 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Chain of Thought Enables Parallel Exploration and Reasoning
May 29, 2025Current language models generate chain-of-thought traces by autoregressively sampling tokens from a finite vocabulary. While this discrete sampling has achieved remarkable success, conducting chain-of-thought with continuously-valued tokens (CoT2) offers a richer and more expressive alternative. Our work examines the benefits of CoT2 through logical reasoning tasks that inherently require search capabilities and provide optimization and exploration methods for CoT2. Theoretically, we show that CoT2 allows the model to track multiple traces in parallel and quantify its benefits for inference efficiency. Notably, one layer transformer equipped with CoT2 can provably solve the combinatorial "subset sum problem" given sufficient embedding dimension. These insights lead to a novel and effective supervision strategy where we match the softmax outputs to the empirical token distributions of a set of target traces. Complementing this, we introduce sampling strategies that unlock policy optimization and self-improvement for CoT2. Our first strategy samples and composes $K$ discrete tokens at each decoding step to control the level of parallelism, and reduces to standard CoT when $K=1$. Our second strategy relies on continuous exploration over the probability simplex. Experiments confirm that policy optimization with CoT2 indeed improves the performance of the model beyond its initial discrete or continuous supervision.
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA
Oct 28, 2024



Large language models (LLMs) are expensive to deploy. Parameter sharing offers a possible path towards reducing their size and cost, but its effectiveness in modern LLMs remains fairly limited. In this work, we revisit "layer tying" as form of parameter sharing in Transformers, and introduce novel methods for converting existing LLMs into smaller "Recursive Transformers" that share parameters across layers, with minimal loss of performance. Here, our Recursive Transformers are efficiently initialized from standard pretrained Transformers, but only use a single block of unique layers that is then repeated multiple times in a loop. We further improve performance by introducing Relaxed Recursive Transformers that add flexibility to the layer tying constraint via depth-wise low-rank adaptation (LoRA) modules, yet still preserve the compactness of the overall model. We show that our recursive models (e.g., recursive Gemma 1B) outperform both similar-sized vanilla pretrained models (such as TinyLlama 1.1B and Pythia 1B) and knowledge distillation baselines -- and can even recover most of the performance of the original "full-size" model (e.g., Gemma 2B with no shared parameters). Finally, we propose Continuous Depth-wise Batching, a promising new inference paradigm enabled by the Recursive Transformer when paired with early exiting. In a theoretical analysis, we show that this has the potential to lead to significant (2-3x) gains in inference throughput.
A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs
Oct 24, 2024
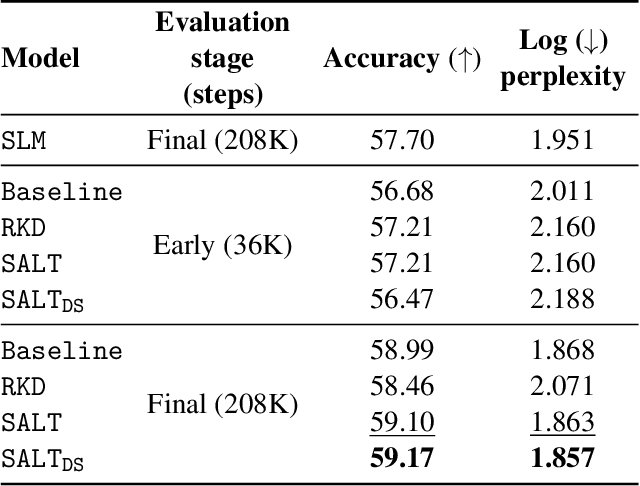

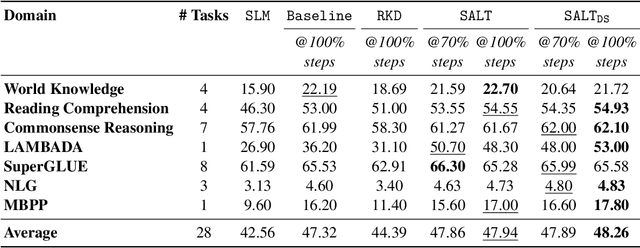
A primary challenge in large language model (LLM) development is their onerous pre-training cost. Typically, such pre-training involves optimizing a self-supervised objective (such as next-token prediction) over a large corpus. This paper explores a promising paradigm to improve LLM pre-training efficiency and quality by suitably leveraging a small language model (SLM). In particular, this paradigm relies on an SLM to both (1) provide soft labels as additional training supervision, and (2) select a small subset of valuable ("informative" and "hard") training examples. Put together, this enables an effective transfer of the SLM's predictive distribution to the LLM, while prioritizing specific regions of the training data distribution. Empirically, this leads to reduced LLM training time compared to standard training, while improving the overall quality. Theoretically, we develop a statistical framework to systematically study the utility of SLMs in enabling efficient training of high-quality LLMs. In particular, our framework characterizes how the SLM's seemingly low-quality supervision can enhance the training of a much more capable LLM. Furthermore, it also highlights the need for an adaptive utilization of such supervision, by striking a balance between the bias and variance introduced by the SLM-provided soft labels. We corroborate our theoretical framework by improving the pre-training of an LLM with 2.8B parameters by utilizing a smaller LM with 1.5B parameters on the Pile dataset.
Mimetic Initialization Helps State Space Models Learn to Recall
Oct 14, 2024



