 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCROP: Certifying Robust Policies for Reinforcement Learning through Functional Smoothing
Paper and Code
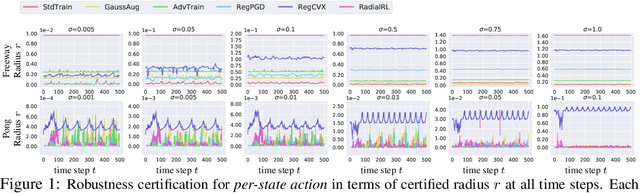
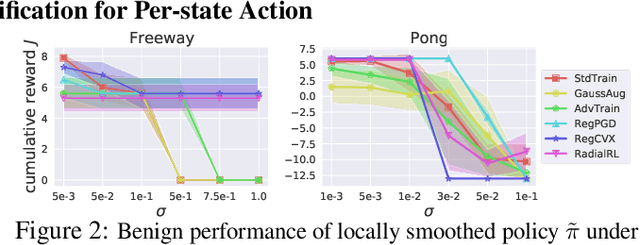
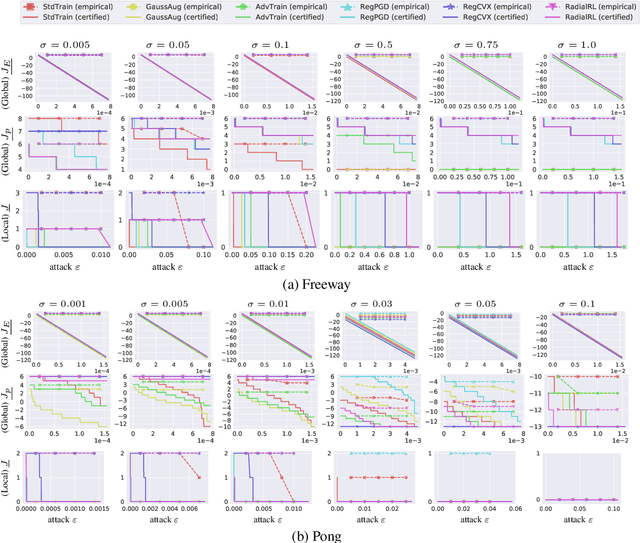
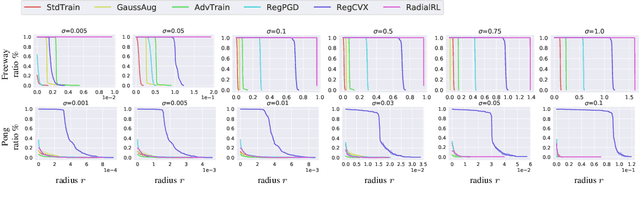
We present the first framework of Certifying Robust Policies for reinforcement learning (CROP) against adversarial state perturbations. We propose two particular types of robustness certification criteria: robustness of per-state actions and lower bound of cumulative rewards. Specifically, we develop a local smoothing algorithm which uses a policy derived from Q-functions smoothed with Gaussian noise over each encountered state to guarantee the robustness of actions taken along this trajectory. Next, we develop a global smoothing algorithm for certifying the robustness of a finite-horizon cumulative reward under adversarial state perturbations. Finally, we propose a local smoothing approach which makes use of adaptive search in order to obtain tight certification bounds for reward. We use the proposed RL robustness certification framework to evaluate six methods that have previously been shown to yield empirically robust RL, including adversarial training and several forms of regularization, on two representative Atari games. We show that RegPGD, RegCVX, and RadialRL achieve high certified robustness among these. Furthermore, we demonstrate that our certifications are often tight by evaluating these algorithms against adversarial attacks.