 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Forcing Distillation: Restoring Diversity and Fidelity in Few-Step Video Generation
Jun 16, 2026Recent progress has shown promise in distilling multi-step video diffusion models into efficient few-step students. Among them, Distribution Matching Distillation (DMD) and its successor DMD2 achieved strong generation quality and fast convergence. However, due to the nature of the reverse Kullback--Leibler (KL) objective, these methods exhibit two persistent failure modes: a substantial drop in sample diversity, and visibly over-saturated outputs that deviate from real-video appearance. In this work, we propose Data-Forcing Distillation (DFD), a simple post-training framework that restores diversity and fidelity in DMD with only a single-line of code change. At its core is the teacher score discrepancy to guide the student toward the real-data distribution, pulling it to missing modes (mitigating mode collapse) and away from problematic modes absent in real data (avoiding over-saturation). We provide an in-depth theoretical analysis of our framework and validate our approach on text-to-video, image-to-video, and autoregressive video generation. With only 100--300 steps of finetuning, DFD effectively restores diversity and fidelity on both Wan2.1-1.3B and Cosmos-Predict2.5-2B model, resolving the over-saturation artifacts with significantly better video dynamics and appearance, and even outperforms the teacher model.
Evaluating the Representation Space of Diffusion Models via Self-Supervised Principles
Jun 08, 2026Diffusion models have demonstrated remarkable generative capabilities and have also emerged as powerful self-supervised representation learners, yet the connection between these two abilities remains less explored. Drawing inspiration from self-supervised learning (SSL), we introduce a framework for jointly evaluating the representation and generation capabilities of diffusion models. Specifically, we decompose features into invariant and residual components and derive the Invariant Contamination Ratio (ICR), a Fisher-based metric that quantifies how residual variation contaminates invariant signal in feature space. We use this framework to analyze both discriminative and generative behavior of diffusion models. On the representation side, we find that invariance peaks at intermediate noise levels, which also yield the best downstream classification performance. On the generative side, we study how training transitions from genuine generalization to memorization in data-limited regimes, and show that ICR serves as a sensitive training-time indicator of early learning: increasing residual energy along Fisher directions marks the onset of memorization, detectable from training features alone without external evaluators or held-out test sets. Overall, our results show that diffusion models can be monitored from a self-supervised perspective through the geometry of their learned representations.
VoLo: A Physical Orchestrator for Open-Vocabulary Long-Horizon Manipulation
Jun 05, 2026Open-vocabulary long-horizon manipulation requires robots to reason over flexible instructions and complex multi-object scenes while adaptively planning, executing, monitoring, and recovering from failures. We address these demands with a closed agent loop in which a VLM orchestrates heterogeneous robot capabilities as interruptible tools. Unlike in virtual AI agents, the timing of decisions, actions and tool calls is important in a physical world that does not pause for reasoning. We refer to this setting as Physical Orchestration, and propose VoLoAgent, a VLM that plans, monitors, and recovers by treating a VLA/WAM as an interruptible tool it steers mid-rollout alongside vision models and action primitives. To evaluate these long-horizon capabilities, we introduce RoboVoLo, a high-fidelity benchmark for open-vocabulary long-horizon manipulation across common sense, memory/state tracking, complex references, and world knowledge, with both task-level success and failure-mode diagnostics. Experiments show VoLoAgent substantially outperforms single VLA/VLM or tool-based systems, with validation on real-robot experiments. Project page: https://chicychen.github.io/VoLo/
The Effect of Training Task Diversity on In-Context Learning through the Lens of Low-Dimensional Subspaces
Jun 05, 2026The transformer's emergent ability to perform in-context learning (ICL) has sparked a wide range of studies designed to understand its underlying mechanisms. Existing works often study how training task diversity, defined either as the number of ICL training task vectors or as the number of function classes from which the task vectors are drawn, shapes both the learning dynamics and generalization capabilities of ICL. While both definitions have uncovered many interesting phenomena, many observations under the latter definition remain theoretically unexplained. This paper presents a minimal analytical model under which these phenomena provably emerge from the properties of the training data. By modeling the training task vectors as a mixture of low-rank Gaussians, we show how training task diversity, defined by the number of non-overlapping columns between subspaces that parameterize the covariance matrices, improves both the generalization and optimization trajectory of ICL with linear attention. In particular, we show that our model can explain (i) why training with task diversity shortens the ICL plateau and (ii) why ICL appears to achieve out-of-distribution generalization. We conclude by empirically demonstrating how our results extend to nonlinear transformers and nonlinear function classes. Overall, our work presents a tractable framework to unify existing observations.
