 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexTrack: Towards Generalizable Neural Tracking Control for Dexterous Manipulation from Human References
Feb 13, 2025We address the challenge of developing a generalizable neural tracking controller for dexterous manipulation from human references. This controller aims to manage a dexterous robot hand to manipulate diverse objects for various purposes defined by kinematic human-object interactions. Developing such a controller is complicated by the intricate contact dynamics of dexterous manipulation and the need for adaptivity, generalizability, and robustness. Current reinforcement learning and trajectory optimization methods often fall short due to their dependence on task-specific rewards or precise system models. We introduce an approach that curates large-scale successful robot tracking demonstrations, comprising pairs of human references and robot actions, to train a neural controller. Utilizing a data flywheel, we iteratively enhance the controller's performance, as well as the number and quality of successful tracking demonstrations. We exploit available tracking demonstrations and carefully integrate reinforcement learning and imitation learning to boost the controller's performance in dynamic environments. At the same time, to obtain high-quality tracking demonstrations, we individually optimize per-trajectory tracking by leveraging the learned tracking controller in a homotopy optimization method. The homotopy optimization, mimicking chain-of-thought, aids in solving challenging trajectory tracking problems to increase demonstration diversity. We showcase our success by training a generalizable neural controller and evaluating it in both simulation and real world. Our method achieves over a 10% improvement in success rates compared to leading baselines. The project website with animated results is available at https://meowuu7.github.io/DexTrack/.
ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI
Oct 01, 2024



Simulation has enabled unprecedented compute-scalable approaches to robot learning. However, many existing simulation frameworks typically support a narrow range of scenes/tasks and lack features critical for scaling generalizable robotics and sim2real. We introduce and open source ManiSkill3, the fastest state-visual GPU parallelized robotics simulator with contact-rich physics targeting generalizable manipulation. ManiSkill3 supports GPU parallelization of many aspects including simulation+rendering, heterogeneous simulation, pointclouds/voxels visual input, and more. Simulation with rendering on ManiSkill3 can run 10-1000x faster with 2-3x less GPU memory usage than other platforms, achieving up to 30,000+ FPS in benchmarked environments due to minimal python/pytorch overhead in the system, simulation on the GPU, and the use of the SAPIEN parallel rendering system. Tasks that used to take hours to train can now take minutes. We further provide the most comprehensive range of GPU parallelized environments/tasks spanning 12 distinct domains including but not limited to mobile manipulation for tasks such as drawing, humanoids, and dextrous manipulation in realistic scenes designed by artists or real-world digital twins. In addition, millions of demonstration frames are provided from motion planning, RL, and teleoperation. ManiSkill3 also provides a comprehensive set of baselines that span popular RL and learning-from-demonstrations algorithms.
ACE: A Cross-Platform Visual-Exoskeletons System for Low-Cost Dexterous Teleoperation
Aug 21, 2024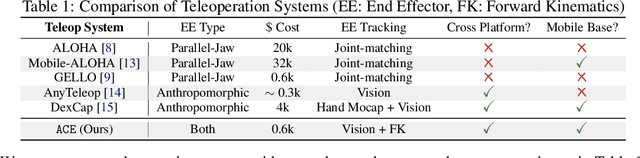

