 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Prior Meets Local Consistency: Dual-Memory Augmented Vision-Language-Action Model for Efficient Robotic Manipulation
Feb 22, 2026Hierarchical Vision-Language-Action (VLA) models have rapidly become a dominant paradigm for robotic manipulation. It typically comprising a Vision-Language backbone for perception and understanding, together with a generative policy for action generation. However, its performance is increasingly bottlenecked by the action generation proceess. (i) Low inference efficiency. A pronounced distributional gap between isotropic noise priors and target action distributions, which increases denoising steps and the incidence of infeasible samples. (ii) Poor robustness. Existing policies condition solely on the current observation, neglecting the constraint of history sequence and thus lacking awareness of task progress and temporal consistency. To address these issues, we introduce OptimusVLA, a dual-memory VLA framework with Global Prior Memory (GPM) and Local Consistency Memory (LCM). GPM replaces Gaussian noise with task-level priors retrieved from semantically similar trajectories, thereby shortening the generative path and reducing the umber of function evaluations (NFE). LCM dynamically models executed action sequence to infer task progress and injects a learned consistency constraint that enforces temporal coherence and smoothness of trajectory. Across three simulation benchmarks, OptimusVLA consistently outperforms strong baselines: it achieves 98.6% average success rate on LIBERO, improves over pi_0 by 13.5% on CALVIN, and attains 38% average success rate on RoboTwin 2.0 Hard. In Real-World evaluation, OptimusVLA ranks best on Generalization and Long-horizon suites, surpassing pi_0 by 42.9% and 52.4%, respectively, while delivering 2.9x inference speedup.
OmniEVA: Embodied Versatile Planner via Task-Adaptive 3D-Grounded and Embodiment-aware Reasoning
Sep 11, 2025Recent advances in multimodal large language models (MLLMs) have opened new opportunities for embodied intelligence, enabling multimodal understanding, reasoning, and interaction, as well as continuous spatial decision-making. Nevertheless, current MLLM-based embodied systems face two critical limitations. First, Geometric Adaptability Gap: models trained solely on 2D inputs or with hard-coded 3D geometry injection suffer from either insufficient spatial information or restricted 2D generalization, leading to poor adaptability across tasks with diverse spatial demands. Second, Embodiment Constraint Gap: prior work often neglects the physical constraints and capacities of real robots, resulting in task plans that are theoretically valid but practically infeasible.To address these gaps, we introduce OmniEVA -- an embodied versatile planner that enables advanced embodied reasoning and task planning through two pivotal innovations: (1) a Task-Adaptive 3D Grounding mechanism, which introduces a gated router to perform explicit selective regulation of 3D fusion based on contextual requirements, enabling context-aware 3D grounding for diverse embodied tasks. (2) an Embodiment-Aware Reasoning framework that jointly incorporates task