 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Soup: Model Merging for Text-to-Image Diffusion Models
Jun 12, 2024



We present Diffusion Soup, a compartmentalization method for Text-to-Image Generation that averages the weights of diffusion models trained on sharded data. By construction, our approach enables training-free continual learning and unlearning with no additional memory or inference costs, since models corresponding to data shards can be added or removed by re-averaging. We show that Diffusion Soup samples from a point in weight space that approximates the geometric mean of the distributions of constituent datasets, which offers anti-memorization guarantees and enables zero-shot style mixing. Empirically, Diffusion Soup outperforms a paragon model trained on the union of all data shards and achieves a 30% improvement in Image Reward (.34 $\to$ .44) on domain sharded data, and a 59% improvement in IR (.37 $\to$ .59) on aesthetic data. In both cases, souping also prevails in TIFA score (respectively, 85.5 $\to$ 86.5 and 85.6 $\to$ 86.8). We demonstrate robust unlearning -- removing any individual domain shard only lowers performance by 1% in IR (.45 $\to$ .44) -- and validate our theoretical insights on anti-memorization using real data. Finally, we showcase Diffusion Soup's ability to blend the distinct styles of models finetuned on different shards, resulting in the zero-shot generation of hybrid styles.
A Meta-Learning Approach to Predicting Performance and Data Requirements
Mar 02, 2023We propose an approach to estimate the number of samples required for a model to reach a target performance. We find that the power law, the de facto principle to estimate model performance, leads to large error when using a small dataset (e.g., 5 samples per class) for extrapolation. This is because the log-performance error against the log-dataset size follows a nonlinear progression in the few-shot regime followed by a linear progression in the high-shot regime. We introduce a novel piecewise power law (PPL) that handles the two data regimes differently. To estimate the parameters of the PPL, we introduce a random forest regressor trained via meta learning that generalizes across classification/detection tasks, ResNet/ViT based architectures, and random/pre-trained initializations. The PPL improves the performance estimation on average by 37% across 16 classification and 33% across 10 detection datasets, compared to the power law. We further extend the PPL to provide a confidence bound and use it to limit the prediction horizon that reduces over-estimation of data by 76% on classification and 91% on detection datasets.
ComplETR: Reducing the cost of annotations for object detection in dense scenes with vision transformers
Sep 13, 2022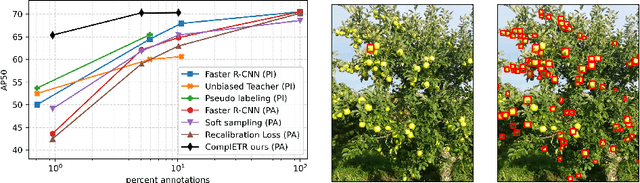
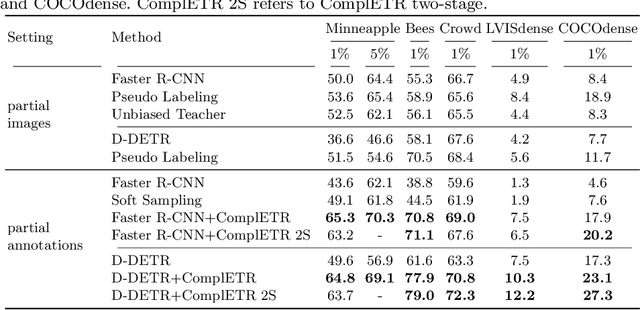
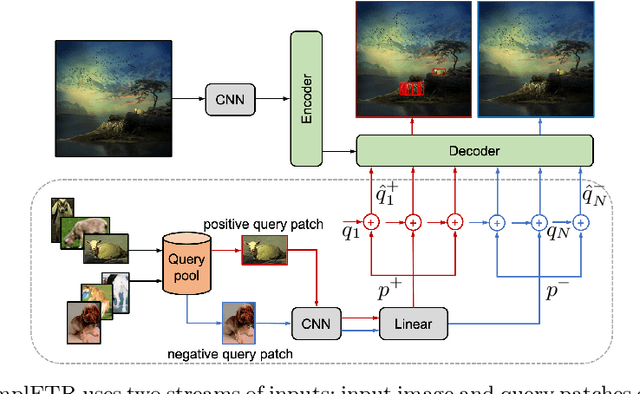
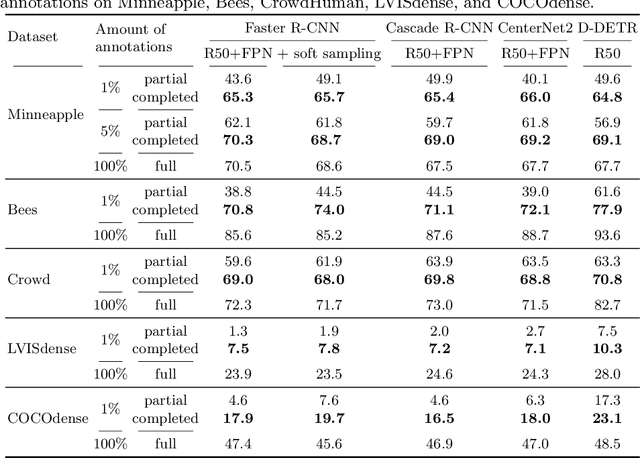
Annotating bounding boxes for object detection is expensive, time-consuming, and error-prone. In this work, we propose a DETR based framework called ComplETR that is designed to explicitly complete missing annotations in partially annotated dense scene datasets. This reduces the need to annotate every object instance in the scene thereby reducing annotation cost. ComplETR augments object queries in DETR decoder with patch information of objects in the image. Combined with a matching loss, it can effectively find objects that are similar to the input patch and complete the missing annotations. We show that our framework outperforms the state-of-the-art methods such as Soft Sampling and Unbiased Teacher by itself, while at the same time can be used in conjunction with these methods to further improve their performance. Our framework is also agnostic to the choice of the downstream object detectors; we show performance improvement for several popular detectors such as Faster R-CNN, Cascade R-CNN, CenterNet2, and Deformable DETR on multiple dense scene datasets.
