion and the consistency of 3D data. Such a model can thus be applied as a multi-view prior for 3D generation via Score Distillation Sampling, where it greatly improves the stability of existing 2D-lifting methods by solving the 3D consistency problem. Finally, we show that the multi-view diffusion model can also be fine-tuned under a few shot setting for personalized 3D generation, i.e. DreamBooth3D application, where the consistency can be maintained after learning the subject identity.