 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPE: Agentic Prompt Enhancer for Image Generation and Editing
May 29, 2026Natural language has become a powerful interface for image generation and editing, yet text-guided visual systems remain highly sensitive to prompt formulation. Semantically similar requests can produce different outputs depending on wording, specificity, and how explicitly visual constraints are stated, motivating prompt enhancement as a trainable component rather than a peripheral user choice. Existing strong enhancers often rely on large, proprietary LLMs such as ChatGPT or Gemini, adding cost, latency, and deployment dependence to the visual generation pipeline. We propose Agentic Prompt Enhancer (APE), a lightweight framework that post-trains small language models (SLMs) as prompt-enhancement agents. APE supports both single-agent rewriting and role-specialized multi-agent enhancement. Its single-agent instantiation, SAPE, rewrites the prompt in one pass, while its multi-agent instantiation, MAPE, decomposes enhancement into a router--rewriter--composer process for handling compositional constraints over objects, attributes, spatial relations, and edits. With task-aware rewards and post-training protocols, APE improves visual alignment and prompt following without modifying the downstream visual model. Experiments on challenging image generation and editing benchmarks demonstrate that post-trained small prompt enhancers reliably outperform their base counterparts, narrowing the gap to closed-source prompt enhancers; in addition, MAPE proves particularly strong on complex compositional tasks within these benchmarks.
Beyond Trajectory Rewards: Step-level Credit Assignment for Agentic Search via Graph Modeling
May 28, 2026In Agentic Search, trajectory-level outcome rewards fail to quantify the behavioral contributions of individual steps, while existing step-level reward methods typically rely on costly tree sampling. We view world knowledge as a latent world graph and each IS task as search within a latent task graph, where effective steps should make graph progress toward the answer node. Based on this prior, we propose Graph-Distance Contribution Reward (GDCR), a step-level process reward that scores newly-retrieved and newly-cited entities by their distance to the answer node in a training-time Entity-Relation (ER) graph. We further propose Step Advantage Policy Optimization (SAPO), which converts GDCR into step-level advantages and combines them with trajectory-level outcome advantages. Experiments on four challenging benchmarks validate the effectiveness of our method.
Making Small Language Models Efficient Reasoners: Intervention, Supervision, Reinforcement
May 14, 2025Recent research enhances language model reasoning by scaling test-time compute via longer chain-of-thought traces. This often improves accuracy but also introduces redundancy and high computational cost, especially for small language models distilled with supervised fine-tuning (SFT). In this work, we propose new algorithms to improve token-efficient reasoning with small-scale models by effectively trading off accuracy and computation. We first show that the post-SFT model fails to determine the optimal stopping point of the reasoning process, resulting in verbose and repetitive outputs. Verbosity also significantly varies across wrong vs correct responses. To address these issues, we propose two solutions: (1) Temperature scaling (TS) to control the stopping point for the thinking phase and thereby trace length, and (2) TLDR: a length-regularized reinforcement learning method based on GRPO that facilitates multi-level trace length control (e.g. short, medium, long reasoning). Experiments on four reasoning benchmarks, MATH500, AMC, AIME24 and OlympiadBench, demonstrate that TS is highly effective compared to s1's budget forcing approach and TLDR significantly improves token efficiency by about 50% with minimal to no accuracy loss over the SFT baseline. Moreover, TLDR also facilitates flexible control over the response length, offering a practical and effective solution for token-efficient reasoning in small models. Ultimately, our work reveals the importance of stopping time control, highlights shortcomings of pure SFT, and provides effective algorithmic recipes.