goals and embodiment constraints into the reasoning loop, resulting in planning decisions that are both goal-directed and executable. Extensive experimental results demonstrate that OmniEVA not only achieves state-of-the-art general embodied reasoning performance, but also exhibits a strong ability across a wide range of downstream scenarios. Evaluations of a suite of proposed embodied benchmarks, including both primitive and composite tasks, confirm its robust and versatile planning capabilities. Project page: https://omnieva.github.io
GAP-RL: Grasps As Points for RL Towards Dynamic Object Grasping
Oct 04, 2024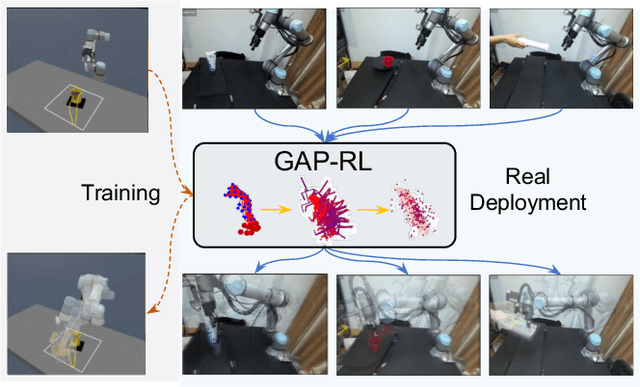
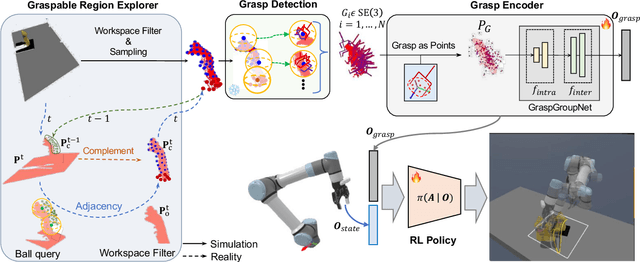
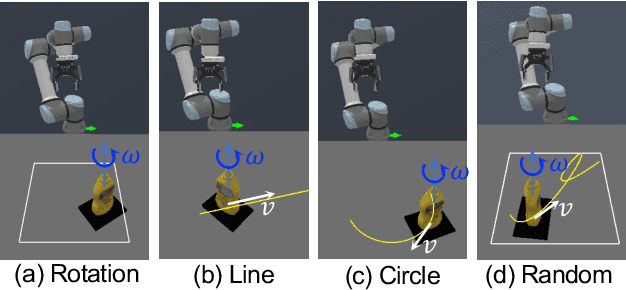
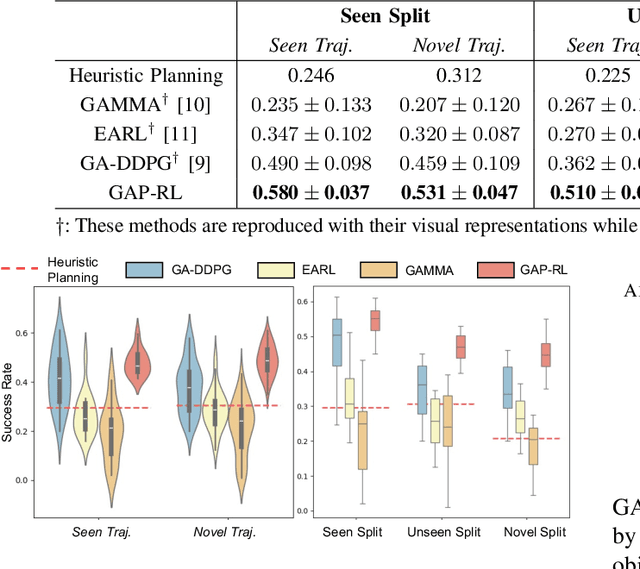
Dynamic grasping of moving objects in complex, continuous motion scenarios remains challenging. Reinforcement Learning (RL) has been applied in various robotic manipulation tasks, benefiting from its closed-loop property. However, existing RL-based methods do not fully explore the potential for enhancing visual representations. In this letter, we propose a novel framework called Grasps As Points for RL (GAP-RL) to effectively and reliably grasp moving objects. By implementing a fast region-based grasp detector, we build a Grasp Encoder by transforming 6D grasp poses into Gaussian points and extracting grasp features as a higher-level abstraction than the original object point features. Additionally, we develop a Graspable Region Explorer for real-world deployment, which searches for consistent graspable regions, enabling smoother grasp generation and stable policy execution. To assess the performance fairly, we construct a simulated dynamic grasping benchmark involving objects with various complex motions. Experiment results demonstrate that our method effectively generalizes to novel objects and unseen dynamic motions compared to other baselines. Real-world experiments further validate the framework's sim-to-real transferability.
Target-Oriented Object Grasping via Multimodal Human Guidance
Aug 20, 2024



In the context of human-robot interaction and collaboration scenarios, robotic grasping still encounters numerous challenges. Traditional grasp detection methods generally analyze the entire scene to predict grasps, leading to redundancy and inefficiency. In this work, we reconsider 6-DoF grasp detection from a target-referenced perspective and propose a Target-Oriented Grasp Network (TOGNet). TOGNet specifically targets local, object-agnostic region patches to predict grasps more efficiently. It integrates seamlessly with multimodal human guidance, including language instructions, pointing gestures, and interactive clicks. Thus our system comprises two primary functional modules: a guidance module that identifies the target object in 3D space and TOGNet, which detects region-focal 6-DoF grasps around the target, facilitating subsequent motion planning. Through 50 target-grasping simulation experiments in cluttered scenes, our system achieves a success rate improvement of about 13.7%. In real-world experiments, we demonstrate that our method excels in various target-oriented grasping scenarios.