Recent work has shown that state space models such as Mamba are significantly worse than Transformers on recall-based tasks due to the fact that their state size is constant with respect to their input sequence length. But in practice, state space models have fairly large state sizes, and we conjecture that they should be able to perform much better at these tasks than previously reported. We investigate whether their poor copying and recall performance could be due in part to training difficulties rather than fundamental capacity constraints. Based on observations of their "attention" maps, we propose a structured initialization technique that allows state space layers to more readily mimic attention. Across a variety of architecture settings, our initialization makes it substantially easier for Mamba to learn to copy and do associative recall from scratch.
In-context Learning in Presence of Spurious Correlations
Oct 04, 2024



Large language models exhibit a remarkable capacity for in-context learning, where they learn to solve tasks given a few examples. Recent work has shown that transformers can be trained to perform simple regression tasks in-context. This work explores the possibility of training an in-context learner for classification tasks involving spurious features. We find that the conventional approach of training in-context learners is susceptible to spurious features. Moreover, when the meta-training dataset includes instances of only one task, the conventional approach leads to task memorization and fails to produce a model that leverages context for predictions. Based on these observations, we propose a novel technique to train such a learner for a given classification task. Remarkably, this in-context learner matches and sometimes outperforms strong methods like ERM and GroupDRO. However, unlike these algorithms, it does not generalize well to other tasks. We show that it is possible to obtain an in-context learner that generalizes to unseen tasks by training on a diverse dataset of synthetic in-context learning instances.
On information captured by neural networks: connections with memorization and generalization
Jun 28, 2023



Despite the popularity and success of deep learning, there is limited understanding of when, how, and why neural networks generalize to unseen examples. Since learning can be seen as extracting information from data, we formally study information captured by neural networks during training. Specifically, we start with viewing learning in presence of noisy labels from an information-theoretic perspective and derive a learning algorithm that limits label noise information in weights. We then define a notion of unique information that an individual sample provides to the training of a deep network, shedding some light on the behavior of neural networks on examples that are atypical, ambiguous, or belong to underrepresented subpopulations. We relate example informativeness to generalization by deriving nonvacuous generalization gap bounds. Finally, by studying knowledge distillation, we highlight the important role of data and label complexity in generalization. Overall, our findings contribute to a deeper understanding of the mechanisms underlying neural network generalization.
Identifying and Disentangling Spurious Features in Pretrained Image Representations
Jun 22, 2023



Neural networks employ spurious correlations in their predictions, resulting in decreased performance when these correlations do not hold. Recent works suggest fixing pretrained representations and training a classification head that does not use spurious features. We investigate how spurious features are represented in pretrained representations and explore strategies for removing information about spurious features. Considering the Waterbirds dataset and a few pretrained representations, we find that even with full knowledge of spurious features, their removal is not straightforward due to entangled representation. To address this, we propose a linear autoencoder training method to separate the representation into core, spurious, and other features. We propose two effective spurious feature removal approaches that are applied to the encoding and significantly improve classification performance measured by worst group accuracy.
A Meta-Learning Approach to Predicting Performance and Data Requirements
Mar 02, 2023We propose an approach to estimate the number of samples required for a model to reach a target performance. We find that the power law, the de facto principle to estimate model performance, leads to large error when using a small dataset (e.g., 5 samples per class) for extrapolation. This is because the log-performance error against the log-dataset size follows a nonlinear progression in the few-shot regime followed by a linear progression in the high-shot regime. We introduce a novel piecewise power law (PPL) that handles the two data regimes differently. To estimate the parameters of the PPL, we introduce a random forest regressor trained via meta learning that generalizes across classification/detection tasks, ResNet/ViT based architectures, and random/pre-trained initializations. The PPL improves the performance estimation on average by 37% across 16 classification and 33% across 10 detection datasets, compared to the power law. We further extend the PPL to provide a confidence bound and use it to limit the prediction horizon that reduces over-estimation of data by 76% on classification and 91% on detection datasets.
Supervision Complexity and its Role in Knowledge Distillation
Jan 28, 2023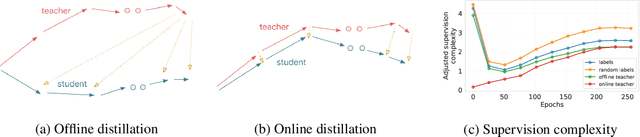


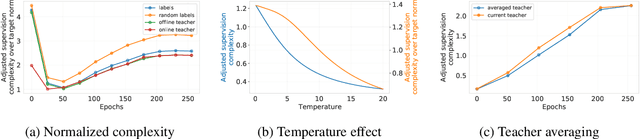
Despite the popularity and efficacy of knowledge distillation, there is limited understanding of why it helps. In order to study the generalization behavior of a distilled student, we propose a new theoretical framework that leverages supervision complexity: a measure of alignment between teacher-provided supervision and the student's neural tangent kernel. The framework highlights a delicate interplay among the teacher's accuracy, the student's margin with respect to the teacher predictions, and the complexity of the teacher predictions. Specifically, it provides a rigorous justification for the utility of various techniques that are prevalent in the context of distillation, such as early stopping and temperature scaling. Our analysis further suggests the use of online distillation, where a student receives increasingly more complex supervision from teachers in different stages of their training. We demonstrate efficacy of online distillation and validate the theoretical findings on a range of image classification benchmarks and model architectures.
Formal limitations of sample-wise information-theoretic generalization bounds
May 13, 2022Some of the tightest information-theoretic generalization bounds depend on the average information between the learned hypothesis and a \emph{single} training example. However, these sample-wise bounds were derived only for \emph{expected} generalization gap. We show that even for expected \emph{squared} generalization gap no such sample-wise information-theoretic bounds exist. The same is true for PAC-Bayes and single-draw bounds. Remarkably, PAC-Bayes, single-draw and expected squared generalization gap bounds that depend on information in pairs of examples exist.