L3GS: Layered 3D Gaussian Splats for Efficient 3D Scene Delivery
Apr 07, 2025Traditional 3D content representations include dense point clouds that consume large amounts of data and hence network bandwidth, while newer representations such as neural radiance fields suffer from poor frame rates due to their non-standard volumetric rendering pipeline. 3D Gaussian splats (3DGS) can be seen as a generalization of point clouds that meet the best of both worlds, with high visual quality and efficient rendering for real-time frame rates. However, delivering 3DGS scenes from a hosting server to client devices is still challenging due to high network data consumption (e.g., 1.5 GB for a single scene). The goal of this work is to create an efficient 3D content delivery framework that allows users to view high quality 3D scenes with 3DGS as the underlying data representation. The main contributions of the paper are: (1) Creating new layered 3DGS scenes for efficient delivery, (2) Scheduling algorithms to choose what splats to download at what time, and (3) Trace-driven experiments from users wearing virtual reality headsets to evaluate the visual quality and latency. Our system for Layered 3D Gaussian Splats delivery L3GS demonstrates high visual quality, achieving 16.9% higher average SSIM compared to baselines, and also works with other compressed 3DGS representations.
Selective Attention: Enhancing Transformer through Principled Context Control
Nov 19, 2024



The attention mechanism within the transformer architecture enables the model to weigh and combine tokens based on their relevance to the query. While self-attention has enjoyed major success, it notably treats all queries $q$ in the same way by applying the mapping $V^\top\text{softmax}(Kq)$, where $V,K$ are the value and key embeddings respectively. In this work, we argue that this uniform treatment hinders the ability to control contextual sparsity and relevance. As a solution, we introduce the $\textit{Selective Self-Attention}$ (SSA) layer that augments the softmax nonlinearity with a principled temperature scaling strategy. By controlling temperature, SSA adapts the contextual sparsity of the attention map to the query embedding and its position in the context window. Through theory and experiments, we demonstrate that this alleviates attention dilution, aids the optimization process, and enhances the model's ability to control softmax spikiness of individual queries. We also incorporate temperature scaling for value embeddings and show that it boosts the model's ability to suppress irrelevant/noisy tokens. Notably, SSA is a lightweight method which introduces less than 0.5% new parameters through a weight-sharing strategy and can be fine-tuned on existing LLMs. Extensive empirical evaluations demonstrate that SSA-equipped models achieve a noticeable and consistent accuracy improvement on language modeling benchmarks.
TREACLE: Thrifty Reasoning via Context-Aware LLM and Prompt Selection
Apr 17, 2024



Recent successes in natural language processing have led to the proliferation of large language models (LLMs) by multiple providers. Each LLM offering has different inference accuracy, monetary cost, and latency, and their accuracy further depends on the exact wording of the question (i.e., the specific prompt). At the same time, users often have a limit on monetary budget and latency to answer all their questions, and they do not know which LLMs to choose for each question to meet their accuracy and long-term budget requirements. To navigate this rich design space, we propose TREACLE (Thrifty Reasoning via Context-Aware LLM and Prompt Selection), a reinforcement learning policy that jointly selects the model and prompting scheme while respecting the user's monetary cost and latency constraints. TREACLE uses the problem context, including question text embeddings (reflecting the type or difficulty of a query) and the response history (reflecting the consistency of previous responses) to make smart decisions. Our evaluations on standard reasoning datasets (GSM8K, CSQA, and LLC ) with various LLMs and prompts show that TREACLE enables cost savings of up to 85% compared to baselines while maintaining high accuracy. Importantly, it provides the user with the ability to gracefully trade off accuracy for cost.
Class-attribute Priors: Adapting Optimization to Heterogeneity and Fairness Objective
Jan 25, 2024



Modern classification problems exhibit heterogeneities across individual classes: Each class may have unique attributes, such as sample size, label quality, or predictability (easy vs difficult), and variable importance at test-time. Without care, these heterogeneities impede the learning process, most notably, when optimizing fairness objectives. Confirming this, under a gaussian mixture setting, we show that the optimal SVM classifier for balanced accuracy needs to be adaptive to the class attributes. This motivates us to propose CAP: An effective and general method that generates a class-specific learning strategy (e.g. hyperparameter) based on the attributes of that class. This way, optimization process better adapts to heterogeneities. CAP leads to substantial improvements over the naive approach of assigning separate hyperparameters to each class. We instantiate CAP for loss function design and post-hoc logit adjustment, with emphasis on label-imbalanced problems. We show that CAP is competitive with prior art and its flexibility unlocks clear benefits for fairness objectives beyond balanced accuracy. Finally, we evaluate CAP on problems with label noise as well as weighted test objectives to showcase how CAP can jointly adapt to different heterogeneities.