Region-aware Grasp Framework with Normalized Grasp Space for 6-DoF Grasping in Cluttered Scene
Jun 03, 2024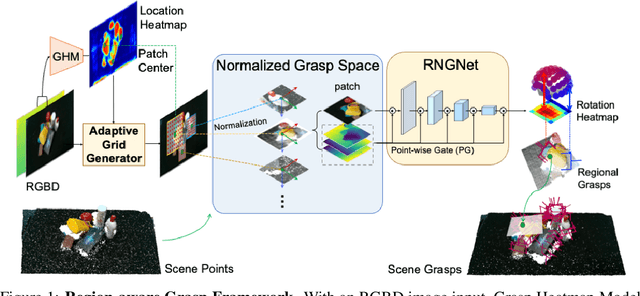
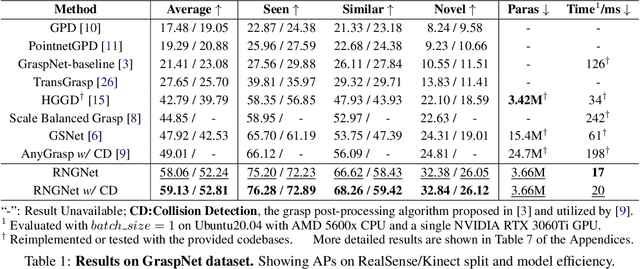
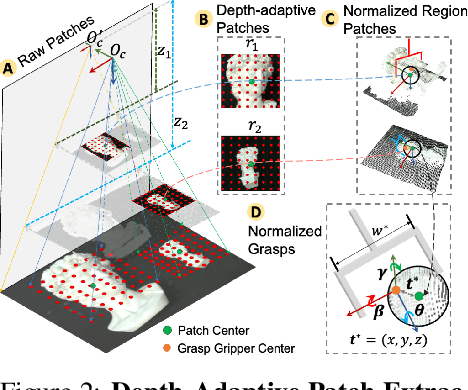

Regional geometric information is crucial for determining grasp poses. A series of region-based methods succeed in extracting regional features and enhancing grasp detection quality. However, faced with a cluttered scene with multiple objects and potential collision, the definition of the grasp-relevant region remains inconsistent among methods, and the relationship between grasps and regional spaces remains incompletely investigated. In this paper, from a novel region-aware and grasp-centric viewpoint, we propose Normalized Grasp Space (NGS), unifying the grasp representation within a normalized regional space. The relationship among the grasp widths, region scales, and gripper sizes is considered and empowers our method to generalize to grippers and scenes with different scales. Leveraging the characteristics of the NGS, we find that 2D CNNs are surprisingly underestimated for complicated 6-DoF grasp detection tasks in clutter scenes and build a highly efficient Region-aware Normalized Grasp Network (RNGNet). Experiments conducted on the public benchmark show that our method achieves the best grasp detection results compared to the previous state-of-the-arts while attaining a real-time inference speed of approximately 50 FPS. Real-world cluttered scene clearance experiments underscore the effectiveness of our method with a higher success rate than other methods. Further human-to-robot handover and moving object grasping experiments demonstrate the potential of our proposed method for closed-loop grasping in dynamic scenarios.
