 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Bet for Horizon-Aware Anytime-Valid Testing
Mar 20, 2026We develop horizon-aware anytime-valid tests and confidence sequences for bounded means under a strict deadline $N$. Using the betting/e-process framework, we cast horizon-aware betting as a finite-horizon optimal control problem with state space $(t, \log W_t)$, where $t$ is the time and $W_t$ is the test martingale value. We first show that in certain interior regions of the state space, policies that deviate significantly from Kelly betting are provably suboptimal, while Kelly betting reaches the threshold with high probability. We then identify sufficient conditions showing that outside this region, more aggressive betting than Kelly can be better if the bettor is behind schedule, and less aggressive can be better if the bettor is ahead. Taken together these results suggest a simple phase diagram in the $(t, \log W_t)$ plane, delineating regions where Kelly, fractional Kelly, and aggressive betting may be preferable. Guided by this phase diagram, we introduce a Deep Reinforcement Learning approach based on a universal Deep Q-Network (DQN) agent that learns a single policy from synthetic experience and maps simple statistics of past observations to bets across horizons and null values. In limited-horizon experiments, the learned DQN policy yields state-of-the-art results.
Covariance-Aware Transformers for Quadratic Programming and Decision Making
Feb 16, 2026We explore the use of transformers for solving quadratic programs and how this capability benefits decision-making problems that involve covariance matrices. We first show that the linear attention mechanism can provably solve unconstrained QPs by tokenizing the matrix variables (e.g.~$A$ of the objective $\frac{1}{2}x^\top Ax+b^\top x$) row-by-row and emulating gradient descent iterations. Furthermore, by incorporating MLPs, a transformer block can solve (i) $\ell_1$-penalized QPs by emulating iterative soft-thresholding and (ii) $\ell_1$-constrained QPs when equipped with an additional feedback loop. Our theory motivates us to introduce Time2Decide: a generic method that enhances a time series foundation model (TSFM) by explicitly feeding the covariance matrix between the variates. We empirically find that Time2Decide uniformly outperforms the base TSFM model for the classical portfolio optimization problem that admits an $\ell_1$-constrained QP formulation. Remarkably, Time2Decide also outperforms the classical "Predict-then-Optimize (PtO)" procedure, where we first forecast the returns and then explicitly solve a constrained QP, in suitable settings. Our results demonstrate that transformers benefit from explicit use of second-order statistics, and this can enable them to effectively solve complex decision-making problems, like portfolio construction, in one forward pass.
TimePFN: Effective Multivariate Time Series Forecasting with Synthetic Data
Feb 22, 2025The diversity of time series applications and scarcity of domain-specific data highlight the need for time-series models with strong few-shot learning capabilities. In this work, we propose a novel training scheme and a transformer-based architecture, collectively referred to as TimePFN, for multivariate time-series (MTS) forecasting. TimePFN is based on the concept of Prior-data Fitted Networks (PFN), which aims to approximate Bayesian inference. Our approach consists of (1) generating synthetic MTS data through diverse Gaussian process kernels and the linear coregionalization method, and (2) a novel MTS architecture capable of utilizing both temporal and cross-channel dependencies across all input patches. We evaluate TimePFN on several benchmark datasets and demonstrate that it outperforms the existing state-of-the-art models for MTS forecasting in both zero-shot and few-shot settings. Notably, fine-tuning TimePFN with as few as 500 data points nearly matches full dataset training error, and even 50 data points yield competitive results. We also find that TimePFN exhibits strong univariate forecasting performance, attesting to its generalization ability. Overall, this work unlocks the power of synthetic data priors for MTS forecasting and facilitates strong zero- and few-shot forecasting performance.
