 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMG-Grasp: Metric-Scale Geometric 6-DoF Grasping Framework with Sparse RGB Observations
Mar 17, 2026Single-view RGB-D grasp detection remains a com- mon choice in 6-DoF robotic grasping systems, which typically requires a depth sensor. While RGB-only 6-DoF grasp methods has been studied recently, their inaccurate geometric repre- sentation is not directly suitable for physically reliable robotic manipulation, thereby hindering reliable grasp generation. To address these limitations, we propose MG-Grasp, a novel depth- free 6-DoF grasping framework that achieves high-quality object grasping. Leveraging two-view 3D foundation model with camera intrinsic/extrinsic, our method reconstructs metric- scale and multi-view consistent dense point clouds from sparse RGB images and generates stable 6-DoF grasp. Experiments on GraspNet-1Billion dataset and real world demonstrate that MG-Grasp achieves state-of-the-art (SOTA) grasp performance among RGB-based 6-DoF grasping methods.
Understanding Generalizability of Diffusion Models Requires Rethinking the Hidden Gaussian Structure
Oct 31, 2024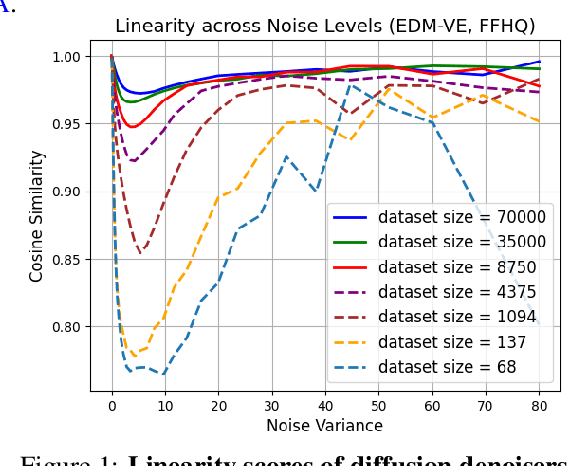
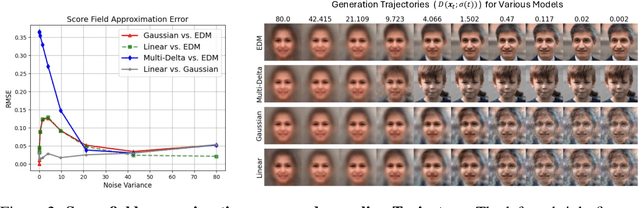

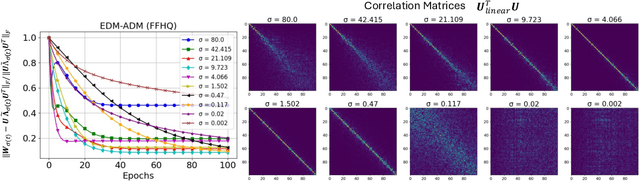
In this work, we study the generalizability of diffusion models by looking into the hidden properties of the learned score functions, which are essentially a series of deep denoisers trained on various noise levels. We observe that as diffusion models transition from memorization to generalization, their corresponding nonlinear diffusion denoisers exhibit increasing linearity. This discovery leads us to investigate the linear counterparts of the nonlinear diffusion models, which are a series of linear models trained to match the function mappings of the nonlinear diffusion denoisers. Surprisingly, these linear denoisers are approximately the optimal denoisers for a multivariate Gaussian distribution characterized by the empirical mean and covariance of the training dataset. This finding implies that diffusion models have the inductive bias towards capturing and utilizing the Gaussian structure (covariance information) of the training dataset for data generation. We empirically demonstrate that this inductive bias is a unique property of diffusion models in the generalization regime, which becomes increasingly evident when the model's capacity is relatively small compared to the training dataset size. In the case that the model is highly overparameterized, this inductive bias emerges during the initial training phases before the model fully memorizes its training data. Our study provides crucial insights into understanding the notable strong generalization phenomenon recently observed in real-world diffusion models.
Diffusion-Based Depth Inpainting for Transparent and Reflective Objects
Oct 11, 2024