ForcingDAS: Unified and Robust Data Assimilation via Diffusion Forcing
May 14, 2026Data assimilation (DA) estimates the state of an evolving dynamical system from noisy, partial observations, and is widely used in scientific simulation as well as weather and climate science. In practice, filtering methods rely on frame-to-frame transition models. However, these models are fragile when observations are non-Markovian (when they form only a partial slice of a higher-dimensional latent state as in real-world weather data): they tend to accumulate errors over long horizons. At the same time, learned DA methods typically commit to a single regime, either filtering (nowcasting, real-time forecasting) or smoothing (retrospective reanalysis), which splits what should be a shared prior across application-specific pipelines. To address both issues, we introduce ForcingDAS, a unified and robust DA framework. Built on Diffusion Forcing with an independent noise level assigned to each frame, ForcingDAS learns a joint-trajectory prior instead of frame-to-frame transitions. This allows it to capture long-horizon temporal dependencies and reduce error accumulation. In addition, the same trained model spans the full filtering to smoothing spectrum at inference time. Specifically, nowcasting, fixed-lag smoothing, and batch reanalysis are selected through the inference schedule alone, without retraining. We evaluate ForcingDAS on 2D Navier-Stokes vorticity, precipitation nowcasting, and global atmospheric state estimation. Across all settings, a single model is competitive with or outperforms both learned and classical baselines that are specialized for individual regimes, with the largest gains observed on real-world weather benchmarks.
Subspace Control: Turning Constrained Model Steering into Controllable Spectral Optimization
Apr 05, 2026Foundation models, such as large language models (LLMs), are powerful but often require customization before deployment to satisfy practical constraints such as safety, privacy, and task-specific requirements, leading to "constrained" optimization problems for model steering and adaptation. However, solving such problems remains largely underexplored and is particularly challenging due to interference between the primary objective and constraint objectives during optimization. In this paper, we propose a subspace control framework for constrained model training. Specifically, (i) we first analyze, from a model merging perspective, how spectral cross-task interference arises and show that it can be resolved via a one-shot solution that orthogonalizes the merged subspace; (ii) we establish a connection between this solution and gradient orthogonalization in the spectral optimizer Muon; and (iii) building on these insights, we introduce SIFT (spectral interference-free training), which leverages a localization scheme to selectively intervene during optimization, enabling controllable updates that mitigate objective-constraint conflicts. We evaluate SIFT across four representative applications: (a) machine unlearning, (b) safety alignment, (c) text-to-speech adaptation, and (d) hallucination mitigation. Compared to both control-based and control-free baselines, SIFT consistently achieves substantial and robust performance improvements across all tasks. Code is available at https://github.com/OPTML-Group/SIFT.
MCLR: Improving Conditional Modeling in Visual Generative Models via Inter-Class Likelihood-Ratio Maximization and Establishing the Equivalence between Classifier-Free Guidance and Alignment Objectives
Mar 23, 2026Diffusion models have achieved state-of-the-art performance in generative modeling, but their success often relies heavily on classifier-free guidance (CFG), an inference-time heuristic that modifies the sampling trajectory. From a theoretical perspective, diffusion models trained with standard denoising score matching (DSM) are expected to recover the target data distribution, raising the question of why inference-time guidance is necessary in practice. In this work, we ask whether the DSM training objective can be modified in a principled manner such that standard reverse-time sampling, without inference-time guidance, yields effects comparable to CFG. We identify insufficient inter-class separation as a key limitation of standard diffusion models. To address this, we propose MCLR, a principled alignment objective that explicitly maximizes inter-class likelihood-ratios during training. Models fine-tuned with MCLR exhibit CFG-like improvements under standard sampling, achieving comparable qualitative and quantitative gains without requiring inference-time guidance. Beyond empirical benefits, we provide a theoretical result showing that the CFG-guided score is exactly the optimal solution to a weighted MCLR objective. This establishes a formal equivalence between classifier-free guidance and alignment-based objectives, offering a mechanistic interpretation of CFG.
