 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWords at Play: Benchmarking Audio Pun Understanding in Large Audio-Language Models
Mar 19, 2026Puns represent a typical linguistic phenomenon that exploits polysemy and phonetic ambiguity to generate humour, posing unique challenges for natural language understanding. Within pun research, audio plays a central role in human communication except text and images, while datasets and systematic resources for spoken puns remain scarce, leaving this crucial modality largely underexplored. In this paper, we present APUN-Bench, the first benchmark dedicated to evaluating large audio language models (LALMs) on audio pun understanding. Our benchmark contains 4,434 audio samples annotated across three stages: pun recognition, pun word location and pun meaning inference. We conduct a deep analysis of APUN-Bench by systematically evaluating 10 state-of-the-art LALMs, uncovering substantial performance gaps in recognizing, localizing, and interpreting audio puns. This analysis reveals key challenges, such as positional biases in audio pun location and error cases in meaning inference, offering actionable insights for advancing humour-aware audio intelligence.
Understanding Generalization in Diffusion Models via Probability Flow Distance
May 26, 2025Diffusion models have emerged as a powerful class of generative models, capable of producing high-quality samples that generalize beyond the training data. However, evaluating this generalization remains challenging: theoretical metrics are often impractical for high-dimensional data, while no practical metrics rigorously measure generalization. In this work, we bridge this gap by introducing probability flow distance ($\texttt{PFD}$), a theoretically grounded and computationally efficient metric to measure distributional generalization. Specifically, $\texttt{PFD}$ quantifies the distance between distributions by comparing their noise-to-data mappings induced by the probability flow ODE. Moreover, by using $\texttt{PFD}$ under a teacher-student evaluation protocol, we empirically uncover several key generalization behaviors in diffusion models, including: (1) scaling behavior from memorization to generalization, (2) early learning and double descent training dynamics, and (3) bias-variance decomposition. Beyond these insights, our work lays a foundation for future empirical and theoretical studies on generalization in diffusion models.
Making Small Language Models Efficient Reasoners: Intervention, Supervision, Reinforcement
May 14, 2025Recent research enhances language model reasoning by scaling test-time compute via longer chain-of-thought traces. This often improves accuracy but also introduces redundancy and high computational cost, especially for small language models distilled with supervised fine-tuning (SFT). In this work, we propose new algorithms to improve token-efficient reasoning with small-scale models by effectively trading off accuracy and computation. We first show that the post-SFT model fails to determine the optimal stopping point of the reasoning process, resulting in verbose and repetitive outputs. Verbosity also significantly varies across wrong vs correct responses. To address these issues, we propose two solutions: (1) Temperature scaling (TS) to control the stopping point for the thinking phase and thereby trace length, and (2) TLDR: a length-regularized reinforcement learning method based on GRPO that facilitates multi-level trace length control (e.g. short, medium, long reasoning). Experiments on four reasoning benchmarks, MATH500, AMC, AIME24 and OlympiadBench, demonstrate that TS is highly effective compared to s1's budget forcing approach and TLDR significantly improves token efficiency by about 50% with minimal to no accuracy loss over the SFT baseline. Moreover, TLDR also facilitates flexible control over the response length, offering a practical and effective solution for token-efficient reasoning in small models. Ultimately, our work reveals the importance of stopping time control, highlights shortcomings of pure SFT, and provides effective algorithmic recipes.