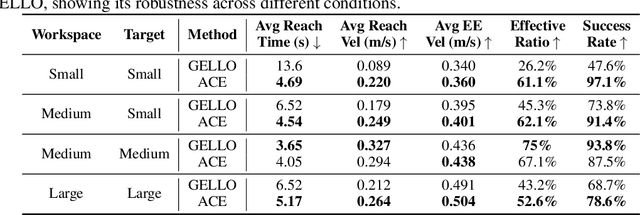

Learning from demonstrations has shown to be an effective approach to robotic manipulation, especially with the recently collected large-scale robot data with teleoperation systems. Building an efficient teleoperation system across diverse robot platforms has become more crucial than ever. However, there is a notable lack of cost-effective and user-friendly teleoperation systems for different end-effectors, e.g., anthropomorphic robot hands and grippers, that can operate across multiple platforms. To address this issue, we develop ACE, a cross-platform visual-exoskeleton system for low-cost dexterous teleoperation. Our system utilizes a hand-facing camera to capture 3D hand poses and an exoskeleton mounted on a portable base, enabling accurate real-time capture of both finger and wrist poses. Compared to previous systems, which often require hardware customization according to different robots, our single system can generalize to humanoid hands, arm-hands, arm-gripper, and quadruped-gripper systems with high-precision teleoperation. This enables imitation learning for complex manipulation tasks on diverse platforms.
Bunny-VisionPro: Real-Time Bimanual Dexterous Teleoperation for Imitation Learning
Jul 03, 2024Teleoperation is a crucial tool for collecting human demonstrations, but controlling robots with bimanual dexterous hands remains a challenge. Existing teleoperation systems struggle to handle the complexity of coordinating two hands for intricate manipulations. We introduce Bunny-VisionPro, a real-time bimanual dexterous teleoperation system that leverages a VR headset. Unlike previous vision-based teleoperation systems, we design novel low-cost devices to provide haptic feedback to the operator, enhancing immersion. Our system prioritizes safety by incorporating collision and singularity avoidance while maintaining real-time performance through innovative designs. Bunny-VisionPro outperforms prior systems on a standard task suite, achieving higher success rates and reduced task completion times. Moreover, the high-quality teleoperation demonstrations improve downstream imitation learning performance, leading to better generalizability. Notably, Bunny-VisionPro enables imitation learning with challenging multi-stage, long-horizon dexterous manipulation tasks, which have rarely been addressed in previous work. Our system's ability to handle bimanual manipulations while prioritizing safety and real-time performance makes it a powerful tool for advancing dexterous manipulation and imitation learning.
Part-Guided 3D RL for Sim2Real Articulated Object Manipulation
Apr 26, 2024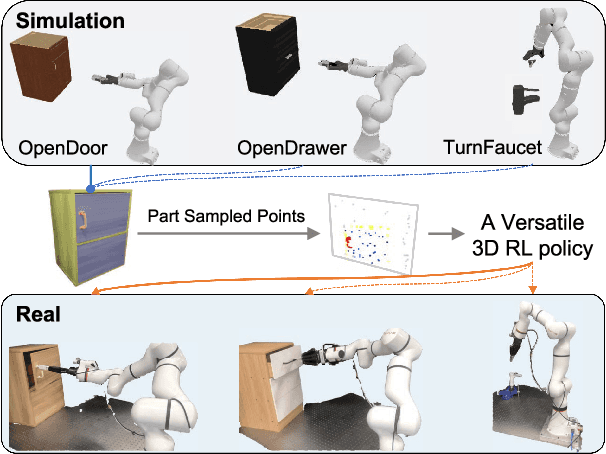

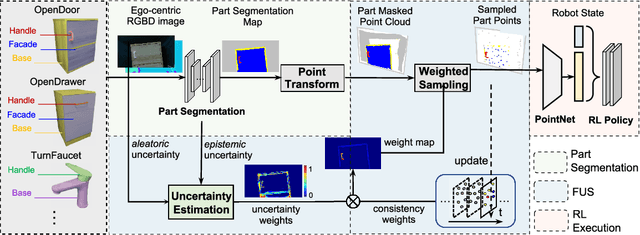

Manipulating unseen articulated objects through visual feedback is a critical but challenging task for real robots. Existing learning-based solutions mainly focus on visual affordance learning or other pre-trained visual models to guide manipulation policies, which face challenges for novel instances in real-world scenarios. In this paper, we propose a novel part-guided 3D RL framework, which can learn to manipulate articulated objects without demonstrations. We combine the strengths of 2D segmentation and 3D RL to improve the efficiency of RL policy training. To improve the stability of the policy on real robots, we design a Frame-consistent Uncertainty-aware Sampling (FUS) strategy to get a condensed and hierarchical 3D representation. In addition, a single versatile RL policy can be trained on multiple articulated object manipulation tasks simultaneously in simulation and shows great generalizability to novel categories and instances. Experimental results demonstrate the effectiveness of our framework in both simulation and real-world settings. Our code is available at https://github.com/THU-VCLab/Part-Guided-3D-RL-for-Sim2Real-Articulated-Object-Manipulation.
Sim2Real Manipulation on Unknown Objects with Tactile-based Reinforcement Learning
Mar 18, 2024Using tactile sensors for manipulation remains one of the most challenging problems in robotics. At the heart of these challenges is generalization: How can we train a tactile-based policy that can manipulate unseen and diverse objects? In this paper, we propose to perform Reinforcement Learning with only visual tactile sensing inputs on diverse objects in a physical simulator. By training with diverse objects in simulation, it enables the policy to generalize to unseen objects. However, leveraging simulation introduces the Sim2Real transfer problem. To mitigate this problem, we study different tactile representations and evaluate how each affects real-robot manipulation results after transfer. We conduct our experiments on diverse real-world objects and show significant improvements over baselines for the pivoting task. Our project page is available at https://tactilerl.github.io/.
CyberDemo: Augmenting Simulated Human Demonstration for Real-World Dexterous Manipulation
Mar 01, 2024