Emergent Low-Rank Training Dynamics in MLPs with Smooth Activations
Feb 05, 2026Recent empirical evidence has demonstrated that the training dynamics of large-scale deep neural networks occur within low-dimensional subspaces. While this has inspired new research into low-rank training, compression, and adaptation, theoretical justification for these dynamics in nonlinear networks remains limited. %compared to deep linear settings. To address this gap, this paper analyzes the learning dynamics of multi-layer perceptrons (MLPs) under gradient descent (GD). We demonstrate that the weight dynamics concentrate within invariant low-dimensional subspaces throughout training. Theoretically, we precisely characterize these invariant subspaces for two-layer networks with smooth nonlinear activations, providing insight into their emergence. Experimentally, we validate that this phenomenon extends beyond our theoretical assumptions. Leveraging these insights, we empirically show there exists a low-rank MLP parameterization that, when initialized within the appropriate subspaces, matches the classification performance of fully-parameterized counterparts on a variety of classification tasks.
Generalization of Diffusion Models Arises with a Balanced Representation Space
Dec 24, 2025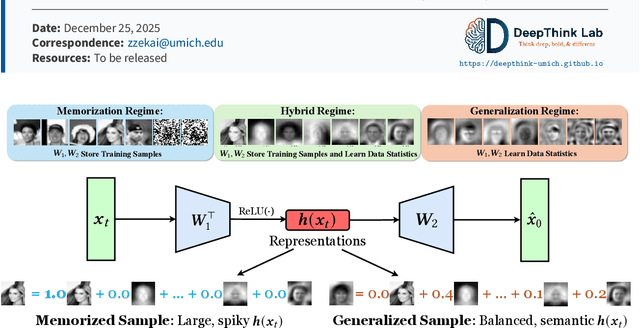
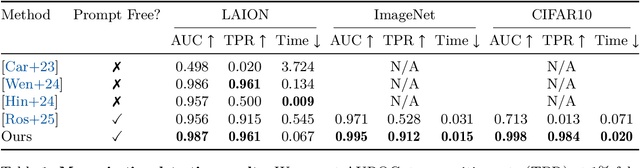
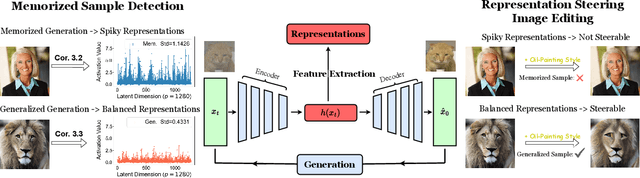

Diffusion models excel at generating high-quality, diverse samples, yet they risk memorizing training data when overfit to the training objective. We analyze the distinctions between memorization and generalization in diffusion models through the lens of representation learning. By investigating a two-layer ReLU denoising autoencoder (DAE), we prove that (i) memorization corresponds to the model storing raw training samples in the learned weights for encoding and decoding, yielding localized "spiky" representations, whereas (ii) generalization arises when the model captures local data statistics, producing "balanced" representations. Furthermore, we validate these theoretical findings on real-world unconditional and text-to-image diffusion models, demonstrating that the same representation structures emerge in deep generative models with significant practical implications. Building on these insights, we propose a representation-based method for detecting memorization and a training-free editing technique that allows precise control via representation steering. Together, our results highlight that learning good representations is central to novel and meaningful generative modeling.
Coarse-to-Fine Hierarchical Alignment for UAV-based Human Detection using Diffusion Models
Dec 15, 2025Training object detectors demands extensive, task-specific annotations, yet this requirement becomes impractical in UAV-based human detection due to constantly shifting target distributions and the scarcity of labeled images. As a remedy, synthetic simulators are adopted to generate annotated data, with a low annotation cost. However, the domain gap between synthetic and real images hinders the model from being effectively applied to the target domain. Accordingly, we introduce Coarse-to-Fine Hierarchical Alignment (CFHA), a three-stage diffusion-based framework designed to transform synthetic data for UAV-based human detection, narrowing the domain gap while preserving the original synthetic labels. CFHA explicitly decouples global style and local content domain discrepancies and bridges those gaps using three modules: (1) Global Style Transfer -- a diffusion model aligns color, illumination, and texture statistics of synthetic images to the realistic style, using only a small real reference set; (2) Local Refinement -- a super-resolution diffusion model is used to facilitate fine-grained and photorealistic details for the small objects, such as human instances, preserving shape and boundary integrity; (3) Hallucination Removal -- a module that filters out human instances whose visual attributes do not align with real-world data to make the human appearance closer to the target distribution. Extensive experiments on public UAV Sim2Real detection benchmarks demonstrate that our methods significantly improve the detection accuracy compared to the non-transformed baselines. Specifically, our method achieves up to $+14.1$ improvement of mAP50 on Semantic-Drone benchmark. Ablation studies confirm the complementary roles of the global and local stages and highlight the importance of hierarchical alignment. The code is released at \href{https://github.com/liwd190019/CFHA}{this url}.