Retrieval Augmented Time Series Forecasting
Nov 12, 2024
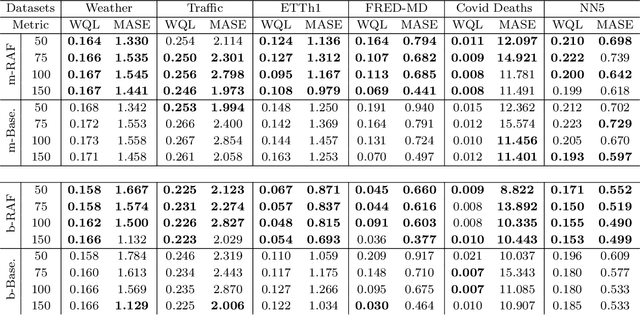

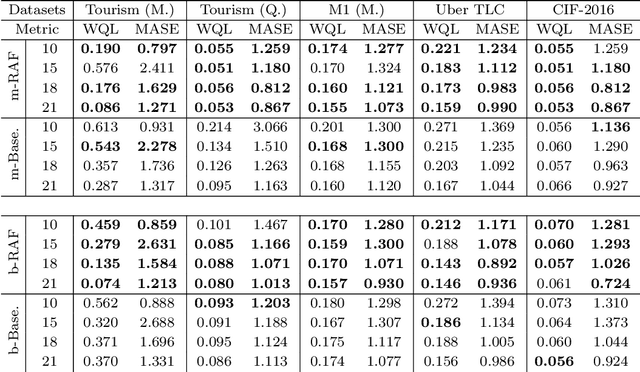
Retrieval-augmented generation (RAG) is a central component of modern LLM systems, particularly in scenarios where up-to-date information is crucial for accurately responding to user queries or when queries exceed the scope of the training data. The advent of time-series foundation models (TSFM), such as Chronos, and the need for effective zero-shot forecasting performance across various time-series domains motivates the question: Do benefits of RAG similarly carry over to time series forecasting? In this paper, we advocate that the dynamic and event-driven nature of time-series data makes RAG a crucial component of TSFMs and introduce a principled RAG framework for time-series forecasting, called Retrieval Augmented Forecasting (RAF). Within RAF, we develop efficient strategies for retrieving related time-series examples and incorporating them into forecast. Through experiments and mechanistic studies, we demonstrate that RAF indeed improves the forecasting accuracy across diverse time series domains and the improvement is more significant for larger TSFM sizes.
High-dimensional Analysis of Knowledge Distillation: Weak-to-Strong Generalization and Scaling Laws
Oct 24, 2024A growing number of machine learning scenarios rely on knowledge distillation where one uses the output of a surrogate model as labels to supervise the training of a target model. In this work, we provide a sharp characterization of this process for ridgeless, high-dimensional regression, under two settings: (i) model shift, where the surrogate model is arbitrary, and (ii) distribution shift, where the surrogate model is the solution of empirical risk minimization with out-of-distribution data. In both cases, we characterize the precise risk of the target model through non-asymptotic bounds in terms of sample size and data distribution under mild conditions. As a consequence, we identify the form of the optimal surrogate model, which reveals the benefits and limitations of discarding weak features in a data-dependent fashion. In the context of weak-to-strong (W2S) generalization, this has the interpretation that (i) W2S training, with the surrogate as the weak model, can provably outperform training with strong labels under the same data budget, but (ii) it is unable to improve the data scaling law. We validate our results on numerical experiments both on ridgeless regression and on neural network architectures.
TREACLE: Thrifty Reasoning via Context-Aware LLM and Prompt Selection
Apr 17, 2024



Recent successes in natural language processing have led to the proliferation of large language models (LLMs) by multiple providers. Each LLM offering has different inference accuracy, monetary cost, and latency, and their accuracy further depends on the exact wording of the question (i.e., the specific prompt). At the same time, users often have a limit on monetary budget and latency to answer all their questions, and they do not know which LLMs to choose for each question to meet their accuracy and long-term budget requirements. To navigate this rich design space, we propose TREACLE (Thrifty Reasoning via Context-Aware LLM and Prompt Selection), a reinforcement learning policy that jointly selects the model and prompting scheme while respecting the user's monetary cost and latency constraints. TREACLE uses the problem context, including question text embeddings (reflecting the type or difficulty of a query) and the response history (reflecting the consistency of previous responses) to make smart decisions. Our evaluations on standard reasoning datasets (GSM8K, CSQA, and LLC ) with various LLMs and prompts show that TREACLE enables cost savings of up to 85% compared to baselines while maintaining high accuracy. Importantly, it provides the user with the ability to gracefully trade off accuracy for cost.