 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Chain of Thought Enables Parallel Exploration and Reasoning
May 29, 2025Current language models generate chain-of-thought traces by autoregressively sampling tokens from a finite vocabulary. While this discrete sampling has achieved remarkable success, conducting chain-of-thought with continuously-valued tokens (CoT2) offers a richer and more expressive alternative. Our work examines the benefits of CoT2 through logical reasoning tasks that inherently require search capabilities and provide optimization and exploration methods for CoT2. Theoretically, we show that CoT2 allows the model to track multiple traces in parallel and quantify its benefits for inference efficiency. Notably, one layer transformer equipped with CoT2 can provably solve the combinatorial "subset sum problem" given sufficient embedding dimension. These insights lead to a novel and effective supervision strategy where we match the softmax outputs to the empirical token distributions of a set of target traces. Complementing this, we introduce sampling strategies that unlock policy optimization and self-improvement for CoT2. Our first strategy samples and composes $K$ discrete tokens at each decoding step to control the level of parallelism, and reduces to standard CoT when $K=1$. Our second strategy relies on continuous exploration over the probability simplex. Experiments confirm that policy optimization with CoT2 indeed improves the performance of the model beyond its initial discrete or continuous supervision.
Test-Time Training Provably Improves Transformers as In-context Learners
Mar 14, 2025Test-time training (TTT) methods explicitly update the weights of a model to adapt to the specific test instance, and they have found success in a variety of settings, including most recently language modeling and reasoning. To demystify this success, we investigate a gradient-based TTT algorithm for in-context learning, where we train a transformer model on the in-context demonstrations provided in the test prompt. Specifically, we provide a comprehensive theoretical characterization of linear transformers when the update rule is a single gradient step. Our theory (i) delineates the role of alignment between pretraining distribution and target task, (ii) demystifies how TTT can alleviate distribution shift, and (iii) quantifies the sample complexity of TTT including how it can significantly reduce the eventual sample size required for in-context learning. As our empirical contribution, we study the benefits of TTT for TabPFN, a tabular foundation model. In line with our theory, we demonstrate that TTT significantly reduces the required sample size for tabular classification (3 to 5 times fewer) unlocking substantial inference efficiency with a negligible training cost.
TimePFN: Effective Multivariate Time Series Forecasting with Synthetic Data
Feb 22, 2025The diversity of time series applications and scarcity of domain-specific data highlight the need for time-series models with strong few-shot learning capabilities. In this work, we propose a novel training scheme and a transformer-based architecture, collectively referred to as TimePFN, for multivariate time-series (MTS) forecasting. TimePFN is based on the concept of Prior-data Fitted Networks (PFN), which aims to approximate Bayesian inference. Our approach consists of (1) generating synthetic MTS data through diverse Gaussian process kernels and the linear coregionalization method, and (2) a novel MTS architecture capable of utilizing both temporal and cross-channel dependencies across all input patches. We evaluate TimePFN on several benchmark datasets and demonstrate that it outperforms the existing state-of-the-art models for MTS forecasting in both zero-shot and few-shot settings. Notably, fine-tuning TimePFN with as few as 500 data points nearly matches full dataset training error, and even 50 data points yield competitive results. We also find that TimePFN exhibits strong univariate forecasting performance, attesting to its generalization ability. Overall, this work unlocks the power of synthetic data priors for MTS forecasting and facilitates strong zero- and few-shot forecasting performance.
High-dimensional Analysis of Knowledge Distillation: Weak-to-Strong Generalization and Scaling Laws
Oct 24, 2024A growing number of machine learning scenarios rely on knowledge distillation where one uses the output of a surrogate model as labels to supervise the training of a target model. In this work, we provide a sharp characterization of this process for ridgeless, high-dimensional regression, under two settings: (i) model shift, where the surrogate model is arbitrary, and (ii) distribution shift, where the surrogate model is the solution of empirical risk minimization with out-of-distribution data. In both cases, we characterize the precise risk of the target model through non-asymptotic bounds in terms of sample size and data distribution under mild conditions. As a consequence, we identify the form of the optimal surrogate model, which reveals the benefits and limitations of discarding weak features in a data-dependent fashion. In the context of weak-to-strong (W2S) generalization, this has the interpretation that (i) W2S training, with the surrogate as the weak model, can provably outperform training with strong labels under the same data budget, but (ii) it is unable to improve the data scaling law. We validate our results on numerical experiments both on ridgeless regression and on neural network architectures.
Mechanics of Next Token Prediction with Self-Attention
Mar 12, 2024