Transparent and reflective objects, which are common in our everyday lives, present a significant challenge to 3D imaging techniques due to their unique visual and optical properties. Faced with these types of objects, RGB-D cameras fail to capture the real depth value with their accurate spatial information. To address this issue, we propose DITR, a diffusion-based Depth Inpainting framework specifically designed for Transparent and Reflective objects. This network consists of two stages, including a Region Proposal stage and a Depth Inpainting stage. DITR dynamically analyzes the optical and geometric depth loss and inpaints them automatically. Furthermore, comprehensive experimental results demonstrate that DITR is highly effective in depth inpainting tasks of transparent and reflective objects with robust adaptability.
GAP-RL: Grasps As Points for RL Towards Dynamic Object Grasping
Oct 04, 2024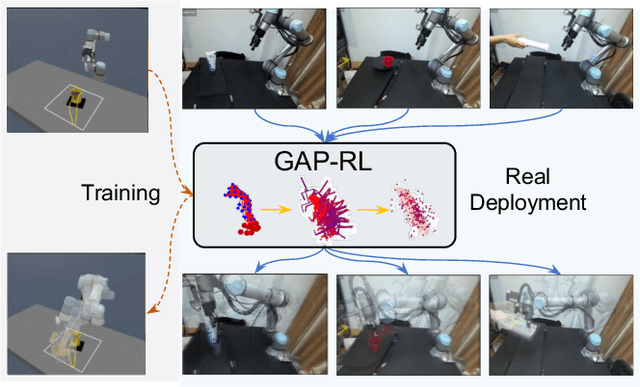
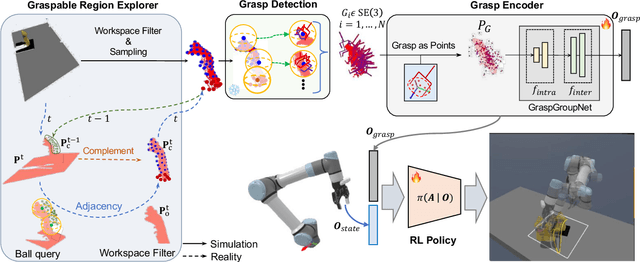
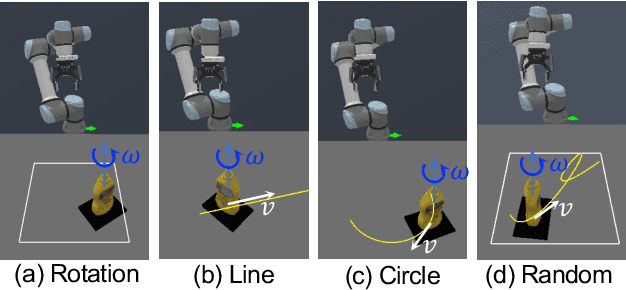
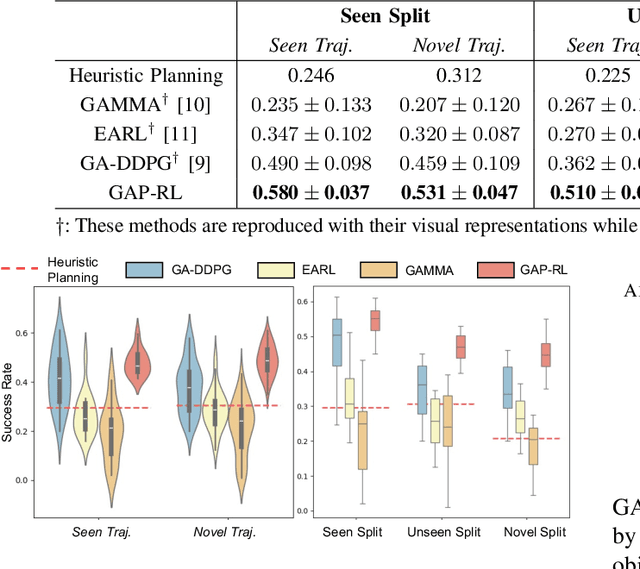
Dynamic grasping of moving objects in complex, continuous motion scenarios remains challenging. Reinforcement Learning (RL) has been applied in various robotic manipulation tasks, benefiting from its closed-loop property. However, existing RL-based methods do not fully explore the potential for enhancing visual representations. In this letter, we propose a novel framework called Grasps As Points for RL (GAP-RL) to effectively and reliably grasp moving objects. By implementing a fast region-based grasp detector, we build a Grasp Encoder by transforming 6D grasp poses into Gaussian points and extracting grasp features as a higher-level abstraction than the original object point features. Additionally, we develop a Graspable Region Explorer for real-world deployment, which searches for consistent graspable regions, enabling smoother grasp generation and stable policy execution. To assess the performance fairly, we construct a simulated dynamic grasping benchmark involving objects with various complex motions. Experiment results demonstrate that our method effectively generalizes to novel objects and unseen dynamic motions compared to other baselines. Real-world experiments further validate the framework's sim-to-real transferability.
Target-Oriented Object Grasping via Multimodal Human Guidance
Aug 20, 2024



In the context of human-robot interaction and collaboration scenarios, robotic grasping still encounters numerous challenges. Traditional grasp detection methods generally analyze the entire scene to predict grasps, leading to redundancy and inefficiency. In this work, we reconsider 6-DoF grasp detection from a target-referenced perspective and propose a Target-Oriented Grasp Network (TOGNet). TOGNet specifically targets local, object-agnostic region patches to predict grasps more efficiently. It integrates seamlessly with multimodal human guidance, including language instructions, pointing gestures, and interactive clicks. Thus our system comprises two primary functional modules: a guidance module that identifies the target object in 3D space and TOGNet, which detects region-focal 6-DoF grasps around the target, facilitating subsequent motion planning. Through 50 target-grasping simulation experiments in cluttered scenes, our system achieves a success rate improvement of about 13.7%. In real-world experiments, we demonstrate that our method excels in various target-oriented grasping scenarios.