We introduce CyberDemo, a novel approach to robotic imitation learning that leverages simulated human demonstrations for real-world tasks. By incorporating extensive data augmentation in a simulated environment, CyberDemo outperforms traditional in-domain real-world demonstrations when transferred to the real world, handling diverse physical and visual conditions. Regardless of its affordability and convenience in data collection, CyberDemo outperforms baseline methods in terms of success rates across various tasks and exhibits generalizability with previously unseen objects. For example, it can rotate novel tetra-valve and penta-valve, despite human demonstrations only involving tri-valves. Our research demonstrates the significant potential of simulated human demonstrations for real-world dexterous manipulation tasks. More details can be found at https://cyber-demo.github.io
DexTouch: Learning to Seek and Manipulate Objects with Tactile Dexterity
Jan 23, 2024The sense of touch is an essential ability for skillfully performing a variety of tasks, providing the capacity to search and manipulate objects without relying on visual information. Extensive research has been conducted over time to apply these human tactile abilities to robots. In this paper, we introduce a multi-finger robot system designed to search for and manipulate objects using the sense of touch without relying on visual information. Randomly located target objects are searched using tactile sensors, and the objects are manipulated for tasks that mimic daily-life. The objective of the study is to endow robots with human-like tactile capabilities. To achieve this, binary tactile sensors are implemented on one side of the robot hand to minimize the Sim2Real gap. Training the policy through reinforcement learning in simulation and transferring the trained policy to the real environment, we demonstrate that object search and manipulation using tactile sensors is possible even in an environment without vision information. In addition, an ablation study was conducted to analyze the effect of tactile information on manipulative tasks. Our project page is available at https://lee-kangwon.github.io/dextouch/
Robot Synesthesia: In-Hand Manipulation with Visuotactile Sensing
Dec 04, 2023



Executing contact-rich manipulation tasks necessitates the fusion of tactile and visual feedback. However, the distinct nature of these modalities poses significant challenges. In this paper, we introduce a system that leverages visual and tactile sensory inputs to enable dexterous in-hand manipulation. Specifically, we propose Robot Synesthesia, a novel point cloud-based tactile representation inspired by human tactile-visual synesthesia. This approach allows for the simultaneous and seamless integration of both sensory inputs, offering richer spatial information and facilitating better reasoning about robot actions. The method, trained in a simulated environment and then deployed to a real robot, is applicable to various in-hand object rotation tasks. Comprehensive ablations are performed on how the integration of vision and touch can improve reinforcement learning and Sim2Real performance. Our project page is available at https://yingyuan0414.github.io/visuotactile/ .
GenSim: Generating Robotic Simulation Tasks via Large Language Models
Oct 02, 2023

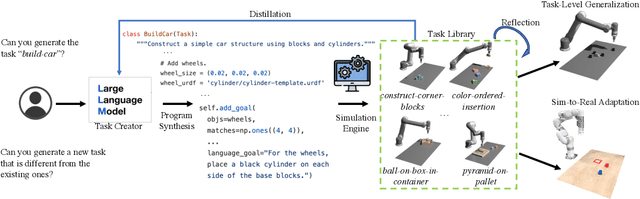
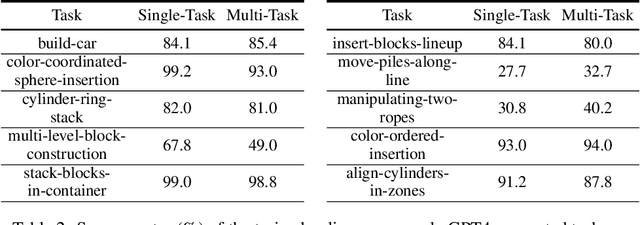
Collecting large amounts of real-world interaction data to train general robotic policies is often prohibitively expensive, thus motivating the use of simulation data. However, existing methods for data generation have generally focused on scene-level diversity (e.g., object instances and poses) rather than task-level diversity, due to the human effort required to come up with and verify novel tasks. This has made it challenging for policies trained on simulation data to demonstrate significant task-level generalization. In this paper, we propose to automatically generate rich simulation environments and expert demonstrations by exploiting a large language models' (LLM) grounding and coding ability. Our approach, dubbed GenSim, has two modes: goal-directed generation, wherein a target task is given to the LLM and the LLM proposes a task curriculum to solve the target task, and exploratory generation, wherein the LLM bootstraps from previous tasks and iteratively proposes novel tasks that would be helpful in solving more complex tasks. We use GPT4 to expand the existing benchmark by ten times to over 100 tasks, on which we conduct supervised finetuning and evaluate several LLMs including finetuned GPTs and Code Llama on code generation for robotic simulation tasks. Furthermore, we observe that LLMs-generated simulation programs can enhance task-level generalization significantly when used for multitask policy training. We further find that with minimal sim-to-real adaptation, the multitask policies pretrained on GPT4-generated simulation tasks exhibit stronger transfer to unseen long-horizon tasks in the real world and outperform baselines by 25%. See the project website (https://liruiw.github.io/gensim) for code, demos, and videos.