Transformer-based language models are trained on large datasets to predict the next token given an input sequence. Despite this simple training objective, they have led to revolutionary advances in natural language processing. Underlying this success is the self-attention mechanism. In this work, we ask: $\textit{What}$ $\textit{does}$ $\textit{a}$ $\textit{single}$ $\textit{self-attention}$ $\textit{layer}$ $\textit{learn}$ $\textit{from}$ $\textit{next-token}$ $\textit{prediction?}$ We show that training self-attention with gradient descent learns an automaton which generates the next token in two distinct steps: $\textbf{(1)}$ $\textbf{Hard}$ $\textbf{retrieval:}$ Given input sequence, self-attention precisely selects the $\textit{high-priority}$ $\textit{input}$ $\textit{tokens}$ associated with the last input token. $\textbf{(2)}$ $\textbf{Soft}$ $\textbf{composition:}$ It then creates a convex combination of the high-priority tokens from which the next token can be sampled. Under suitable conditions, we rigorously characterize these mechanics through a directed graph over tokens extracted from the training data. We prove that gradient descent implicitly discovers the strongly-connected components (SCC) of this graph and self-attention learns to retrieve the tokens that belong to the highest-priority SCC available in the context window. Our theory relies on decomposing the model weights into a directional component and a finite component that correspond to hard retrieval and soft composition steps respectively. This also formalizes a related implicit bias formula conjectured in [Tarzanagh et al. 2023]. We hope that these findings shed light on how self-attention processes sequential data and pave the path toward demystifying more complex architectures.
From Self-Attention to Markov Models: Unveiling the Dynamics of Generative Transformers
Feb 21, 2024



Modern language models rely on the transformer architecture and attention mechanism to perform language understanding and text generation. In this work, we study learning a 1-layer self-attention model from a set of prompts and associated output data sampled from the model. We first establish a precise mapping between the self-attention mechanism and Markov models: Inputting a prompt to the model samples the output token according to a context-conditioned Markov chain (CCMC) which weights the transition matrix of a base Markov chain. Additionally, incorporating positional encoding results in position-dependent scaling of the transition probabilities. Building on this formalism, we develop identifiability/coverage conditions for the prompt distribution that guarantee consistent estimation and establish sample complexity guarantees under IID samples. Finally, we study the problem of learning from a single output trajectory generated from an initial prompt. We characterize an intriguing winner-takes-all phenomenon where the generative process implemented by self-attention collapses into sampling a limited subset of tokens due to its non-mixing nature. This provides a mathematical explanation to the tendency of modern LLMs to generate repetitive text. In summary, the equivalence to CCMC provides a simple but powerful framework to study self-attention and its properties.
Transformers as Algorithms: Generalization and Implicit Model Selection in In-context Learning
Jan 17, 2023

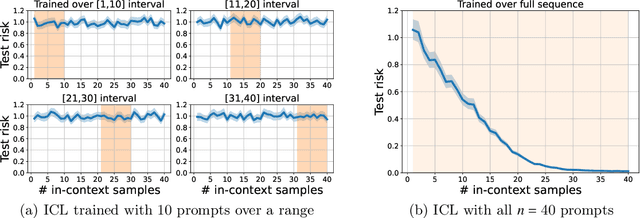

In-context learning (ICL) is a type of prompting where a transformer model operates on a sequence of (input, output) examples and performs inference on-the-fly. This implicit training is in contrast to explicitly tuning the model weights based on examples. In this work, we formalize in-context learning as an algorithm learning problem, treating the transformer model as a learning algorithm that can be specialized via training to implement-at inference-time-another target algorithm. We first explore the statistical aspects of this abstraction through the lens of multitask learning: We obtain generalization bounds for ICL when the input prompt is (1) a sequence of i.i.d. (input, label) pairs or (2) a trajectory arising from a dynamical system. The crux of our analysis is relating the excess risk to the stability of the algorithm implemented by the transformer, which holds under mild assumptions. Secondly, we use our abstraction to show that transformers can act as an adaptive learning algorithm and perform model selection across different hypothesis classes. We provide numerical evaluations that (1) demonstrate transformers can indeed implement near-optimal algorithms on classical regression problems with i.i.d. and dynamic data, (2) identify an inductive bias phenomenon where the transfer risk on unseen tasks is independent of the transformer complexity, and (3) empirically verify our theoretical predictions.