UBMF: Uncertainty-Aware Bayesian Meta-Learning Framework for Fault Diagnosis with Imbalanced Industrial Data
Mar 14, 2025
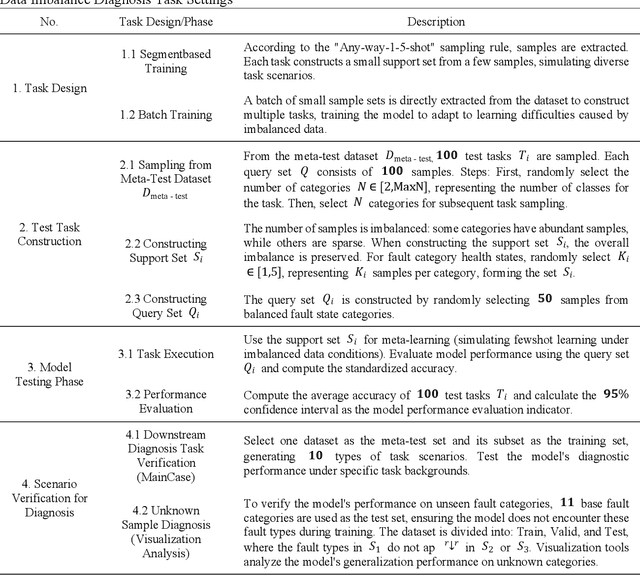


Fault diagnosis of mechanical equipment involves data collection, feature extraction, and pattern recognition but is often hindered by the imbalanced nature of industrial data, introducing significant uncertainty and reducing diagnostic reliability. To address these challenges, this study proposes the Uncertainty-Aware Bayesian Meta-Learning Framework (UBMF), which integrates four key modules: data perturbation injection for enhancing feature robustness, cross-task self-supervised feature extraction for improving transferability, uncertainty-based sample filtering for robust out-of-domain generalization, and Bayesian meta-knowledge integration for fine-grained classification. Experimental results on ten open-source datasets under various imbalanced conditions, including cross-task, small-sample, and unseen-sample scenarios, demonstrate the superiority of UBMF, achieving an average improvement of 42.22% across ten Any-way 1-5-shot diagnostic tasks. This integrated framework effectively enhances diagnostic accuracy, generalization, and adaptability, providing a reliable solution for complex industrial fault diagnosis.
Interval Estimation of Coefficients in Penalized Regression Models of Insurance Data
Oct 01, 2024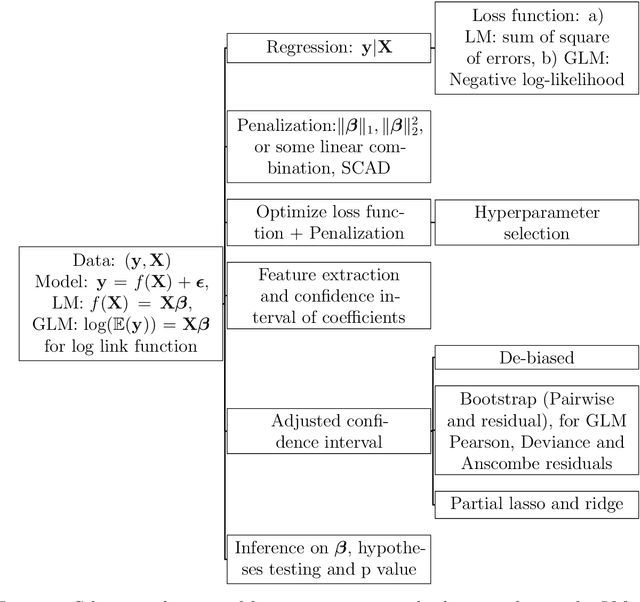



The Tweedie exponential dispersion family is a popular choice among many to model insurance losses that consist of zero-inflated semicontinuous data. In such data, it is often important to obtain credibility (inference) of the most important features that describe the endogenous variables. Post-selection inference is the standard procedure in statistics to obtain confidence intervals of model parameters after performing a feature extraction procedure. For a linear model, the lasso estimate often has non-negligible estimation bias for large coefficients corresponding to exogenous variables. To have valid inference on those coefficients, it is necessary to correct the bias of the lasso estimate. Traditional statistical methods, such as hypothesis testing or standard confidence interval construction might lead to incorrect conclusions during post-selection, as they are generally too optimistic. Here we discuss a few methodologies for constructing confidence intervals of the coefficients after feature selection in the Generalized Linear Model (GLM) family with application to insurance data.
TREACLE: Thrifty Reasoning via Context-Aware LLM and Prompt Selection
Apr 17, 2024



Recent successes in natural language processing have led to the proliferation of large language models (LLMs) by multiple providers. Each LLM offering has different inference accuracy, monetary cost, and latency, and their accuracy further depends on the exact wording of the question (i.e., the specific prompt). At the same time, users often have a limit on monetary budget and latency to answer all their questions, and they do not know which LLMs to choose for each question to meet their accuracy and long-term budget requirements. To navigate this rich design space, we propose TREACLE (Thrifty Reasoning via Context-Aware LLM and Prompt Selection), a reinforcement learning policy that jointly selects the model and prompting scheme while respecting the user's monetary cost and latency constraints. TREACLE uses the problem context, including question text embeddings (reflecting the type or difficulty of a query) and the response history (reflecting the consistency of previous responses) to make smart decisions. Our evaluations on standard reasoning datasets (GSM8K, CSQA, and LLC ) with various LLMs and prompts show that TREACLE enables cost savings of up to 85% compared to baselines while maintaining high accuracy. Importantly, it provides the user with the ability to gracefully trade off accuracy for cost.