BayesRace: Learning to race autonomously using prior experience
May 10, 2020
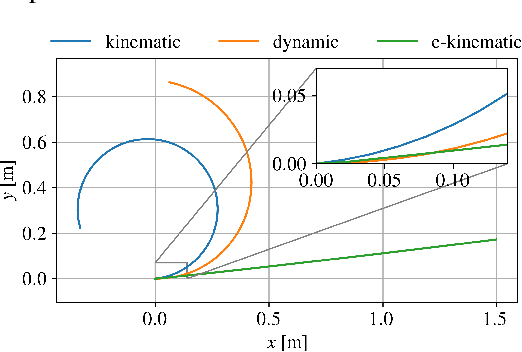
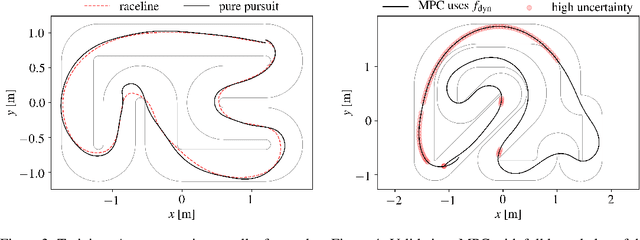
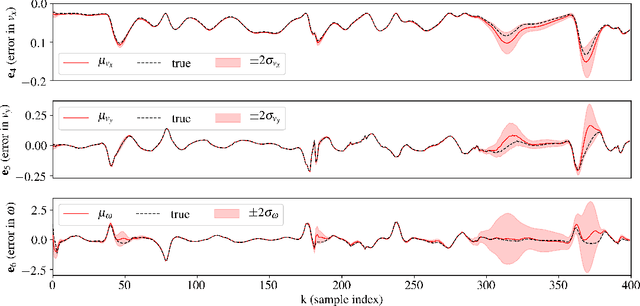
Learning to race autonomously is a challenging problem. It requires perception, estimation, planning, and control to work together in synchronization while driving at the limit of a vehicle's handling capability. Among others, one of the fundamental challenges lies in predicting the vehicle's future states like position, orientation, and speed with high accuracy because it is inevitably hard to identify vehicle model parameters that capture its real nonlinear dynamics in the presence of lateral tire slip. We present a model-based planning and control framework for autonomous racing that significantly reduces the effort required in system identification. Our approach bridges the gap between the design in a simulation and the real world by learning from on-board sensor measurements. Thus, the teams participating in autonomous racing competitions can start racing on new tracks without having to worry about tuning the vehicle model.