FedYolo: Augmenting Federated Learning with Pretrained Transformers
Jul 10, 2023



The growth and diversity of machine learning applications motivate a rethinking of learning with mobile and edge devices. How can we address diverse client goals and learn with scarce heterogeneous data? While federated learning aims to address these issues, it has challenges hindering a unified solution. Large transformer models have been shown to work across a variety of tasks achieving remarkable few-shot adaptation. This raises the question: Can clients use a single general-purpose model, rather than custom models for each task, while obeying device and network constraints? In this work, we investigate pretrained transformers (PTF) to achieve these on-device learning goals and thoroughly explore the roles of model size and modularity, where the latter refers to adaptation through modules such as prompts or adapters. Focusing on federated learning, we demonstrate that: (1) Larger scale shrinks the accuracy gaps between alternative approaches and improves heterogeneity robustness. Scale allows clients to run more local SGD epochs which can significantly reduce the number of communication rounds. At the extreme, clients can achieve respectable accuracy locally highlighting the potential of fully-local learning. (2) Modularity, by design, enables $>$100$\times$ less communication in bits. Surprisingly, it also boosts the generalization capability of local adaptation methods and the robustness of smaller PTFs. Finally, it enables clients to solve multiple unrelated tasks simultaneously using a single PTF, whereas full updates are prone to catastrophic forgetting. These insights on scale and modularity motivate a new federated learning approach we call "You Only Load Once" (FedYolo): The clients load a full PTF model once and all future updates are accomplished through communication-efficient modules with limited catastrophic-forgetting, where each task is assigned to its own module.
AutoBalance: Optimized Loss Functions for Imbalanced Data
Jan 04, 2022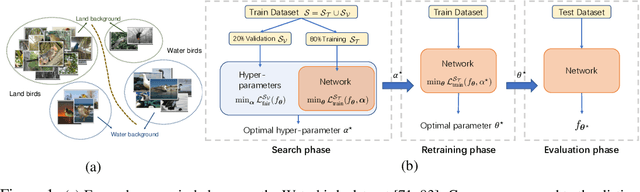
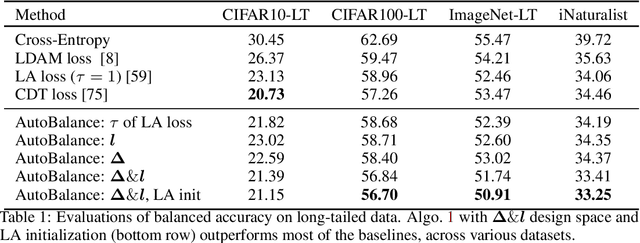
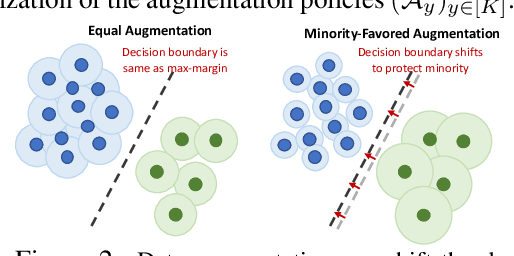

Imbalanced datasets are commonplace in modern machine learning problems. The presence of under-represented classes or groups with sensitive attributes results in concerns about generalization and fairness. Such concerns are further exacerbated by the fact that large capacity deep nets can perfectly fit the training data and appear to achieve perfect accuracy and fairness during training, but perform poorly during test. To address these challenges, we propose AutoBalance, a bi-level optimization framework that automatically designs a training loss function to optimize a blend of accuracy and fairness-seeking objectives. Specifically, a lower-level problem trains the model weights, and an upper-level problem tunes the loss function by monitoring and optimizing the desired objective over the validation data. Our loss design enables personalized treatment for classes/groups by employing a parametric cross-entropy loss and individualized data augmentation schemes. We evaluate the benefits and performance of our approach for the application scenarios of imbalanced and group-sensitive classification. Extensive empirical evaluations demonstrate the benefits of AutoBalance over state-of-the-art approaches. Our experimental findings are complemented with theoretical insights on loss function design and the benefits of train-validation split. All code is available open-source.