COMMIT: Certifying Robustness of Multi-Sensor Fusion Systems against Semantic Attacks
Mar 04, 2024



Multi-sensor fusion systems (MSFs) play a vital role as the perception module in modern autonomous vehicles (AVs). Therefore, ensuring their robustness against common and realistic adversarial semantic transformations, such as rotation and shifting in the physical world, is crucial for the safety of AVs. While empirical evidence suggests that MSFs exhibit improved robustness compared to single-modal models, they are still vulnerable to adversarial semantic transformations. Despite the proposal of empirical defenses, several works show that these defenses can be attacked again by new adaptive attacks. So far, there is no certified defense proposed for MSFs. In this work, we propose the first robustness certification framework COMMIT certify robustness of multi-sensor fusion systems against semantic attacks. In particular, we propose a practical anisotropic noise mechanism that leverages randomized smoothing with multi-modal data and performs a grid-based splitting method to characterize complex semantic transformations. We also propose efficient algorithms to compute the certification in terms of object detection accuracy and IoU for large-scale MSF models. Empirically, we evaluate the efficacy of COMMIT in different settings and provide a comprehensive benchmark of certified robustness for different MSF models using the CARLA simulation platform. We show that the certification for MSF models is at most 48.39% higher than that of single-modal models, which validates the advantages of MSF models. We believe our certification framework and benchmark will contribute an important step towards certifiably robust AVs in practice.
CROP: Certifying Robust Policies for Reinforcement Learning through Functional Smoothing
Jun 17, 2021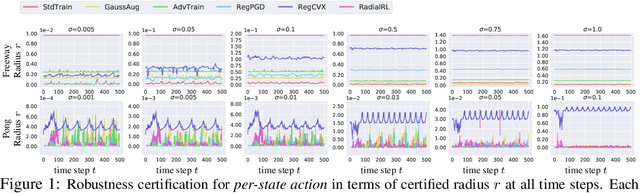
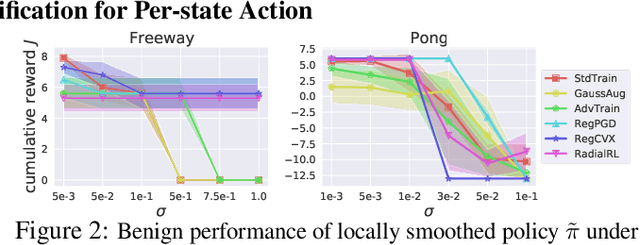
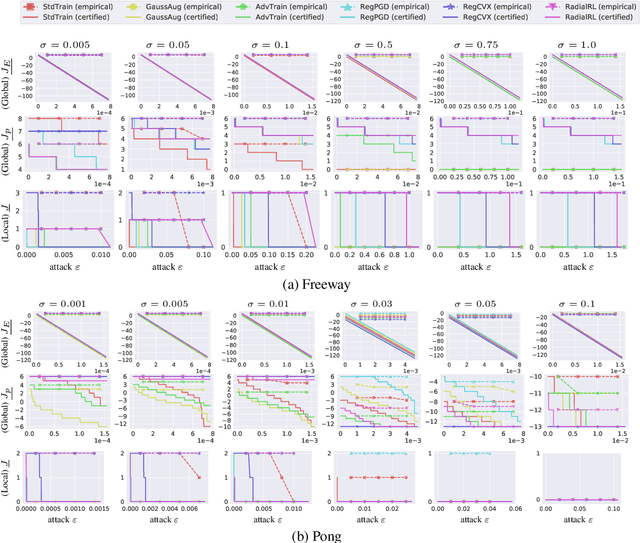
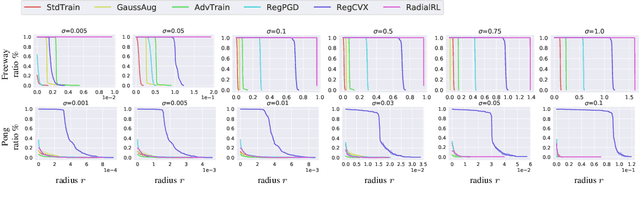
We present the first framework of Certifying Robust Policies for reinforcement learning (CROP) against adversarial state perturbations. We propose two particular types of robustness certification criteria: robustness of per-state actions and lower bound of cumulative rewards. Specifically, we develop a local smoothing algorithm which uses a policy derived from Q-functions smoothed with Gaussian noise over each encountered state to guarantee the robustness of actions taken along this trajectory. Next, we develop a global smoothing algorithm for certifying the robustness of a finite-horizon cumulative reward under adversarial state perturbations. Finally, we propose a local smoothing approach which makes use of adaptive search in order to obtain tight certification bounds for reward. We use the proposed RL robustness certification framework to evaluate six methods that have previously been shown to yield empirically robust RL, including adversarial training and several forms of regularization, on two representative Atari games. We show that RegPGD, RegCVX, and RadialRL achieve high certified robustness among these. Furthermore, we demonstrate that our certifications are often tight by evaluating these algorithms against adversarial attacks.