Part-Guided 3D RL for Sim2Real Articulated Object Manipulation
Apr 26, 2024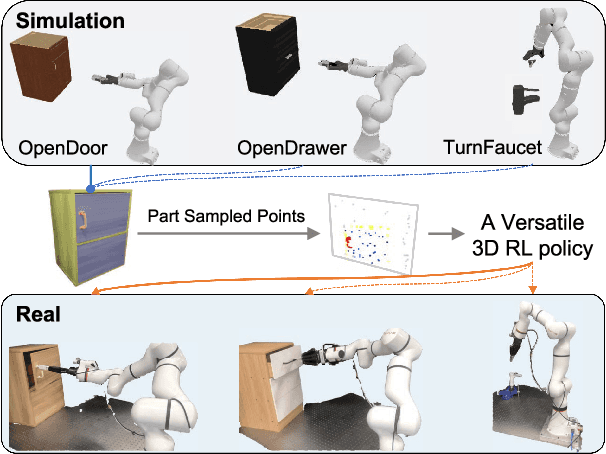

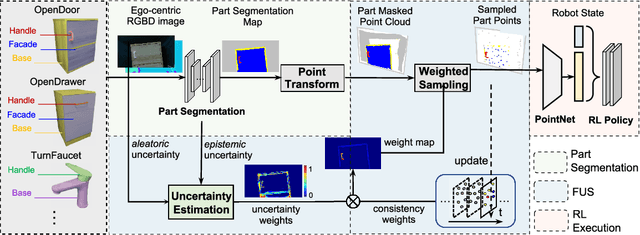

Manipulating unseen articulated objects through visual feedback is a critical but challenging task for real robots. Existing learning-based solutions mainly focus on visual affordance learning or other pre-trained visual models to guide manipulation policies, which face challenges for novel instances in real-world scenarios. In this paper, we propose a novel part-guided 3D RL framework, which can learn to manipulate articulated objects without demonstrations. We combine the strengths of 2D segmentation and 3D RL to improve the efficiency of RL policy training. To improve the stability of the policy on real robots, we design a Frame-consistent Uncertainty-aware Sampling (FUS) strategy to get a condensed and hierarchical 3D representation. In addition, a single versatile RL policy can be trained on multiple articulated object manipulation tasks simultaneously in simulation and shows great generalizability to novel categories and instances. Experimental results demonstrate the effectiveness of our framework in both simulation and real-world settings. Our code is available at https://github.com/THU-VCLab/Part-Guided-3D-RL-for-Sim2Real-Articulated-Object-Manipulation.
Efficient Heatmap-Guided 6-Dof Grasp Detection in Cluttered Scenes
Mar 27, 2024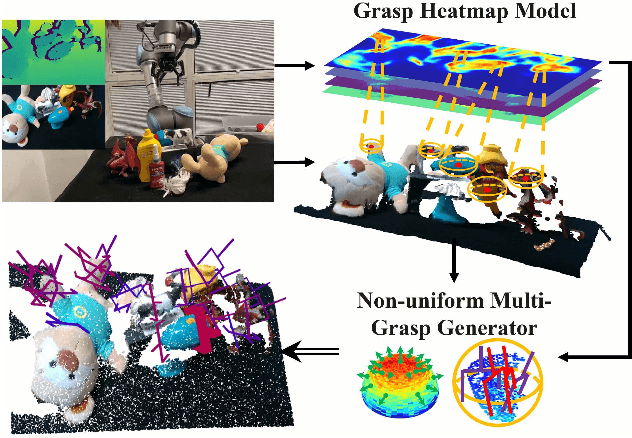
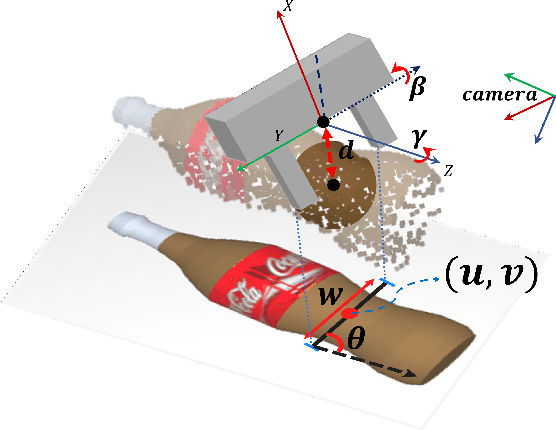
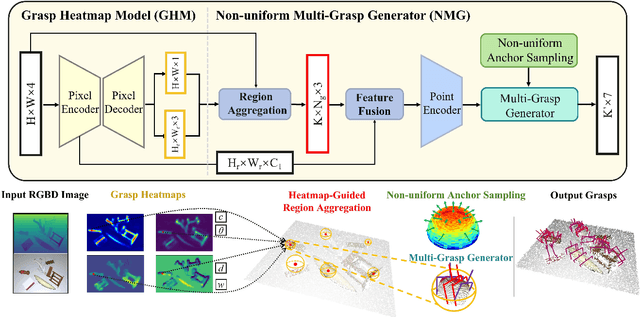
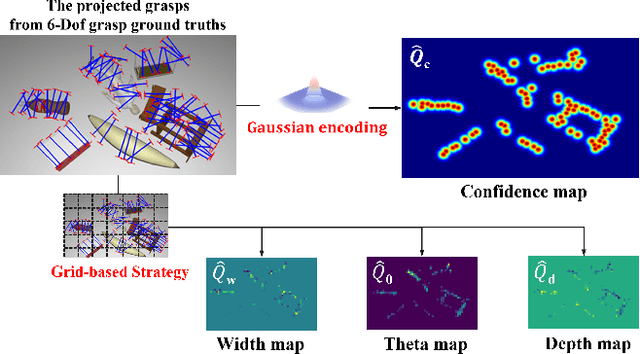
Fast and robust object grasping in clutter is a crucial component of robotics. Most current works resort to the whole observed point cloud for 6-Dof grasp generation, ignoring the guidance information excavated from global semantics, thus limiting high-quality grasp generation and real-time performance. In this work, we show that the widely used heatmaps are underestimated in the efficiency of 6-Dof grasp generation. Therefore, we propose an effective local grasp generator combined with grasp heatmaps as guidance, which infers in a global-to-local semantic-to-point way. Specifically, Gaussian encoding and the grid-based strategy are applied to predict grasp heatmaps as guidance to aggregate local points into graspable regions and provide global semantic information. Further, a novel non-uniform anchor sampling mechanism is designed to improve grasp accuracy and diversity. Benefiting from the high-efficiency encoding in the image space and focusing on points in local graspable regions, our framework can perform high-quality grasp detection in real-time and achieve state-of-the-art results. In addition, real robot experiments demonstrate the effectiveness of our method with a success rate of 94% and a clutter completion rate of 100%. Our code is available at https://github.com/THU-VCLab/HGGD.
Rethinking 6-Dof Grasp Detection: A Flexible Framework for High-Quality Grasping