Post-hoc Models for Performance Estimation of Machine Learning Inference
Oct 06, 2021
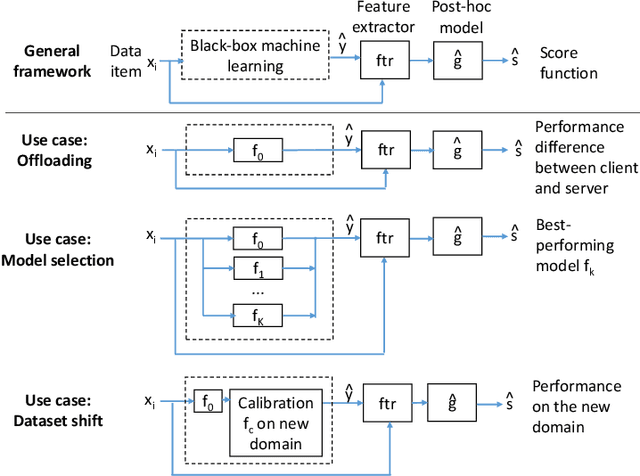
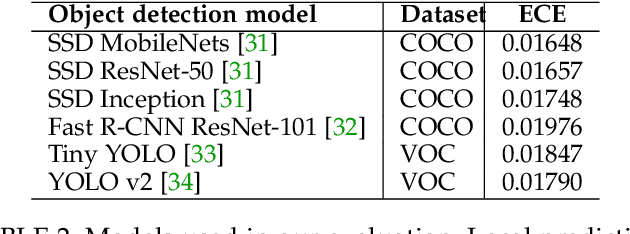
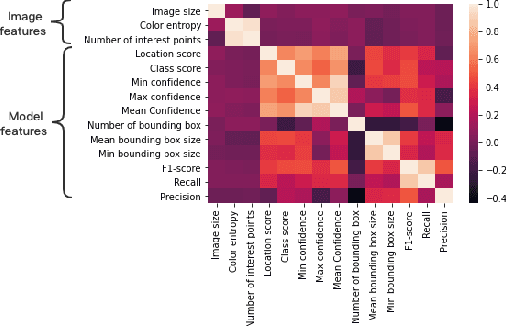
Estimating how well a machine learning model performs during inference is critical in a variety of scenarios (for example, to quantify uncertainty, or to choose from a library of available models). However, the standard accuracy estimate of softmax confidence is not versatile and cannot reliably predict different performance metrics (e.g., F1-score, recall) or the performance in different application scenarios or input domains. In this work, we systematically generalize performance estimation to a diverse set of metrics and scenarios and discuss generalized notions of uncertainty calibration. We propose the use of post-hoc models to accomplish this goal and investigate design parameters, including the model type, feature engineering, and performance metric, to achieve the best estimation quality. Emphasis is given to object detection problems and, unlike prior work, our approach enables the estimation of per-image metrics such as recall and F1-score. Through extensive experiments with computer vision models and datasets in three use cases -- mobile edge offloading, model selection, and dataset shift -- we find that proposed post-hoc models consistently outperform the standard calibrated confidence baselines. To the best of our knowledge, this is the first work to develop a unified framework to address different performance estimation problems for machine learning inference.