Music-oriented Dance Video Synthesis with Pose Perceptual Loss
Dec 13, 2019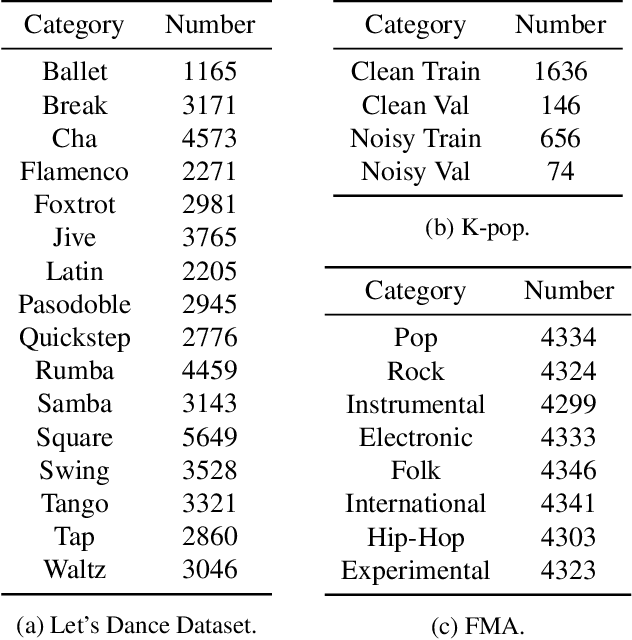
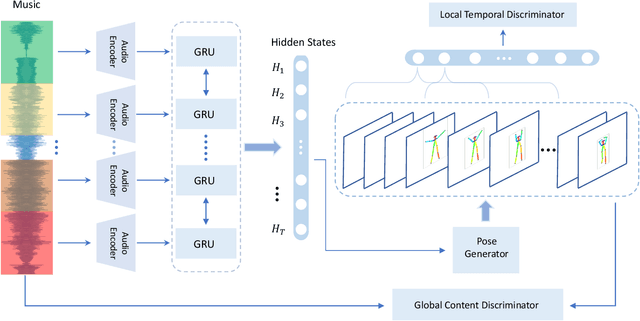
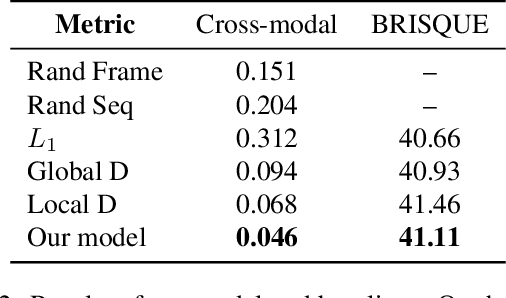

We present a learning-based approach with pose perceptual loss for automatic music video generation. Our method can produce a realistic dance video that conforms to the beats and rhymes of almost any given music. To achieve this, we firstly generate a human skeleton sequence from music and then apply the learned pose-to-appearance mapping to generate the final video. In the stage of generating skeleton sequences, we utilize two discriminators to capture different aspects of the sequence and propose a novel pose perceptual loss to produce natural dances. Besides, we also provide a new cross-modal evaluation to evaluate the dance quality, which is able to estimate the similarity between two modalities of music and dance. Finally, a user study is conducted to demonstrate that dance video synthesized by the presented approach produces surprisingly realistic results. The results are shown in the supplementary video at https://youtu.be/0rMuFMZa_K4