Mar 22, 2024Robotic grasping is a primitive skill for complex tasks and is fundamental to intelligence. For general 6-Dof grasping, most previous methods directly extract scene-level semantic or geometric information, while few of them consider the suitability for various downstream applications, such as target-oriented grasping. Addressing this issue, we rethink 6-Dof grasp detection from a grasp-centric view and propose a versatile grasp framework capable of handling both scene-level and target-oriented grasping. Our framework, FlexLoG, is composed of a Flexible Guidance Module and a Local Grasp Model. Specifically, the Flexible Guidance Module is compatible with both global (e.g., grasp heatmap) and local (e.g., visual grounding) guidance, enabling the generation of high-quality grasps across various tasks. The Local Grasp Model focuses on object-agnostic regional points and predicts grasps locally and intently. Experiment results reveal that our framework achieves over 18% and 23% improvement on unseen splits of the GraspNet-1Billion Dataset. Furthermore, real-world robotic tests in three distinct settings yield a 95% success rate.
Category-Agnostic Pose Estimation for Point Clouds
Mar 12, 2024



The goal of object pose estimation is to visually determine the pose of a specific object in the RGB-D input. Unfortunately, when faced with new categories, both instance-based and category-based methods are unable to deal with unseen objects of unseen categories, which is a challenge for pose estimation. To address this issue, this paper proposes a method to introduce geometric features for pose estimation of point clouds without requiring category information. The method is based only on the patch feature of the point cloud, a geometric feature with rotation invariance. After training without category information, our method achieves as good results as other category-based methods. Our method successfully achieved pose annotation of no category information instances on the CAMERA25 dataset and ModelNet40 dataset.
GenH2R: Learning Generalizable Human-to-Robot Handover via Scalable Simulation, Demonstration, and Imitation
Jan 01, 2024This paper presents GenH2R, a framework for learning generalizable vision-based human-to-robot (H2R) handover skills. The goal is to equip robots with the ability to reliably receive objects with unseen geometry handed over by humans in various complex trajectories. We acquire such generalizability by learning H2R handover at scale with a comprehensive solution including procedural simulation assets creation, automated demonstration generation, and effective imitation learning. We leverage large-scale 3D model repositories, dexterous grasp generation methods, and curve-based 3D animation to create an H2R handover simulation environment named \simabbns, surpassing the number of scenes in existing simulators by three orders of magnitude. We further introduce a distillation-friendly demonstration generation method that automatically generates a million high-quality demonstrations suitable for learning. Finally, we present a 4D imitation learning method augmented by a future forecasting objective to distill demonstrations into a visuo-motor handover policy. Experimental evaluations in both simulators and the real world demonstrate significant improvements (at least +10\% success rate) over baselines in all cases. The project page is https://GenH2R.github.io/.