Computing the racing line using Bayesian optimization
Feb 12, 2020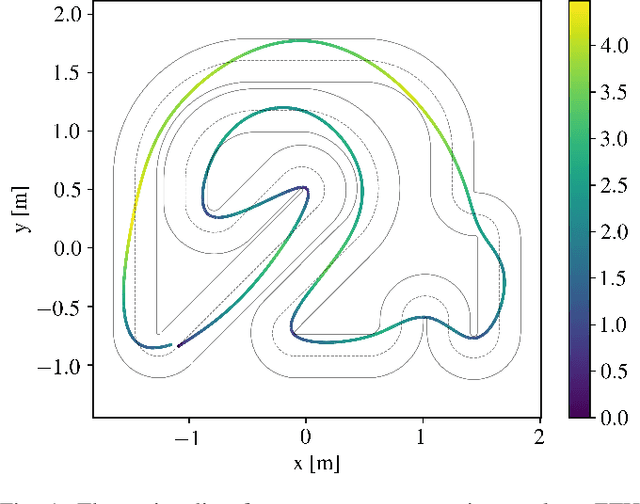
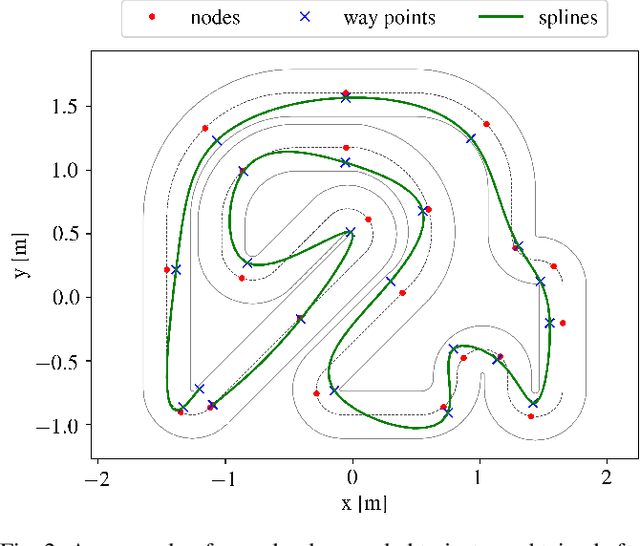
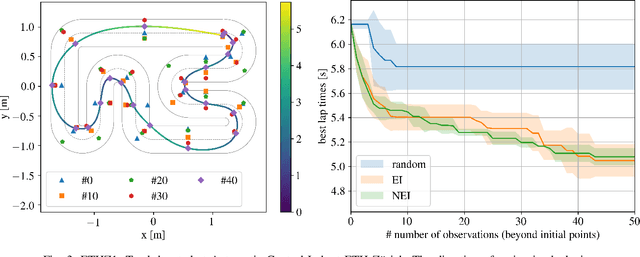
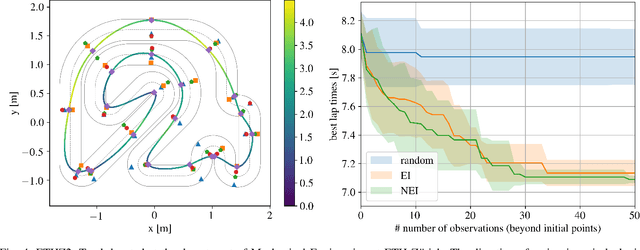
A good racing strategy and in particular the racing line is decisive to winning races in Formula 1, MotoGP, and other forms of motor racing. The racing line defines the path followed around a track as well as the optimal speed profile along the path. The objective is to minimize lap time by driving the vehicle at the limits of friction and handling capability. The solution naturally depends upon the geometry of the track and vehicle dynamics. We introduce a novel method to compute the racing line using Bayesian optimization. Our approach is fully data-driven and computationally more efficient compared to other methods based on dynamic programming and random search. The approach is specifically relevant in autonomous racing where teams can quickly compute the racing line for a new track and then exploit this information in the design of a motion planner and a controller to optimize real-time performance.
NeurOpt: Neural network based optimization for building energy management and climate control
Jan 22, 2020
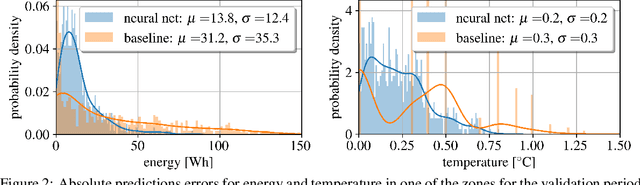
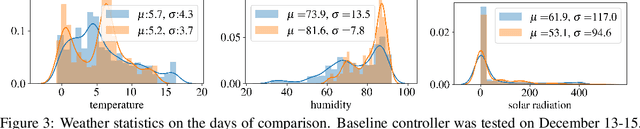
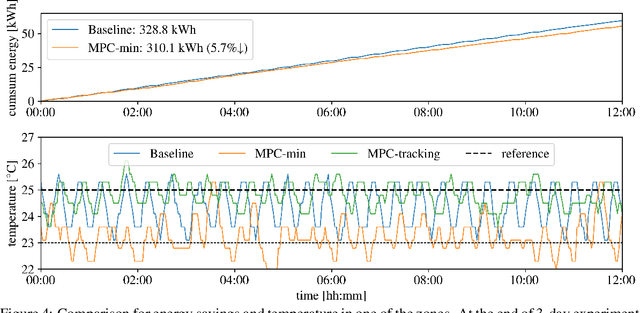
Model predictive control (MPC) can provide significant energy cost savings in building operations in the form of energy-efficient control with better occupant comfort, lower peak demand charges, and risk-free participation in demand response. However, the engineering effort required to obtain physics-based models of buildings for MPC is considered to be the biggest bottleneck in making MPC scalable to real buildings. In this paper, we propose a data-driven control algorithm based on neural networks to reduce this cost of model identification. Our approach does not require building domain expertise or retrofitting of the existing heating and cooling systems. We validate our learning and control algorithms on a two-story building with 10 independently controlled zones, located in Italy. We learn dynamical models of energy consumption and zone temperatures with high accuracy and demonstrate energy savings and better occupant comfort compared to the default system controller.